算法导论第十八章 B树
一、高级数据结构
本章以后到第21章(并查集)隶属于高级数据结构的内容。前面还留了两章:贪心算法和摊还分析,打算后面再来补充。之前的章节讨论的支持动态数据集上的操作,如查找、插入、删除等都是基于简单的线性表、链表和树等结构,本章以后的部分在原来更高的层次上来讨论这些操作,更高的层次意味着更复杂的结构,但更低的时间复杂度(包括摊还时间)。
- B树是为磁盘存储还专门设计的平衡查找树。因为磁盘操作的速度要远远慢于内存,所以度量B树的性能,不仅要考虑动态集合操作消耗了多少计算时间,还要考虑这些操作执行了多少次磁盘存储。因此,B树被设计成尽量减少磁盘访问的次数。知道了这一点,就会明白B树的变形B+树了,B+树通过将数据存储在叶子节点从而增大了一个节点所包含的信息,进而更加减少了磁盘的访问次数。
- 可合并堆:支持make-heap, insert, minimum, extract-min, union这5种操作。在堆排序章节讨论过二叉堆,除了union操作,二叉堆的性能都很好。该部分讨论的二项堆和斐波那契堆对union操作能够获得很好的性能,此外,对于其他操作,也能获得较好的改进。
- 该部分提出一种数据结构:van Emde Boas树,当关键字在有限范围内的整数时,进一步改进了动态集合操作的性能,可以在O(lglgu)时间内完成。
- 不相交集合(并查集):通过一棵简单的有根树来表示每个集合,就可以得到惊人的快速操作:一个由m个操作构成的序列的运行时间为O(n&(n)),而对于宇宙中的原子数总和n,&(n)也<=4,所以可以认为实际时间是O(n)。
二、B树
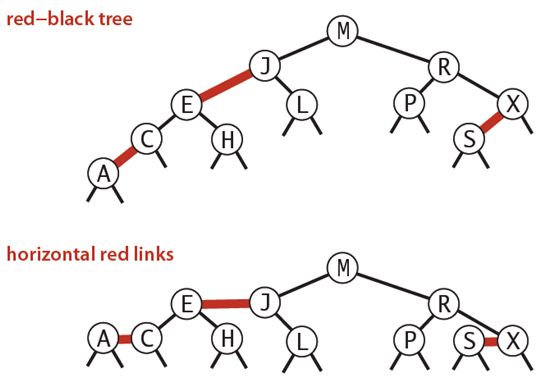
从历史演进上来看,B树是在2-3树的基础上演变而来,2-3树是一种类型的平衡查找树,AVL树的平衡条件是“保证任意节点的左右子树的高度差不超过1”,而红黑树则是“通过对节点着不同的颜色来约束平衡”,2-3树则是“通过约束内部节点的度来达到平衡”:分为普通两个度的节点和三个度的节点,故名为2-3树,如下图所示:

更深一步,从实现原理上看,红黑树是2-3树的一种简单实现,原因在于2-3树在编码实现上比较复杂,且失去二叉树的特性,不易被人接受和理解。如果稍加对2-3树做一点转换,就可以变为二叉树,做法是:用两种连线来区分度为3和度为2的节点,比如用红色的线来连接度为3的节点,黑色的线连接普通的节点,以这种方法,即可将2-3树转化为红黑树。如下:
2-3树是将内部节点赋予2-3度来达到平衡,那更一般地,自然想到为内部节点赋予更大大小的度,进而减小了树的高度,应对更多不同的场景。从这个层面上看,B树是在前人的基础上应运而生的一种树结构。
从应用场景来看,在一些大规模的数据存储中,如数据库,分布式系统等,实现索引查询这样一个实际背景下,数据的访问经常需要进行磁盘的读写操作,这个时候的瓶颈主要就在于磁盘的I/O上。如果采用普通的二叉查找树结构,由于树的深度过大,会造成磁盘I/O的读写过于频繁,进而导致访问效率低下(一般树的一个节点对应一个磁盘的页面,读取一次磁盘页相当于访问无数次内存)。那么,如何减少树的深度,一个基本的、很自然的想法就是:采用多叉树结构。节点的分支因子越大(可以理解成节点的孩子节点数),树的高度也就越低,从而查询的效率也就越高。从这个意义上来看,就有了B树的结构。
前面提到过,在大多数系统中,B树算法的运行时间主要由它所执行的disk-read和disk-write操作的次数所决定的,其余时间在内存中计算,速度不在一个量级。因此,应该有效地使用这两种操作,即让它们读取更多的信息以更少的次数。由于这个原因,在B树中,一个节点的大小通常相当于一个完整的磁盘页。因此,一个B树节点可以拥有的孩子数就由磁盘页的大小决定。理论上说,孩子数越多越好,因为这样树的高度会减少,查询效率会增加,但要保证一个节点的总大小不能大于磁盘中的一个页的大小,否则在一个节点内操作时还要来回访问内存,反而拖慢效率。
三、B树的定义及动态集合操作
一棵B树具有以下的性质:
1)每个节点x有三个属性:
a、x.n—>关键字个数
b、关键字递增排序
c、x.leaf—>节点是否属于叶子节点
2)每个节点有x.n+1个孩子节点
3)每个节点关键字 > 其左孩子节点 < 其右孩子节点
4)每个叶子节点具有相同的深度,即树的高度h。
5)每个节点用最小度数 t 来表示其关键字个数的上下界,或者孩子节点(分支因子)的个数的上下界。一般,每个非根节点中所包含的关键字个数 j 满足:
t-1 <= j <= 2*t - 1
根节点至少包括一个关键字,若非叶子节点,则至少两个分子,即 t>= 2。
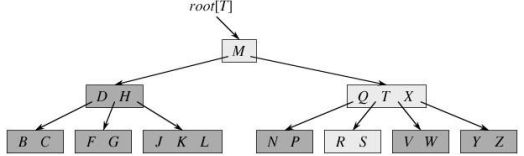
与红黑树相比,虽然两者的高度都以 O(lgn)的速度增长,但对于 B 树来说底要大很多倍。对大多数的树的操作来说,要查找的结点数在 B 树中要比红黑树中少大约 lgt 的因子。因为在树中查找任意一个结点通常需要一次磁盘存取,所以磁盘存取的次数大大的减少了。
以下代码表示B树中的一个节点:
1 /// B树中的一个结点 2 struct BTreeNode 3 { 4 vector<int> Keys; 5 vector<BTreeNode *> Childs; 6 BTreeNode *Parent;///< 父结点。当该结点是树的根结点时,Parent结点为nullptr 7 bool IsLeaf; ///< 是否为叶子结点 8 9 BTreeNode() : Parent( nullptr ), IsLeaf( true ) {} 10 11 size_t KeysSize() 12 { 13 return Keys.size(); 14 } 15 };
