MySQL查询优化器源码分析
目的
基于之前出现的主从库分别执行相同语句,查询计划和执行时间不同的问题。通过对源代码跟踪和调试,对MySQL的查询优化器进行分析并编写文档,为开发人员和数据库管理人员提供查询SQL语句的建议。
基础
MySQL的设计架构在官方文档中给出,如下图所示。该图的具体描述和讲解,请参考官方文档或地址:http://dev.mysql.com/doc/refman/5.1/en/pluggable-storage-overview.html。
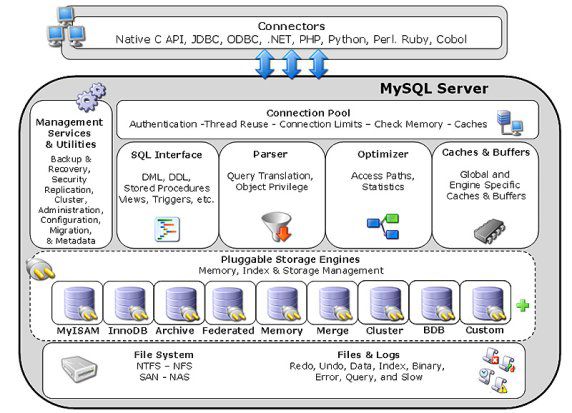
图中Optimizer部分为本文研究的重点,主要对Parser解析之后的SQL,根据统计的数据,对访问代价进行权衡,制定执行计划。查询优化器是MySQL中比较活跃的一部分,代码会经常变动。但整体而言,对查询优化器整体把握和理解之后,其他的版本也基本可以轻松理解。以下内容将通过对MySQL 5.5.20版本的源码进行分析,供大家参考。
代码分析
1、Parser阶段
查询优化器相关的代码主要在sql/sql_select.cc文件中,而在执行该部分代码时,需要对之前的内容做简要说明。本文从Parser阶段case SQLCOM_SELECT:中调用execute_sqlcom_select()函数开始(参看源码sql/sql_parse.cc:2124行),该函数是实际的sql执行阶段,而sql真正执行需要按照一定的规则去执行。因此,需要先制定一个执行计划。但制定计划不能随便制定,需要有一定的依据。并且不能保证所有人写的SQL都是最优的,也就不能根据SQL就简单制定一个规则。于是,出现了SQL Optimizer,该部分不仅对SQL进行了优化,并且根据优化的结果制定查询的执行计划。最终根据执行计划执行,得到数据结果并返回。从代码看,execute_sqlcom_select()函数做了以上的所有工作。
以下将从execute_sqlcom_select()函数开始,逐层次的分析MySQL的查询优化是如何实现的。
2、Optimizer阶段
execute_sqlcom_select()函数中,调用了handle_select()函数,而该函数正是处理SQL查询的“入口函数”。
2.1 函数调用层次
首先,将主要的函数调用层次列出,函数层次以之前的“|”标示,以“>”标示进入函数,以“<”标示退出函数,红色标示为递归调用的函数,绿色和蓝色标示为互斥操作。
| | | | | >handle_select | | | | | >mysql_select/mysql_union | | | | | | >JOIN::prepare | | | | | | | >setup_tables | | | | | | | <setup_tables | | | | | | | >setup_fields | | | | | | | <setup_fields | | | | | | | >setup_without_group | | | | | | | | >setup_conds | | | | | | | | <setup_conds | | | | | | | | >setup_order | | | | | | | | <setup_order | | | | | | | | >setup_group | | | | | | | | <setup_group | | | | | | | <setup_without_group | | | | | | | >setup_procedure | | | | | | | <setup_procedure | | | | | | <JOIN::prepare | | | | | | >JOIN::optimize | | | | | | | >simplify_joins | | | | | | | <simplify_joins | | | | | | | >build_bitmap_for_nested_joins | | | | | | | <build_bitmap_for_nested_joins | | | | | | | >optimize_cond | | | | | | | <optimize_cond | | | | | | | >prune_partitions | | | | | | | <prune_partitions | | | | | | | >make_join_statistics | | | | | | | | >make_select | | | | | | | | <make_select | | | | | | | | >get_quick_record_count | | | | | | | | | >SQL_SELECT::test_quick_select | | | | | | | | | | >get_mm_tree | | | | | | | | | | <get_mm_tree | | | | | | | | | | >get_best_group_min_max | | | | | | | | | | <get_best_group_min_max | | | | | | | | | | >get_key_scans_params | | | | | | | | | | <get_key_scans_params | | | | | | | | | | >get_best_ror_intersect | | | | | | | | | | <get_best_ror_intersect | | | | | | | | | | >get_best_disjunct_quick | | | | | | | | | | <get_best_disjunct_quick | | | | | | | | | | >TRP_RANGE::make_quick | | | | | | | | | | <TRP_RANGE::make_quick | | | | | | | | | <SQL_SELECT::test_quick_select | | | | | | | | <get_quick_record_count | | | | | | | | >choose_plan | | | | | | | | | >optimize_straight_join | | | | | | | | | | >best_access_path | | | | | | | | | | <best_access_path | | | | | | | | | <optimize_straight_join | | | | | | | | | >greedy_search | | | | | | | | | | >best_extension_by_limited_search | | | | | | | | | | | >best_access_path | | | | | | | | | | | <best_access_path | | | | | | | | | | <best_extension_by_limited_search | | | | | | | | | <greedy_search | | | | | | | | <choose_plan | | | | | | | <make_join_statistics | | | | | | | >get_best_combination | | | | | | | <get_best_combination | | | | | | | >make_join_select | | | | | | | <make_join_select | | | | | | <JOIN::optimize | | | | | | >JOIN::exec | | | | | | | >do_select | | | | | | | <do_select | | | | | | <JOIN::exec | | | | | | >st_select_lex::cleanup() | | | | | | <st_select_lex::cleanup() | | | | | <mysql_select/mysql_union | | | | <handle_select |
2.2 Optimizer流程图
通过以上的函数调用层次,对optimizer的处理流程图形化,方便清晰的理解和查看具体的流程。
由于函数调用层次不利于清晰的显示处理流程,因此以下流程图摒弃了调用层次的界限,更关注逻辑处理。
|
|

2.3 函数详细介绍
1)handle_select():(sql/sql_select.cc:265)
handle_select()函数用于执行查询操作。该函数对Union进行了判断,如果查询SQL中不包含union关键字,函数直接执行mysql_select()函数处理;否则,将执行mysql_union()函数。
2)mysql_select()/mysql_union():(sql/sql_select.cc:2498|sql/sql_union.cc:31)
mysql_select()函数是单个select查询的“入口函数”。该函数执行SQL优化的一些列操作。区别于mysql_select()函数,mysql_union()函数逐个执行union中单个select查询优化的一系列操作。执行SQL优化的过程调用相同的函数实现,仅在执行前期的处理过程不一致。
3) JOIN::prepare():(sql/sql_select.cc:499)
JOIN::prepare()函数用于为整个查询做准备工作。其中包括准备表、检查表是否可以访问、检查字段、检查非group函数、准备procedure等工作。以下是该过程调用的重要函数,具体查看响应函数的解释。
该函数简化后,并且忽略函数调用层次的流程图如下图所示:
|
|

4)setup_tables():(sql/sql_base.cc:7963)
