PostgreSQL启动过程中的那些事十六:启动进程二
这节主要讨论启动进程到了StartupXLOG。根据情况,如果需要就排除系统故障引起的数据库不一致状态,做相应的REDO或UNDO,然后创建一个检查点,把所有共享内存磁盘缓冲和提交数据缓冲写并文件同步到磁盘、把检查点插入xlog文件、更新控制文件,使数据库达到一种状态,设置共享内存中XLogCtl、ShmemVariableCache等对象信息;如果不需要,就根据控制文件从xlog文件读取最后的检查点信息,设置共享内存中XLogCtl、ShmemVariableCache等对象信息;启动完XLOG,启动进程完成使命,自己做了了断,postmaster进程根据子进程结束信号响应句柄继续。
目前没有看到数据文件里记录了检查点,难道这个没有???
3
先上个图
方法调用序列示意图
4
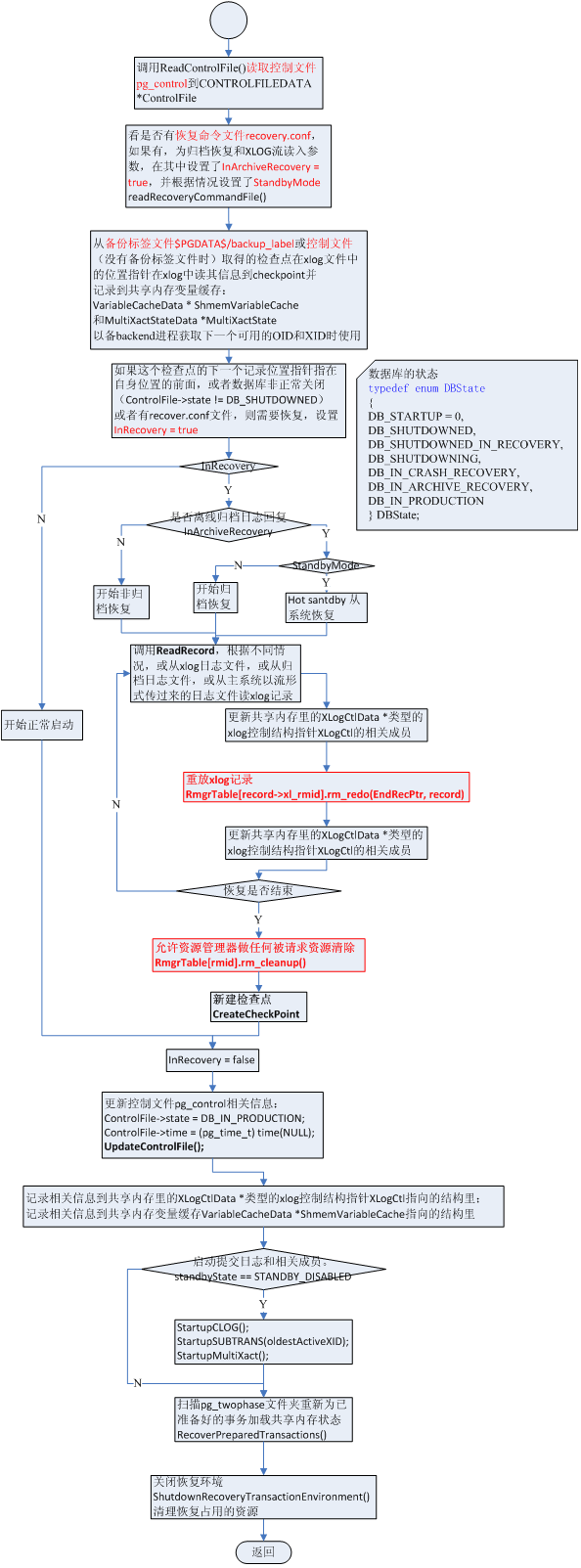
上StartupXLog方法的处理流程示意图
数据库在什么情况下需要恢复。如果出现事务故障、系统故障或者介质故障时,数据库需要恢复。出现诸如运算溢出、死锁、违反完整性约束等事务故障时数据库在运行时可以通过强制回滚自行处理。系统故障是主存数据丢失,未完成事务有些数据已写到物理数据库,此时数据库启动时需要事务回滚(UNDO/rollback)恢复。已完成事务有些或全部数据未写到物理数据库,此时数据库启动时需要重做(REDO)已提交事务。介质故障,需要从以前的备份做专门恢复。
话说到了XLogStartup方法,在这个方法里最主要的是根据情况判断是否需要恢复。如果不需要恢复,处理比较简单;如果需要恢复,根据不同状况做相应恢复。这儿这个状况就是判断系统是否在上次关闭时出现了系统故障。
XLogStartup方法,先读取控制文件pg_control到ControlFileData数据结构,再看是否有恢复命令文件recovery.conf(判断是否是归档模式,如果归档模式,需要恢复的话,就是归档恢复),读取内容并设置InArchiveRecovery = true,并根据情况,如果是hot standby的从系统,设置StandbyMode = true。接着读时间线历史文件。然后把来自控制文件的恢复目标时间线recoveryTargetTLI和归档清楚命令archive_cleanup_command保存于共享内存中的xlog控制结构XLogCtl的相关成员里以备其它进程查看。接着调用read_backup_label方法,看是否有备份标签文件$PGDATA$/backup_label,如果有,从中取检查点记录位置赋给checkPointLoc,如果没有备份标签文件,把控制文件里的检查点位置赋给checkPointLoc。根据这个检查点位置指针checkPointLoc从xlog文件中读这个检查点的xlog记录解析到检查点对象checkpoint。根据其自身位置指针和其记录的下一个xlog记录位置指针,或者控制文件记录的数据库是否非正常关闭状态或(ControlFile->state != DB_SHUTDOWNED)者有无recover.conf文件,判断是否需要恢复。
如果不需要恢复,更新控制文件的state等于DB_IN_PRODUCTION,time等于系统当前时间。接着设置共享内存里的XLogCtl的成员Write.lastSegSwitchTime为当前时间,根据控制文件初始化XLogCtl的最后的检查点的XID/epoch,再初始化共享内存里缓存变量结构ShmemVariableCache的latestCompletedXid以备份事务ID(ShmemVariableCache->latestCompletedXid = ShmemVariableCache->nextXid)然后调用RecoverPreparedTransactions()扫描pg_twophase文件夹重新为已准备好的事务加载共享内存状态。如果任何关键GUC参数改变了,在我们允许backend进程写WAL日志以前记录到日志。所有这些事搞定后,设置xlogctl->SharedRecoveryInProgress= false允许backend进程写WAL日志。然后退出启动进程,postmaster进程响应子进程退出信号其它相关进程。
如果需要恢复。这儿要处理的是崩溃时刻未完成事务已写入物理数据库的事务(处理方法是UNDO)和崩溃时刻已完成事务未写入物理数据库的事务(处理方法是REDO)。