关于B树的动态集合操作,就不一一述说了,《算法导论》书已经讲得非常清楚了,而且图文并茂,照着认真看,绝对是没问题的。下面是实现的代码:
#ifndef _B_TREE_H_ #define _B_TREE_H_ #include <iostream> #include <algorithm> #include <vector> #include <string> #include <sstream> #include <cassert> using namespace std; class BTree { public: /// B树中的一个结点 struct BTreeNode { vector<int> Keys; vector<BTreeNode *> Childs; BTreeNode *Parent; ///< 父结点。当该结点是树的根结点时,Parent结点为nullptr bool IsLeaf; ///< 是否为叶子结点 BTreeNode() : Parent( nullptr ), IsLeaf( true ) {} size_t KeysSize() { return Keys.size(); } }; /// 构造一棵最小度为t的B树(t>=2) BTree( int t ) : _root( nullptr ), _t( t ) { assert( t >= 2 ); } ~BTree() { _ReleaseNode( _root ); } /// @brief B树的查找操作 /// /// 在B-树中查找给定关键字的方法类似于二叉排序树上的查找。 /// 不同的是在每个结点上确定向下查找的路径不一定是二路而是keynum+1路的。\n /// 实现起来还是相当容易的! pair<BTreeNode *, size_t> Search( int key ) { return _SearchInNode( _root, key ); } /// @brief 插入一个值的操作 /// /// 这里没有使用《算法导论》里介绍的一趟的方法,而是自己想象出来的二趟的方法 /// 效率肯定不如书上介绍的一趟优美,但是能解决问题。\n /// 因为插入操作肯定是在叶子结点上进行的,首先顺着书向下走直到要进行插入操作的叶子结点将新值插入到该叶子结点中去. /// 如果因为这个插入操作而使用该结点的值的个数>2*t-1的上界,就需要递归向上进行分裂操作。 /// 如果分裂到了根结点,还要处理树长高的情况。\n bool Insert( int new_key ) { if ( _root == nullptr ) //空树 { _root = new BTreeNode(); _root->IsLeaf = true; _root->Keys.push_back( new_key ); return true; } if ( Search( new_key ).first == nullptr ) //是否已经存在该结点 { BTreeNode *node = _root; while ( !node->IsLeaf ) { int index = 0; while ( index < node->Keys.size() && new_key >= node->Keys[index] ) { ++index; } node = node->Childs[index]; } //插入到Keys里去 node->Keys.insert( find_if( node->Keys.begin(), node->Keys.end(), bind2nd( greater<int>(), new_key ) ), new_key ); //再递归向上处理结点太大的情况 while ( node->KeysSize() > 2 * _t - 1 ) { //=====开始分裂====== int prove_node_key = node->Keys[node->KeysSize() / 2 - 1]; // 要提升的结点的key //后半部分成为一个新节点 BTreeNode *new_node = new BTreeNode(); new_node->IsLeaf = node->IsLeaf; new_node->Keys.insert( new_node->Keys.begin(), node->Keys.begin() + node->KeysSize() / 2, node->Keys.end() ); new_node->Childs.insert( new_node->Childs.begin(), node->Childs.begin() + node->Childs.size() / 2, node->Childs.end() ); assert( new_node->Childs.empty() || new_node->Childs.size() == new_node->Keys.size() + 1 ); for_each( new_node->Childs.begin(), new_node->Childs.end(), [&]( BTreeNode * c ) { c->Parent = new_node; } ); //把后半部分从原来的节点中删除 node->Keys.erase( node->Keys.begin() + node->KeysSize() / 2 - 1, node->Keys.end() ); node->Childs.erase( node->Childs.begin() + node->Childs.size() / 