数据挖掘笔记-寻找相似文章-Java
"寻找相似文章"的一种简单算法:
(1)使用TF-IDF算法,找出两篇文章的主要关键词;
(2)每篇文章各取出若干个关键词,合并成一个词集合,然后计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个词频向量的余弦相似度,值越大就表示越相似。
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处。
TF(term frequency)在一份给定的文件里,词频指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语t来说,它的重要性可表示为:
![]()
以上式子中![]() 是该词在文件
是该词在文件![]() 中的出现次数,而分母则是在文件
中的出现次数,而分母则是在文件![]() 中所有字词的出现次数之和。
中所有字词的出现次数之和。
IDF(inverse document frequency)逆向文件频率是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中
- |D|:语料库中的文件总数
 :包含词语t的文件数目(即
:包含词语t的文件数目(即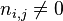 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用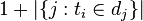
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF算法是建立在这样一个假设之上的:对区别文档最有意义的词语应该是那些在文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词语,所以如果特征空间坐标系取TF词频作为测度,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,TFIDF法认为一个单词出现的文本频数越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度IDF的概念,以TF和IDF的乘积作为特征空间坐标系的取值测度,并用它完成对权值TF的调整,调整权值的目的在于突出重要单词,抑制次要单词。但是在本质上IDF是一种试图抑制雜訊的加权 ,并且单纯地认为文本頻率小的单词就越重要,文本頻率大的单词就越无用,显然这并不是完全正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以TFIDF法的精度并不是很高。
此外,在TFIDF算法中并没有体现出单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中对文章内容的反映程度不同,其权重的计算方法也应不同。因此应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示的效果。
用TF-IDF算法可以提取关键词。但是除了找到关键词,我们还希望找到与原文章相似的其他文章。为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。首先我们从将文章分词(如何分看自己处理),列出所有过滤筛选后的词。然后开始计算每个词的词频,最后得到词频向量,计算词频向量的夹角。我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:

假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
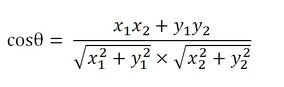
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:

余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。余弦相似度的值为0到1之间。"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。
下面用Java来简单实现算法
/** 文档文章*/
public class Document {
/** 文件名称*/
private String name = null;
/** 文章所属类型*/
private String category = null;
/** 文章分词*/
private String[] words = null;
/** 词语计算TFIDF*/
private Map<String, Double> tfidfWords = null;
/** 文章相似度*/
private List<DocumentSimilarity> similarities = null;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public String[] getWords() {
return words;
}
public void setWords(String[] words) {
this.words = words;
}
public Map<String, Double> getTfidfWords() {
if (null == tfidfWords) {
tfidfWords = new HashMap<String, Double>();
}
return tfidfWords;
}
public void setTfidfWords(Map<String, Double> tfidfWords) {
this.tfidfWords = tfidfWords;
}
public List<DocumentSimilarity> getSimilarities() {
if (null == similarities) {
similarities = new ArrayList<DocumentSimilarity>();
}
return similarities;
}
public void setSimilarities(List<DocumentSimilarity> similarities) {
this.similarities = similarities;
}
}
public class DocumentHelper {
/**
* 文档中是否包含词
* @param document
* @param word
* @return
*/
public static boolean docHasWord(Document document, String word) {
for (String temp : document.getWords()) {
if (temp.equalsIgnoreCase(word)) {
return true;
}
}
return false;
}
/**
* 词向量化
* @param document
* @param words
* @return
*/
public static double[] docWordsVector(Document document, String[] words) {
double[] vector = new double[words.length];
Map<String, Integer> map = docWordsStatistics(document);
int index = 0;
for (String word : words) {
Integer count = map.get(word);
vector[index++] = null == count ? 0 : count;
}
return vector;
}
/**
* 文档词计算TFIDF后取前N
* @param document
* @param n
* @return
*/
public static String[] docTopNWords(Document document, int n) {
String[] topWords = new String[n];
Map<String, Double> tfidfWords = document.getTfidfWords();
List<Map.Entry<String, Double>> list =
new ArrayList<Map.Entry<String, Double>>(tfidfWords.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Double>>() {
@Override
public int compare(Entry<String, Double> o1,
Entry<String, Double> o2) {
return -o1.getValue().compareTo(o2.getValue());
}
});