根据数据库的运行模式(有无起归档,有无hot standby。有hot standby时,其主系统恢复和启归档情况一样进行恢复,从系统单独处理),调用ReadRecord方法从不同地方读取xlog日志记录,调用xlog的资源管理器xmgr的相应资源的重放方法做恢复。恢复完成后剩余步骤和不需要恢复的情况一样,处理后续事宜。然后退出启动进程,postmaster进程响应子进程退出信号其它相关进程。略详细过程见“XLogStartup流程示意图”
相关主要结构见下面:
控制文件的结构ControlFileData及检查点结构CheckPoint参见《PostgreSQL存储系统一:控制文件存储结构》。
XLog日志文件相关结构参见《PostgreSQL存储系统二:REDOLOG文件存储结构》。
VariableCache是共享内存里用来跟踪OID和XID分配状态的数据结构。由于历史原因,由不同的轻量锁LWLock保护这个结构中不同的字段。
typedefstruct VariableCacheData
{
/*这些字段由OidGenLock锁保护 */
Oid nextOid; /* next OID to assign */
uint32 oidCount; /* OIDs available before must do XLOG work */
/*这些字段由XidGenLock锁保护 */
TransactionIdnextXid; /* nextXID to assign */
TransactionIdoldestXid;/* cluster-wideminimum datfrozenxid */
TransactionIdxidVacLimit; /* start forcing autovacuumshere */
TransactionIdxidWarnLimit;/* start complaining here */
TransactionIdxidStopLimit;/* refuse to advance nextXid beyond here */
TransactionIdxidWrapLimit;/* where the world ends */
Oid oldestXidDB; /* database with minimum datfrozenxid*/
/*这些字段由ProcArrayLock锁保护 */
TransactionIdlatestCompletedXid; /* newest XID that has committed or
* aborted */
}VariableCacheData;
typedefVariableCacheData *VariableCache;
XLOG的共享内存总状态
typedefstruct XLogCtlData
{
/* 由WALInsertLock锁保护 */
XLogCtlInsertInsert;
/* 由info_lck锁保护 */
XLogwrtRqstLogwrtRqst;
XLogwrtResultLogwrtResult;
uint32 ckptXidEpoch; /* nextXID & epoch of latest checkpoint*/
TransactionIdckptXid;
XLogRecPtr asyncXactLSN; /* LSN of newest async commit/abort */
uint32 lastRemovedLog; /* latest removed/recycled XLOG segment */
uint32 lastRemovedSeg;
/* 由WALWriteLock锁保护 */
XLogCtlWriteWrite;
/*尽管这些值可以变,但在启动后不再改变。是否可以读/写页面和块的值依赖于WALInsertLock和WALWriteLock锁 */
char *pages; /* buffers for unwritten XLOG pages */
XLogRecPtr*xlblocks; /* 1st byte ptr-s + XLOG_BLCKSZ */
int XLogCacheBlck; /* highest allocated xlog buffer index */
TimeLineID ThisTimeLineID;
TimeLineID RecoveryTargetTLI;
/* archiveCleanupCommand是从recovery.conf文件里读的,但需要放在共享内存里以使bgwriter进程能访问它 */