setup_tables()函数用于准备查询所需要的所有表。该函数被setup_tables_and_check_access()函数(sql/sql_base.cc:8058)调用,而setup_tables_and_check_access()函数用于准备表以及检查表的是否可以访问,在JOIN::prepare()函数中被调用,而该函数分别调用setup_tables()和check_single_table_access(),其中后者对所有需要的表,循环进行检查是否可以访问。
5)setup_fields():(sql/sql_base.cc:7825)
setup_fields()函数用于检查所有给定字段是否存在。该函数检查所有查询中给定的数据表的字段,对数据表的列进行查找。其中调用了更深层次的函数,如下所示:find_field_in_tables() -> find_field_in_table_ref() ->find_field_in_table()。其中find_field_in_tables()根据查询的表,循环调用find_field_in_table_ref()函数。
6)setup_without_group():(sql/sql_select.cc:446)
setup_without_group()函数用于准备非group函数。该函数是一个内嵌函数,但是该函数的逻辑并不简单。该函数调用了setup_conds()、setup_order()、setup_group()函数,具体的函数解释见下面内容。
7) setup_conds():(sql/sql_base.cc:8379)
setup_conds()函数用于准备SQL查询中where的所有条件。该函数对where中给定的条件,检查对应数据表的字段。其中调用了find_field_in_table_ref()函数,用于检查数据表中的字段。
8) setup_order():(sql/sql_select.cc:14996)
setup_order()函数用于准备SQL查询中order by的条件。该函数对每个orderby字段都调用了find_order_in_list()函数,而find_order_in_list()用于处理group by和order by的字段。
9) setup_group():(sql/sql_select.cc:15037)
setup_group()函数用于初始化SQL查询中group by的条件。该函数同setup_order()的处理逻辑类似,不在赘述。
10) setup_procedure():(sql/procedure.cc:80)
setup_procedure()函数用于准备procedure处理。
注意:除以上函数调用外,JOIN::prepare()过程中如果存在orderby和group by的条件时,在调用以上函数之后,还有一系列操作,比如分配额外的隐藏字段、分离sum结果和item树等内容。
11) JOIN::optimize():(sql/sql_select.cc:854)
JOIN::optimize()是整个查询优化器的核心内容。查询优化主要对Join进行简化、优化where条件、优化having条件、裁剪分区partition(如果查询的表是分区表)、优化count()/min()/max()聚集函数、统计join的代价、搜索最优的join顺序、生成执行计划、执行基本的查询、优化多个等式谓词、执行join查询、优化distinct、创建临时表存储临时结果等操作。以下将对该过程调用的重要函数,进行详细的讲解。
该函数简化后的流程图如下图所示:
|
|

12) simplify_joins():(sql/sql_select.cc:8940)
simplify_joins()函数简化join操作。该函数将可以用内连接替换的外连接进行替换,并对嵌套join使用的表、非null表、依赖表等进行计算。该函数的实现是一个递归过程,在递归中,所有的特征将被计算,所有可以被替换的外连接被替换,所有不需要的括号也被去掉。此外,该函数前的注释中,给出了多个例子,用于解释外连接替换为内连接的一些特征。
| Sample 1: SELECT * FROM t1 LEFT JOIN t2 ON t2.a=t1.a WHERE t2.b < 5 ==> SELECT * FROM t1 INNER JOIN t2 ON t2.a=t1.a WHERE t2.b < 5 ==> SELECT * FROM t1, t2 ON t2.a=t1.a WHERE t2.b < 5 AND t2.a=t1.a Sample 2: SELECT * from t1 LEFT JOIN (t2, t3) ON t2.a=t1.a t3.b=t1.b WHERE t2.c < 5 ==> SELECT * FROM t1, (t2, t3) WHERE t2.c < 5 AND t2.a=t1.a t3.b=t1.b Sample 3: SELECT * FROM t1 LEFT JOIN t2 ON t2.a=t1.a LEFT JOIN t3 ON t3.b=t2.b WHERE t3 IS NOT NULL ==> SELECT * FROM t1 LEFT JOIN t2 ON t2.a=t1.a, t3 WHERE t3 IS NOT NULL AND t3.b=t2.b ==> SELECT * FROM t1, t2, t3 WHERE t3 IS NOT NULL AND t3.b=t2.b AND t2.a=t1.a |