int index = 0;
for (Map.Entry<String, Double> entry : list) {
if (index == n) {
break;
}
topWords[index++] = entry.getKey();
System.out.print(document.getName() + " : " + entry.getKey() + " : ");
DecimalFormat df4 = new DecimalFormat("##.0000");
System.out.println(df4.format(entry.getValue()));
}
return topWords;
}
/**
* 文档中词统计
* @param document
* @return
*/
public static Map<String, Integer> docWordsStatistics(Document document) {
Map<String, Integer> map = new HashMap<String, Integer>();
for (String word : document.getWords()) {
Integer count = map.get(word);
map.put(word, null == count ? 1 : count + 1);
}
return map;
}
/**
* 词所在文档统计
* @param word
* @param documents
* @return
*/
public static int wordInDocsStatistics(String word, List<Document> documents) {
int sum = 0;
for (Document document : documents) {
if (docHasWord(document, word)) {
sum += 1;
}
}
return sum;
}
}
public class DocumentOperation {
/**
* 计算TFIDF
* TF计算是词频除以总词数
* @param documents
*/
public static void calculateTFIDF(List<Document> documents) {
int docTotalCount = documents.size();
for (Document document : documents) {
Map<String, Double> tfidfWords = document.getTfidfWords();
int wordTotalCount = document.getWords().length;
Map<String, Integer> docWords = DocumentHelper.docWordsStatistics(document);
for (String word : docWords.keySet()) {
double wordCount = docWords.get(word);
double tf = wordCount / wordTotalCount;
double docCount = DocumentHelper.wordInDocsStatistics(word, documents) + 1;
double idf = Math.log(docTotalCount / docCount);
double tfidf = tf * idf;
tfidfWords.put(word, tfidf);
}
System.out.println("doc " + document.getName() + " finish");
}
}
/**
* 计算TFIDF
* TF计算是词频除以词频最高数
* @param documents
*/
public static void calculateTFIDF_1(List<Document> documents) {
int docTotalCount = documents.size();
for (Document document : documents) {
Map<String, Double> tfidfWords = document.getTfidfWords();
List<Map.Entry<String, Double>> list =
new ArrayList<Map.Entry<String, Double>>(tfidfWords.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Double>>() {
@Override
public int compare(Entry<String, Double> o1,
Entry<String, Double> o2) {
return -o1.getValue().compareTo(o2.getValue());
}
});
if (list.size() == 0) continue;
double wordTotalCount = list.get(0).getValue();
Map<String, Integer> docWords = DocumentHelper.docWordsStatistics(document);
for (String word : docWords.keySet()) {
double wordCount = docWords.get(word);
double tf = wordCount / wordTotalCount;
double docCount = DocumentHelper.wordInDocsStatistics(word, documents) + 1;
double idf = Math.log(docTotalCount / docCount);
double tfidf = tf * idf;
tfidfWords.put(word, tfidf);
}
System.out.println("doc " + document.getName() + " finish");
}
}
/**
* 计算相似度
* @param documents
*/
public static void calculateSimilarity(List<Document> documents) {
for (Document document : documents) {
String[] topWords = DocumentHelper.docTopNWords(document, 20);
for (Document odocument : documents) {
String[] otopWords = DocumentHelper.docTopNWords(odocument, 20);
String[] allWords = WordUtils.mergeAndRemoveRepeat(topWords, otopWords);
double[] v1 = DocumentHelper.docWordsVector(document, allWords);
double[] v2 = DocumentHelper.docWordsVector(odocument, allWords);
double cosine = DistanceUtils.cosine(v1, v2);
DocumentSimilarity docSimilarity = new DocumentSimilarity();
docSimilarity.setDocName1(document.getName());
docSimilarity.setDocName2(odocument.getName());
docSimilarity.setVector1(v1);
docSimilarity.setVector2(v2);
docSimilarity.setCosine(cosine);
document.getSimilarities().add(docSimilarity);
}
for (DocumentSimilarity similarity : document.getSimilarities()) {
System.out.println(similarity);
}
}
}
public static void main(String[] args) {
String path = "D:\\resources\\01-news-18828";
DataSet dataSet = DataLoader.load(path);
calculateTFIDF(dataSet.getDocuments());
calculateSimilarity(dataSet.getDocuments());
}
}
代码托管:https://github.com/fighting-one-piece/repository-datamining.git