2, node->Childs.end() ); assert( node->Childs.empty() || node->Childs.size() == node->Keys.size() + 1 ); BTreeNode *parent_node = node->Parent; if ( parent_node == nullptr ) //分裂到了根结点,树要长高了,需要NEW一个结点出来 { parent_node = new BTreeNode(); parent_node->IsLeaf = false; parent_node->Childs.push_back( node ); _root = parent_node; } node->Parent = new_node->Parent = parent_node; auto insert_pos = find_if( parent_node->Keys.begin(), parent_node->Keys.end(), bind2nd( greater<int>(), prove_node_key ) ) - parent_node->Keys.begin(); parent_node->Keys.insert( parent_node->Keys.begin() + insert_pos, prove_node_key ); parent_node->Childs.insert( parent_node->Childs.begin() + insert_pos + 1, new_node ); node = parent_node; } return true; } return false; } /// @brief 删除一个结点的操作 bool Delete( int key_to_del ) { auto found_node = Search( key_to_del ); if ( found_node.first == nullptr ) //找不到值为key_to_del的结点 { return false; } if ( !found_node.first->IsLeaf ) //当要删除的结点不是叶子结点时用它的前驱来替换,再删除它的前驱 { //前驱 BTreeNode *previous_node = found_node.first->Childs[found_node.second]; while ( !previous_node->IsLeaf ) { previous_node = previous_node->Childs[previous_node->Childs.size() - 1]; } //替换 found_node.first->Keys[found_node.second] = previous_node->Keys[previous_node->Keys.size() - 1]; found_node.first = previous_node; found_node.second = previous_node->Keys.size() - 1; } //到这里,found_node一定是叶子结点 assert( found_node.first->IsLeaf ); _DeleteLeafNode( found_node.first, found_node.second ); return true; } private: void _ReleaseNode( BTreeNode *node ) { for_each( node->Childs.begin(), node->Childs.end(), [&]( BTreeNode * c ) { _ReleaseNode( c ); } ); delete node; } /// @brief 删除B树中的一个叶子结点 /// /// @param node 要删除的叶子结点! /// @param index 要删除的叶子结点上的第几个值 /// @note 必须保证传入的node结点为叶子结点 void _DeleteLeafNode( BTreeNode *node, size_t index ) { assert( node && node->IsLeaf ); if ( node == _root ) { //要删除的值在根结点上,并且此时根结点也是叶子结点,因为本方法被调用时要保证node参数是叶子结点 _root->Keys.erase( _root->Keys.begin() + index ); if ( _root->Keys.empty() ) { //成为了一棵空B树 delete _root; _root = nullptr; } return; } //以下是非根结点的情况 if ( node->Keys.size() > _t - 1 ) { //要删除的结点中Key的数目>t-1,因此再-1也不会打破B树的性质 node->Keys.erase( node->Keys.begin() + index ); } else //会打破平衡 { //是否借到了一个顶点 bool borrowed = false; //试着从左兄弟借一个结点 BTreeNode *left_brother = _GetLeftBrother( node ); if ( left_brother && left_brother->Keys.size() > _t - 1 ) { int index_in_parent = _GetIndexInParent( left_brother ); BTreeNode *parent = node->Parent; node->Keys.insert( node->Keys.begin(), parent->Keys[index_in_parent] ); parent->Keys[index_in_parent] = left_brother->Keys[left_brother->KeysSize() - 1]; left_brother->Keys.erase( left_brother->Keys.end() - 1 ); ++index; borrowed = true; } else { //当左兄弟借不到时,试着从右兄弟借一个结点 BTreeNode *right_brother = _GetRightBrother( node ); if ( right_brother && right_brother->Keys.size() > _t - 1 ) { int index_in_parent = _GetIndexInParent( node ); BTreeNode *parent = node->Parent; node->Keys.push_back( parent->Keys[index_in_parent] ); parent->Keys[index_in_parent] = right_brother->Keys[0]; right_brother->Keys.erase( right_brother->Keys.begin() ); borrowed = true; } } if ( borrowed ) { //因为借到了结点,所以可以直接删除结点 _DeleteLeafNode( node, index ); } else { //左右都借不到时先删除再合并 node->Keys.erase( node->Keys.begin() + index ); _UnionNodes( node ); } } } /// @brief node找一个相邻的结点进行合并 /// /// 优先选取左兄弟结点,再次就选择右兄弟结点 void _UnionNodes( BTreeNode * node ) { if ( node ) { if ( node == _root ) //node是头结点 { if ( _root->Keys.empty() ) { //头结点向下移动一级,此时树的高度-1 _root = _root->Childs[0]; _root->Parent = nullptr; delete node; return; } } else { if ( node->KeysSize() < _t - 1 ) { BTreeNode *left_brother = _GetLeftBrother( node ); if ( left_brother == nullptr ) { left_brother = _GetRightBrother( node ); swap( node, left_brother ); } //与左兄弟进行合并 int index_in_parent = _GetIndexInParent( left_brother ); node->Keys.insert( node->Keys.begin(), node->Parent->Keys[index_in_parent] ); node->Parent->Keys.erase( node->Parent->Keys.begin() + index_in_parent ); node->Parent->Childs.erase( node->Parent->Childs.begin() + index_in_parent + 1 ); left_brother->Keys.insert( left_brother->Keys.end(), node->Keys.begin(), node->Keys.end() ); left_brother->Childs.insert( left_brother->Childs.begin(), node->Childs.begin(), node->Childs.end() ); for_each( left_brother->Childs.begin(), left_brother->Childs.end(), [&]( BTreeNode * c ) { c->Parent = left_brother; } ); delete node; _UnionNodes( left_brother->Parent ); } } } } pair<BTreeNode *, size_t> _SearchInNode( BTreeNode *node, int key ) { if ( !node ) { //未找到,树为空的情况 return make_pair( static_cast<BTreeNode *>( nullptr ), 0 ); } else { int index = 0; while ( index < node->Keys.size() && key >= node->Keys[index] ) { if ( key == node->Keys[index] ) { return make_pair( node, index ); } else { ++index; } } if ( node->IsLeaf ) { //已经找到根了,不能再向下了未找到 return make_pair( static_cast<BTreeNode *>( nullptr ), 0 ); } else { return _SearchInNode( node->Childs[index], key ); } } } void _GetDotLanguageViaNodeAndEdge( stringstream &ss, BTreeNode *node ) { if ( node && !node->Keys.empty() ) { int index = 0; ss << " node" << node->Keys[0] << "[label = \""; while ( index < node->Keys.size() ) { ss << "<f" << 2 * index << ">|"; ss << "<f" << 2 * index + 1 << ">" << node->Keys[index] << "|"; ++index; } ss << "<f" << 2 * index << ">\"];" << endl;; if ( !node->IsLeaf ) { for( int i = 0; i < node->Childs.size(); ++i ) { BTreeNode *c = node->Childs[i]; ss << " \"node" << node->Keys[0] << "\":f" << 2 * i << " -> \"node" << c->Keys[0] << "\":f" << ( 2 * c->Keys.size() + 1 ) / 2 << ";" << endl; } } for_each( node->Childs.begin(), node->Childs.end(), [&]( BTreeNode * c ) { _GetDotLanguageViaNodeAndEdge( ss, c ); } ); } } /// 得到一个结点的左兄弟结点,如果不存在左兄弟结点则返回nullptr BTreeNode * _GetLeftBrother( BTreeNode *node ) { if ( node && node->Parent ) { BTreeNode *parent = node->Parent; for ( int i = 1; i < parent->Childs.size(); ++i ) { if ( parent->Childs[i] == node ) { return parent->Childs[i - 1]; } } } return nullptr; } /// 得到一个结点的右兄弟结点,如果不存在右兄弟结点则返回nullptr BTreeNode * _GetRightBrother( BTreeNode *node ) { if ( node && node->Parent ) { BTreeNode *parent = node->Parent; for ( int i = 0; i < static_cast<int>( parent->Childs.size() ) - 1; ++i ) { if ( parent->Childs[i] == node ) { return parent->Childs[i + 1]; } } } return nullptr; } /// 得到一个结点在其父结点中属于第几个子结点 /// @return 返回-1时表示错误 int _GetIndexInParent( BTreeNode *node ) { assert( node && node->Parent ); for ( int i = 0; i < node->Parent->Childs.size(); ++i ) { if ( node->Parent->Childs[i] == node ) { return i; } } return -1; } BTreeNode *_root; ///< B树的根结点指针 int _t; ///< B树的 最小度数。即所有的结点的Keys的个数应该t-1 <= n <= 2t-1,除了根结点可以最少为1个Key }; #endif//_B_TREE_H_
四、B树的引申——B+树、B*树
B+树是对B树的一种变形树,它与B树的差异在于:
- 有k个子结点的结点必然有k个关键码;
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
B树和B+树各有优缺点:
- B+树的磁盘读写代价更低:B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一磁盘页中,那么一页所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
- 访问缓存命中率高:其一,B+树在内部节点上不含数据项,因此关键字存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据项也具有更好的缓存命中率;其二,B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
- B+树的查询效率更加稳定:由于非叶子节点只是充当叶子结点中数据项的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
当然,B树也不是因此就没有优点,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
由于B+树较好的访问性能,一般,B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引!
B*树则是在B+树的基础上,又新增了一项规定:内部节点新增指向兄弟节点的指针。另外,B*树定义了非叶子结点关键字个数至少为(2/3)*t,即块的最低使用率为2/3(代替B+树的1/2);B*树在分裂节点时,由于可以向空闲较多的兄弟节点进行转移,因此其空间利用率更高。