13)build_bitmap_for_nested_joins():(sql/sql_select.cc:9135)
build_bitmap_for_nested_joins()函数为每个嵌套join在bitmap中分配一位。该函数也是一个递归过程,返回第一个没有使用的bit。
14)optimize_cond():(sql/sql_select.cc:9405)
optimize_cond()函数分别对where条件和having条件建立多个等价谓词,并且删除可以被推导出的等价谓词。该函数调用build_equal_items()函数(sql/sql_select.cc:8273)用于该处理过程,该函数是一个递归过程,并在函数前,列举了多个实例,供参考和理解。
| Sample 1: SELECT * FROM (t1,t2) LEFT JOIN (t3,t4) ON t1.a=t3.a AND t2.a=t4.a WHERE t1.a=t2.a; ==> SELECT * FROM (t1,t2) LEFT JOIN (t3,t4) ON multiple equality (t1.a,t2.a,t3.a,t4.a) Sample 2: SELECT * FROM (t1,t2) LEFT JOIN (t3,t4) ON t1.a=t3.a AND t3.a=t4.a WHERE t1.a=t2.a ==> SELECT * FROM (t1 LEFT JOIN (t3,t4) ON t1.a=t3.a AND t3.a=t4.a),t2 WHERE t1.a=t2.a Sample 3: SELECT * FROM (t1,t2) LEFT JOIN (t3,t4) ON t2.a=t4.a AND t3.a=t4.a WHERE t1.a=t2.a ==> SELECT * FROM (t2 LEFT JOIN (t3,t4)ON t2.a=t4.a AND t3.a=t4.a), t1 WHERE t1.a=t2.a |
此外,该函数调用propagate_cond_constants()函数(sql/sql_select.cc:8763),用于处理(a=b andb=1)为(a=1 and b=1)操作,该函数也是一个递归过程。调用remove_eq_conds()函数(sql/sql_select():9617),用于删除(a=a以及1=1、1=2)条件,该函数调用了internal_remove_eq_conds()递归处理函数(sql_select.cc:9462)。
15) prune_partitions():(sql/opt_range.cc:2611)
prune_partitions()函数通过分析查询条件,查找需要的数据分区。该函数仅对分区表有效,普通的表不做处理。
16) make_join_statistics():(sql/sql_select.cc:2651)
make_join_statistics()函数用于计算最好的join执行计划。该过程较复杂,分为以下几个步骤:
首先如果join是外连接,利用Floyd Warshall(弗洛伊德)算法建立传递闭包依赖关系,该过程较复杂,具体参考该算法的一些内容。
之后进行主键或唯一索引的常量查询处理,该过程是一个循环过程,与执行计划中的ref类型有关。
接下来,计算每个表中匹配的行数以及扫描的时间,该过程得到的结果是估计的值,并非实际查询需要的记录数和时间。并且调用了一下的make_select()函数和get_quick_recond_count()函数,具体内容参照以下相应函数的分析。该过程从生成执行计划来看,与index和full类型有关。
最后,根据以上统计的记录数和时间,选择一个最优的join顺序。实际该处理逻辑,调用choose_plan()函数处理,参照以下choose_plan()函数分析。
该函数简化后的流程图如下图所示:
|
|
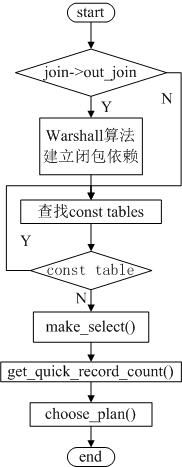
17)make_select():(sql/opt_range.cc:1067)
make_select()函数是普通查询和快速范围查询处理的函数。该函数通过计算查询记录在cache中的偏移量除以ref长度的商,得到查询的行数。如果cache中没有缓存,那么退出该过程,执行get_quick_record_count()函数处理过程。
18)get_quick_record_count():(sql/sql_select.cc:2602)
