【Mapreduce】以逗号为分隔符的WordCount词频统计
对原有的WordCount程序进行小修小改。将原本以空格、回车识别单词的WordCount,改成以逗号、回车识别单词的WordCount。以说明Map/Redure到底在做一件什么事。
代码修改之后如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//Mapper处理类
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
//相当于int one=1;相当于int result;但在mapreducer中,放在context的整形,需要是IntWritable
private Text word = new Text();
//相当于string word="",相当于int result;但在mapreducer中,放在context的字符串,需要是Text
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(),",");
//itr是一个根据,分割之后,遍历分割之后的元素的游标,同:
//string[] temp=string.split(',');
//for(int itr=0;itr<temp.length;itr++)
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());//相当于string word=itr.nextToken()
context.write(word, one);
}
}
}
//Reducer处理类
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//相当于int result;但在mapreducer中,放在context的整形,需要是IntWritable
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);//相当于int result=sum
context.write(key, result);
}
}
//主函数,唯一需要修改的部分,就是指明Map/Reduce两个处理类
public static void main(String[] args) throws Exception {
//指定动作,必须有这几行代码
//初始化
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setMapperClass(TokenizerMapper.class);//指明Map处理类,关键
job.setReducerClass(IntSumReducer.class);//指明Reduce处理类,关键
//指明输出流
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//指明输入文件是刚刚接受的第0个参数
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//指明输入文件是刚刚接受的第1个参数
System.exit(job.waitForCompletion(true) ? 0 : 1);//提交任务,执行
//指定动作,必须有这几行代码
}
}
具体的原理如下图所示:
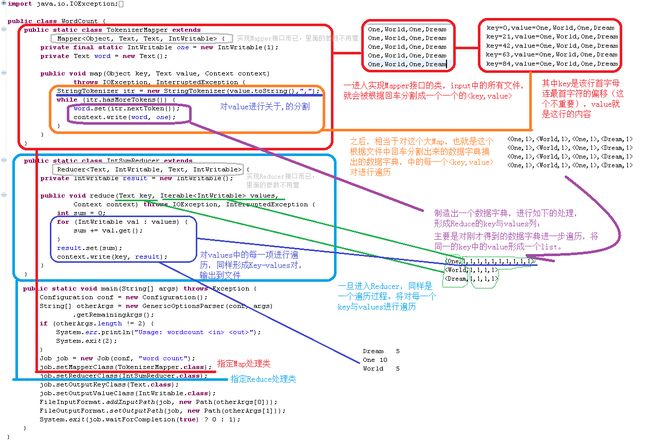
可以看到,我们程序猿如果需要进行Mapreduce其主要核心就是写好分割过程Map与合并过程Reduce。
Map、Reduce本身就是一个对数据字典遍历的过程。
而Mapreduce在开始,将输入文件,根据回车分成一个个value,在Map到Reduce中途做了一件将写入Context中Key值相同的项的value合并起来。这些都是一些自动完成的过程。当然,处理速度非常快,可以据此,作一些大数据的统计。