char archiveCleanupCommand[MAXPGPATH];
/* SharedRecoveryInProgress指明本进程是否正在做崩溃或归档恢复。由
info_lck锁保护 */
bool SharedRecoveryInProgress;
/*
* SharedHotStandbyActive 指明本进程是否正在做崩溃或归档恢复。由
info_lck锁保护 */
bool SharedHotStandbyActive;
/*如果正在等WAL到达或者failover的触发器文件出现,recoveryWakeupLatch用于唤醒启动将成继续重放WAL。 */
Latch recoveryWakeupLatch;
/*在恢复期间,我们在这儿保存最后一个检查点的拷贝。当bgwriter想创建一个重启点restartpoint时由bgwriter进程使用。由info_lck锁保护。 */
XLogRecPtr lastCheckPointRecPtr;
CheckPoint lastCheckPoint;
/* 最后一个检查点或被重放的检查点的结束位置加1 */
XLogRecPtr replayEndRecPtr;
/*被重放的最后一个记录的结束位置加1 */
XLogRecPtr recoveryLastRecPtr;
/*最后被重放的 COMMIT/ABORT记录的时间戳 */
TimestampTzrecoveryLastXTime;
/*是否请求暂停恢复? */
bool recoveryPause;
slock_t info_lck; /* locks shared variables shown above */
} XLogCtlData;
static XLogCtlData *XLogCtl = NULL;
/* XLogInsert的共享状态数据结构*/
typedefstruct XLogCtlInsert
{
XLogwrtResultLogwrtResult; /* a recent value of LogwrtResult */
XLogRecPtr PrevRecord; /* start of previously-inserted record */
int curridx; /* current block index in cache */
XLogPageHeadercurrpage; /* points to header of block in cache */
char *currpos; /* current insertion point in cache */
XLogRecPtr RedoRecPtr; /* current redo point for insertions */
bool forcePageWrites; /* forcing full-page writes for PITR? */
/*如果在进程里备份由pg_start_backup()开始,exclusiveBackup是true;nonExclusiveBackups是计数器,指明进程里当前基于流备份的数目。当上面两个任一个非0时(即有上面的备份时),forcePageWrites是ture。lastBackupStart是最后一个检查点的redo值(下一个xlog记录的位置指针),作为在线备份的起始点。 */
bool exclusiveBackup;
int nonExclusiveBackups;
XLogRecPtr lastBackupStart;
} XLogCtlInsert;
XLOG控制的共享内存数据结构,LogwrtRqst指出我们需要写/文件同步到日志的那个字节位置(在这个位置之前的所有记录必须被写或做文件同步)。LogwrtResult指出我们已经写/文件同步了的字节位置。
typedefstruct XLogwrtRqst
{
XLogRecPtr Write; /* last byte + 1 to write out */
XLogRecPtr Flush; /* last byte + 1 to flush */
} XLogwrtRqst;
typedefstruct XLogwrtResult
{
XLogRecPtr Write; /* last byte + 1 written out */
XLogRecPtr Flush; /* last byte + 1 flushed */