get_quick_record_count()函数用于估计查询需要每个表的记录数。该过程调用SQL_SELECT::test_quick_select()函数用于具体的处理逻辑,具体见以下函数的详细分析过程。
19) SQL_SELECT::test_quick_select():(sql/opt_range.cc:2149)
SQL_SELECT::test_quick_select()函数用于实际的处理估计范围查询需要的记录数和时间。从函数名和注释来看,该函数是用于检查范围查询中key是否可用,而从函数逻辑来看,该函数主要用于对范围查询进行处理。
处理逻辑有以下几步:
首先,根据记录数,计算处扫描时间(scan_time)和读取(read_time)。计算公式如下:
| scan_time=records/5 +1 //其中5表示每个where条件进行比较的次数,该值为常量。 read_time=((file_len)/4096+2)+scan_time+1.1 //其中4096表示IO buffer size |
如果read_time的值小于2.0并不强制使用索引,那么就不使用索引进行查询。否则,进行索引查询。
接着,根据查询条件,调用get_mm_tree()函数生成所有查询条件的一棵查询树。接下来的一系列操作将对查询树进行优化。具体get_mm_tree()函数的分析参照以下内容。
接下来,计算最小覆盖索引进行全索引读的代价。该逻辑需要首先查找合适的索引,以便于进行全表扫描。由于辅助索引(secondary key)是主键索引(primary key)的子集,并且无法比较两者的键长对IO的影响,因此,mysql选择了首先利用辅助索引,只有当辅助索引不能覆盖查找的条件或者辅助索引包含表中的列,才选择主键进行查询。根据索引,计算索引读取(key_read_time)时间,计算公式如下。如果得到的read_time大于key_read_time,则read_time=key_read_time。
| key_read_time=(records+keys_per_block-1)/keys_per_block keys_per_block=(block_size/2/(key_len+ref_len+1)) //block_size是文件的block大小,mysql默认为16K; //key_len是索引的键长度; //ref_len是主键索引的长度; |
然后,调用get_best_group_min_max()函数,用于获得最优的处理groupby中max/min的查询计划。具体内容参照该函数的具体介绍。
如果不需要索引合并,调用get_key_scans_params()函数,获得最优的范围查询计划,具体处理逻辑参照以下函数详解。调用get_best_ror_intersect ()函数,获得最优的非覆盖的ROR交叉执行计划,调用get_best_covering_ror_intersect()函数根据get_best_ror_intersect()函数提供的数据建立覆盖的ROR交叉执行计划。
否则,调用get_best_disjunct_quick()函数,获得索引合并的最优执行计划。具体内容参照以下具体介绍。
最后,调用TRP_RANGE::make_quick()函数,根据最优的范围查询计划,执行快速查询。详细见以下函数的详细介绍。
该函数简化后的流程图如下图所示:
|
|

20)get_mm_tree():(sql/opt_range.cc:5518)
get_mm_tree()函数用于根据所有查询条件的键,生成一颗查询树。如果查询条件的类型是COND_ITEM类型,即查询条件也是一个查询条件,则递归调用get_mm_tree()函数生成子查询树。如果为简单的查询类型,则构建查询树。如果查询条件类型是between、in以及默认调用get_full_func_mm_tree()函数(sql/opt_range.cc:5474),对查询条件进行转换后,构建查询树。例如:(c BETWEEN a AND b)转换为(c>=a AND c<=b),(c NOT BETWEEN a AND b)转化为(c<=a orc>=b),(f in (a,b,c))转换为(f=a OR f=b OR f=c)。
get_full_func_mm_tree()函数的主要处理逻辑在get_func_mm_tree()函数(sql/opt_range.cc:5180)中实现,后者对不同的情况进行了处理。
21) get_best_group_min_max():(sql/opt_range.cc:9407)
get_best_group_min_max()函数用于获得最优的处理groupby中max/min的查询计划。该处理过程分别对不同的组合情况进行了处理,具体的处理过程较复杂,设计到很多数学推理和逻辑组合的知识。
22) get_key_scans_params():(sql/opt_range.cc:4923)
