double-array-trie双数组trie树原理解析和数据构建过程
本文主要是对double-array实际实现时的一些概念和逻辑进行自己的解释, 有误请指点. [email protected]
trie树的作用
常用的高效查询检索数据结构
double-array用途: 文本分词, 模糊匹配检索, 精确匹配检索
triple-array-trie 三数组trie树
网上很多资料, 可以自己搜索, 基本原理的介绍不是本文的重点
http://blog.jqian.net/post/trie.html
本文也是建立在你已经了解了基本原理的基础上, 所以请首先了解下上面的内容, 或者如下原文:
http://linux.thai.net/~thep/datrie/datrie.html
double-array双数组trie树
double-array是由 triple-array 进行空间压缩和优化得来的, 那么是基于什么原理分析出三数组可以压缩为双数组的呢?
核心概念解释
不管是 算法原理还是具体实际编程实现的时候都涉及到几个概念
* 数据如何表示: 要构建的数据被分割为多个字符, 比如 a-z, 每个字符都进行数据编号, 这个编号就是作为寻找内存空间时的增量偏移来使用, 不同的字符编号不同
* 中文如何表示: 理论上中文可以用穷举的方式进行编号, 比如1-65535, 但是实际上一个中文字符是被当做两个字节看待的, 这样就可以把中文的字符编码降维到 ascii码的数量级 也就是说中文的编码其实就是用字节的ascii码来代替的, 这样对双字节字符的拆分不会影响其检索时的准确问题和召回问题, [体会工业实现的妙处吧]
* base数组: base数组的 "下标" 就是有限状态机里的状态标号; base[i] 位置存储的数值 是状态i的偏移基址, 偏移基址是用于该状态转移到后续状态时寻找合适的可用内存空间使用的.
* next数组: 存储的是当前状态经过某个输入转移后的状态, 比如 a接收c到达另外一个状态, 那么 next[ ad基址偏移 + code(c) ] = 状态c
* check数组: 是检查某个状态的前一个状态是什么.
* 基址偏移: 这个算法的重点是理解 base数组里存储的值的含义, 也就是当前状态的基址偏移, 基址偏移是表示当前状态在接受后续输入时寻找转移状态的一个基准.
也就是说后续状态的位置 = 基址偏移 + 输入编码 , 而输入编码是永远不会改变和调整的, 出现冲突的时候只能调整基址偏移来寻找合适的位置.
double-array构建过程
1. 初始状态

2. 第一步构建

3. 第二步构建

4. 第三步构建, 解决冲突

5. 后续构建
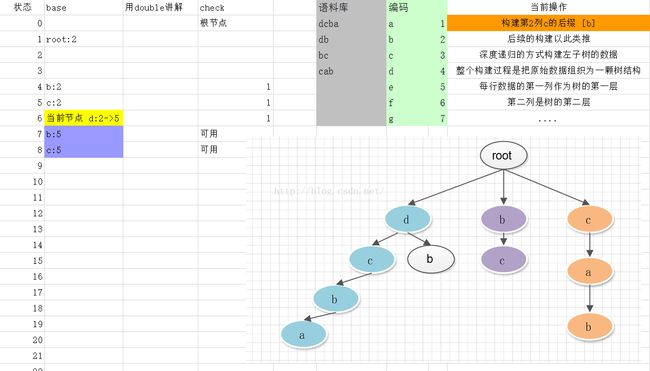
关于构建过程
为什么是按列构建
首先按行构建会遇到比较复杂的问题, 比如构建完dcba后, 接着要构建db, 那么遇到有冲突的时候就需要调整之前已经构建过的节点d的基础偏移, 同时也需要同步调整已经构建过的 dcba中d后面的cba的位置, 实现起来很是复杂.
也就是说如果调整冲突不需要修改当前状态的后续状态, 那么就没有那么复杂了
而这样的需求正好是按列 (也即按状态的深度) 来构建比较容易实现的.
换句话说按列构建数据, 也就是按状态机的状态深度构建, 这样每次构建的都是当前状态机的叶子节点, 不会出现调整现有节点的情况
为什么使用树
和上面的原因类似, 按深度构建的时候需要用递归和栈的原理来实现, 而树结构很自然的具备递归和栈的特性.
树结构只是在构建数据的时候使用的辅助数据结构,
构建完毕后树就可以销毁了, 检索的时候也不需要树的结构了