} XLogwrtResult;
指向XLOG里位置的指针。这个指针是64位,因为我们不想它有溢出的时候。
注意:用来指明一个无效的指针。这个没问题,因为我们在XLOG页头用了页头结构,因此XLOG记录不可能从页头开始。
注意:这儿容易引起理解错乱,这个xlogid(对应实际XLOG文件名字的中间八位)表示逻辑XLOG日志文件ID,因为组成XLOG逻辑文件的实际物理文件远小于4Gb。组成对应这个xlogid的逻辑日志文件的每一个实际物理文件是一个XLogSegSize字节大小的“段”("segment",段号是实际XLOG文件名字的后八位)。前面加上用八位表示的一个时间线ID、逻辑日志文件号和段号一起标识一个物理的XLOG日志文件(“段”)。段号和物理文件里的偏移量由xrecoff/XLogSegSize和xrecoff%XLogSegSize计算。
typedefstruct XLogRecPtr
{
uint32 xlogid; /* log file #, 0 based */
uint32 xrecoff; /* byte offset of location in log file */
}XLogRecPtr;
/* XLogWrite/XLogFlush的共享内存里的状态数据结构 */
typedefstruct XLogCtlWrite
{
XLogwrtResultLogwrtResult; /* current value of LogwrtResult */
int curridx; /* cache index of next block to write */
pg_time_t lastSegSwitchTime; /* time of last xlog segmentswitch */
} XLogCtlWrite;
/*系统状态指示器。 */
typedefenum DBState
{
DB_STARTUP = 0,
DB_SHUTDOWNED,
DB_SHUTDOWNED_IN_RECOVERY,
DB_SHUTDOWNING,
DB_IN_CRASH_RECOVERY,
DB_IN_ARCHIVE_RECOVERY,
DB_IN_PRODUCTION
} DBState;
XLogStartup流程示意图中的两个红色方框红色字的框是XLOG资源管理器xmgr的处理方法,这个XLOG的资源管理器内容较多,单列主题讨论。还有恢复完成后调用了方法CreateCheckPoint,创建一个检查点以将所有的恢复数据写到磁盘。
5 创建检查点
创建一个检查点,会将共享内存里的所有磁盘缓冲和提交日志缓冲刷出并文件同步到磁盘。
下面这些情况可能引起创建检查点,为了使用方便,把这些情况定义成如下标志,这些标志可以按位做或运算。检查点的起因不同,创建检查点的行为也略有不同。
#defineCHECKPOINT_IS_SHUTDOWN 0x0001/* Checkpoint is for shutdown */
#defineCHECKPOINT_END_OF_RECOVERY0x0002 /* Likeshutdown checkpoint,
* but issued at end of WAL
* recovery */
#defineCHECKPOINT_IMMEDIATE 0x0004 /* Do it withoutdelays */
#define CHECKPOINT_FORCE 0x0008 /* Force even if no activity */
/* These are important to RequestCheckpoint */
#define CHECKPOINT_WAIT 0x0010 /* Wait for completion */
/* These indicate the cause of a checkpoint request */
#defineCHECKPOINT_CAUSE_XLOG 0x0020 /* XLOGconsumption */
#define CHECKPOINT_CAUSE_TIME 0x0040 /* Elapsed time */
创建检查点的基本过程是先让存储管理器smgr(以后单列状态讨论)为检查点做好准备,根据情况填充检查点结构的成员,CheckpointGuts方法把共享内存里的磁盘缓冲和提交日志缓冲输出到磁盘(即写数据文件)。接着调用XlogInsert把这个检查点插入xlog文件。然后更新控制文件相关成员。最后更新共享内存里XlogCtl的检查点相关成员和检查点的统计信息结构。相关结构定义和创建检查点流程示意图见下面。