get_key_scans_params()用于获得最优的范围查询计划。如果使用索引查找,那么调用check_quick_select()函数获得估计查询的记录数,在仅使用一个索引查找的情况下,读取时间(found_read_time)的值如表中(1)公式所示。否则,读取时间的值如表中(2)的公式所示。如果此时read_time大于found_read_time的值,则read_time=found_read_time,生成read_plan并且返回。
| (1)只使用一个索引读取 found_read_time=key_read_time+cpu_cost+0.01 //0.01是为了避免范围扫描和索引扫描排序 cpu_cost=found_records/5 //5表示每个where条件进行比较的次数 //found_records表示check_quick_select()获得的查询记录数。 (2)多个范围索引读取 found_read_time=found_records+range_count+cpu_cost+0.01 |
该函数的核心是调用check_quick_select()函数(sql/opt_range.cc:7519)获取查找的记录数,而check_quick_select()函数调用check_quick_keys()函数(sql/opt_range.cc:7628)通过聚集主键索引获得记录数。而check_quick_keys()函数是一个递归过程,通过扫描主键索引的SEL_ARG树,估计查询的记录数。SEL_ARG结构在定义之前的说明中,对该结构进行了详细解释,在此不做介绍。
23) get_best_ror_intersect():(sql/opt_range.cc)
get_best_ror_intersect()函数获得最优的非覆盖的ROR交叉执行计划(ROR-intersectionplan)。该过程在函数注视中命名为“非覆盖ROR-intersection查询算法(non-covering ROR-intersection search algorithm)”,从算法描述中可以看出,主要用于获得or查询的最小查询记录数和读取时间。
24) get_best_disjunct_quick():(sql/opt_range.cc)
get_best_disjunct_quick()函数用于获得索引合并的最优执行计划。该过程中使用SEL_IMERGE结构,该结构用于索引的合并操作。索引合并的代价计算在函数的注释中给出,如表中所示。其中index_reads是所有通过索引读的代价之和;rowid_to_row_scan如果是聚集主键索引,那么读的代价就是主键索引读的代价,否则根据文件的偏移量和block大小计算,此外还考虑到block中包含记录数和空block的情况;unique_use计算唯一索引读的代价。
| index_merge_cost=index_reads+rowid_to_row_scan+unique_use |
25) TRP_RANGE::make_quick():(sql/opt_range.cc:1881)
TRP_RANGE::make_quick()函数根据最优的范围查询计划,执行范围快速查询确定执行计划。其中调用get_quick_select()函数(sql/opt_range.cc:7903)通过键值和SEL_ARG树创建QUICK_RANGE_SELECT结构,并调用get_quick_keys()函数(sql/opt_range.cc:7945)获得所有可能的子范围。其中get_quick_keys()是一个递归过程。
26)choose_plan():(sql/sql_select.cc:4913)
choose_plan()函数用于获得一个最优的join顺序的执行计划。如果使用STRAIGHT_JOIN,调用optimize_straight_join()函数进行优化。否则,调用greedy_search()函数搜索一个最优的执行计划(之前的实现处理函数是find_best(),以后将要废弃)。optimize_straight_join()和greedy_search()函数参照以下详细分析。
该函数简化后的流程图如下图所示:
|
|

27)optimize_straight_join():(sql/sql_select.cc:5108)
在分析optimize_straight_join()函数逻辑之前,首先对STRAIGHT_JOIN这种join方式进行简单介绍。STRAIGHT_JOIN是 MySQL 对标准 SQL 的扩展,用于在多表查询时指定表载入的顺序。在 JOIN 表连接中,同样可以指定表载入的顺序[1]。理解了这一点,那么以下逻辑就容易理解了。
optimize_straight_join()函数对每一个join表,基于现有的部分执行计划,查找最优的访问计划,并将该计划添加到执行计划中。该过程主要调用best_access_path()函数,具体处理逻辑参照以下具体分析内容。
