JStorm之Topology调度
topology在服务端提交过程中,会经过一系列的验证和初始化:TP结构校验、创建本地目录并拷贝序列化文件jar包、生成znode用于存放TP和task等信息,最后一步才进行任务分配,如下图:
提交主函数位于ServiceHandler.java中
这其中最主要的是事件丢入队列后后续的处理过程,事件分配由TopologyAssign线程处理,这个线程的流程很清晰,监听事件队列,一旦有事件进入,马上取出,进行doTopologyAssignment,如下:
任务分配的核心代码位于TopologyAssign.java中
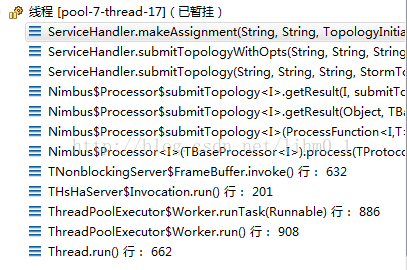
调用栈如下:

分配原理是首先获得所有可用的supervisor,判断supervisor可用的标准是是否有空闲的slot,也就是是否所有supervisor.slots.ports指定端口都被占用,然后计算出需要分配几个woker,因为一个woker对应一个端口,当然这些信息的采集都是来自Zookeeper,现在我们来分析分配的核心代码:
WorkerMaker.java
//注意参数,result是这个作业需要的槽位,传入前只知道需要槽位的数量,具体分配到哪台supervisor上还没指定
//supervisors指当前集群中所有可用的supervisor,即有空闲端口的
从上面的代码中我们可以看到,目前槽位分配没考虑机器负载,槽位的分配并不一定平均,比如第一个supervisor有10个槽位,剩下的supervisor只有两个,那么还是要每个supervisor分配一个woker的。注意一个问题,在上面代码中supervisors这个集合是经过排序的,排序规则如下:
提交主函数位于ServiceHandler.java中
private void makeAssignment(String topologyName, String topologyId,
TopologyInitialStatus status) throws FailedAssignTopologyException {
//1、创建topology的分配事件
TopologyAssignEvent assignEvent = new TopologyAssignEvent();
assignEvent.setTopologyId(topologyId);
assignEvent.setScratch(false);
assignEvent.setTopologyName(topologyName);
assignEvent.setOldStatus(Thrift
.topologyInitialStatusToStormStatus(status));
//2、丢入事件处理队列
TopologyAssign.push(assignEvent);
//3、等待时间返回
boolean isSuccess = assignEvent.waitFinish();
if (isSuccess == true) {
LOG.info("Finish submit for " + topologyName);
} else {
throw new FailedAssignTopologyException(
assignEvent.getErrorMsg());
}
}
这其中最主要的是事件丢入队列后后续的处理过程,事件分配由TopologyAssign线程处理,这个线程的流程很清晰,监听事件队列,一旦有事件进入,马上取出,进行doTopologyAssignment,如下:
public void run() {
LOG.info("TopologyAssign thread has been started");
runFlag = true;
while (runFlag) {
TopologyAssignEvent event;
try {
event = queue.take();
} catch (InterruptedException e1) {
continue;
}
if (event == null) {
continue;
}
boolean isSuccess = doTopologyAssignment(event);
..............
}
任务分配的核心代码位于TopologyAssign.java中
public Assignment mkAssignment(TopologyAssignEvent event) throws Exception {
String topologyId = event.getTopologyId();
LOG.info("Determining assignment for " + topologyId);
TopologyAssignContext context = prepareTopologyAssign(event);
Set<ResourceWorkerSlot> assignments = null;
if (!StormConfig.local_mode(nimbusData.getConf())) {
IToplogyScheduler scheduler = schedulers
.get(DEFAULT_SCHEDULER_NAME);
//开始进行作业的调度
assignments = scheduler.assignTasks(context);
} else {
assignments = mkLocalAssignment(context);
}
............
}
调用栈如下:
分配原理是首先获得所有可用的supervisor,判断supervisor可用的标准是是否有空闲的slot,也就是是否所有supervisor.slots.ports指定端口都被占用,然后计算出需要分配几个woker,因为一个woker对应一个端口,当然这些信息的采集都是来自Zookeeper,现在我们来分析分配的核心代码:
WorkerMaker.java
//注意参数,result是这个作业需要的槽位,传入前只知道需要槽位的数量,具体分配到哪台supervisor上还没指定
//supervisors指当前集群中所有可用的supervisor,即有空闲端口的
private void putWorkerToSupervisor(List<ResourceWorkerSlot> result,
List<SupervisorInfo> supervisors) {
int key = 0;
//按所需槽位遍历,每次分配一个
for (ResourceWorkerSlot worker : result) {
//首先进行必要的判断和置位
if (supervisors.size() == 0)
return;
if (worker.getNodeId() != null)
continue;
if (key >= supervisors.size())
key = 0;
//1、取出第一个supervisor
SupervisorInfo supervisor = supervisors.get(key);
worker.setHostname(supervisor.getHostName());
worker.setNodeId(supervisor.getSupervisorId());
worker.setPort(supervisor.getWorkerPorts().iterator().next());
//槽位用完则从集合中删除,不再参与分配
supervisor.getWorkerPorts().remove(worker.getPort());
if (supervisor.getWorkerPorts().size() == 0)
supervisors.remove(supervisor);
//当一个supervisor分配完后便不再使用,除非supervisor不够用
key++;
}
}
从上面的代码中我们可以看到,目前槽位分配没考虑机器负载,槽位的分配并不一定平均,比如第一个supervisor有10个槽位,剩下的supervisor只有两个,那么还是要每个supervisor分配一个woker的。注意一个问题,在上面代码中supervisors这个集合是经过排序的,排序规则如下:
private void putAllWorkerToSupervisor(List<ResourceWorkerSlot> result,
List<SupervisorInfo> supervisors) {
...........
supervisors = this.getCanUseSupervisors(supervisors);
Collections.sort(supervisors, new Comparator<SupervisorInfo>() {
@Override
public int compare(SupervisorInfo o1, SupervisorInfo o2) {
// TODO Auto-generated method stub
return -NumberUtils.compare(o1.getWorkerPorts().size(), o2
.getWorkerPorts().size());
}
});
this.putWorkerToSupervisor(result, supervisors);
.............
}可以看到,当前排序规则是按slot多少的,我们后续版本中可能会考虑机器负载的一些因素吧。