/*检查点统计信息 */
typedefstructCheckpointStatsData
{
TimestampTzckpt_start_t; /* startof checkpoint */
TimestampTzckpt_write_t; /* startof flushing buffers */
TimestampTzckpt_sync_t;/* start of fsyncs*/
TimestampTzckpt_sync_end_t; /* end of fsyncs*/
TimestampTzckpt_end_t; /* end ofcheckpoint */
int ckpt_bufs_written; /* # ofbuffers written */
int ckpt_segs_added; /* # of new xlog segments created */
int ckpt_segs_removed; /* # of xlogsegments deleted */
int ckpt_segs_recycled; /* # of xlogsegments recycled */
int ckpt_sync_rels;/* # of relations synced */
uint64 ckpt_longest_sync; /* Longest sync for one relation */
uint64 ckpt_agg_sync_time; /* The sum of all the individual sync
* times, which is not necessarily the
* same as the total elapsed time for
* the entire sync phase. */
}CheckpointStatsData;
当前检查点的统计信息收集在这个全局结构变量里。
CheckpointStatsDataCheckpointStats;

创建检查点流程示意图
上图中,其中CheckPointGuts方法的定义见下面,刷出所有共享内存中的数据到磁盘并做文件同步。方法定义见下面,把clog、subtrans、multixact、predicate、relationmap、buffer(数据文件)和twophase相关数据统统刷和文件同步到磁盘。这儿先不深入讨论这个方法了。
staticvoid
CheckPointGuts(XLogRecPtrcheckPointRedo,int flags)
{
CheckPointCLOG();
CheckPointSUBTRANS();
CheckPointMultiXact();
CheckPointPredicate();
CheckPointRelationMap();
CheckPointBuffers(flags); /* performs all required fsyncs */
/* We deliberately delay 2PC checkpointingas long as possible */
CheckPointTwoPhase(checkPointRedo);
}
结果这么多逻辑严谨的一系列行为后,数据库达到了正常状态,启动进程寿终正寝。然后,postmaster进程响应该子进程退出,分别依次fork出bgwriter进程、walwriter进程、autovaclauncher进程、archiver进程、pgstat进程,然后抛出一句”database system is ready to acceptconnections”。然后进入serverloop,等待客户端请求到达,启动postgres服务进程,开始履行使命。
Serverloop还检查bgwriter进程、walwriter进程、autovaclauncher进程、archiver进程、pgstat进程,还有前面启动的系统日志进程sysloger这些辅助检查是否正常运行,如果没有,就重启这些进程。此时,pg服务器端有postmaster进程和这六个辅助进程运行,准备好为客户端进程提供服务,提供的服务由postgres服务进程完成。
------------
转载请著明出处,来自博客:
blog.csdn.net/beiigang
beigang.iteye.com