28)best_access_path():(sql/sql_select():4365)
best_access_path()基于现有“部分查询计划(partialQEP)”查找最优的访问计划,并添加到执行计划中。该过程根据当前可用的索引区的数目,对每一部分索引查找最优的计划,并计算访问计划的记录数和读取时间。其中针对不同的索引类型,对记录数和读取时间的估计方式也不同。
29)greedy_search():(sql/sql_select.cc:5219)
greedy_search()函数使用混合的贪婪/有限穷举搜索算法,查找最优的查询计划。每次评估还未优化的表的期望值(promising),选择期望最大的表来扩展当前“部分查询计划(partial QEP)”。期望值(promising)最大的表是带来的扩展代价最小的没有优化的表。该过程调用best_extension_by_limited_search()函数,用于实际有限次的穷举搜索最优的查询计划。具体best_extension_by_limited_search()函数的内容见以下分析。
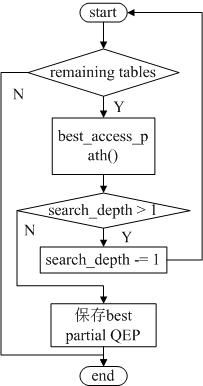
30)best_extension_by_limited_search():(sql/sql_select.cc:5425)
best_extension_by_limited_search()函数用于有限次的穷举搜索最优查询计划。该过程利用递归的深度优先搜索的方式进行搜索,搜索的深度通过变量“search_depth”控制。从该函数之前的注释中,给出了该函数的算法思想。
从函数逻辑来看,该函数依次每个未被优化的join表,调用best_access_path()函数,查找最优的访问计划,估计当前查询的记录数和读取时间,与现有的“部分查询计划”的查询记录数和读取时间进行比较,如果优于现有的查询计划,则保存当前最优的访问计划到“部分查询计划”。
如果目前的搜索的深度大于1,,递归调用best_extension_by_limited_search()函数,并且search_depth减1。否则,当前保存的是“部分最优的查询计划(best partial QEP)”或者“完全最优的查询计划(best complete QEP)”。
该函数简化后的流程图如下图所示:
|
|
31) get_best_combination():(sql/sql_select.cc:5793)
get_best_combination()函数根据greedy_search()函数得到的“最优查询计划”,获得最优的join结构,为执行查询做准备。
32) make_join_select():(sql/sql_select.cc:6374)
make_join_select()函数用于执行各种不同情况的join查询。该函数通过join时,连接表的不同搜索方式(唯一索引查找、ref查找、快速范围查找、合并索引查找、全表扫描等不同方式),进行join操作的处理。
33) JOIN::exec():(sql/sql_select.cc:1817)
JOIN::exec()函数根据执行计划,针对不同的查询(存储过程、表定义查询、where查询、having查询、order by条件、join查询(单纯的join,join和group,join、group by以及order by等不同查询)等查询),进行相应的查询处理。join查询中并调用do_select()函数,对所有的join表执行join查询操作,具体函数处理如下所示。
34) do_select():(sql/sql_select.cc:11431)
do_select()函数对所有的join表进行join查询操作。并将join查询后的结果通过socket发送。
35) st_select_lex::cleanup():(sql/)
st_select_lex::cleanup()函数用于清理查询的临时结构、临时变量。该过程调用JOIN::destroy()函数清理join操作使用的存储结构和变量。
总结
通过对mysql查询优化器的分析,对查询的逻辑处理流程有一定的深入了解。通过对简单的语句进行调试并得出以上分析文档,以上文档更侧重函数的逻辑处理过程。由于时间原因,对各种不同类型的查询,未进行逐一的跟踪调试,对工作原理和优化策略不敢妄自分析。因此,对不同类型的查询,mysql查询优化器的工作原理和优化策略,还需要进一步的深入研究。
由于跟踪调试语句的局限性和个人目前能力有限,对源码处理逻辑的理解不可避免存在错误,但本人已尽力做到准确。希望有相关研究经验的同事,给予批评和指正,共同讨论、共同进步。
进一步的研究
1、对不同的查询语句进行跟踪调试,梳理优化处理策略。
2、全面分析查询优化器的工作原理和优化策略。
参考资料
[1]、《MySQLSTRAIGHT_JOIN 与 NATURAL JOIN 》http://www.5idev.com/p-php_mysql_straight_join_natural_join.shtml