网络字节序和大小端字节序
先说说为什么会有大小端字节序的问题。现在PC机的一个整型变量一般是32位的,由4个字节组成。在计算机内存中,每个字节都是有地址的。也就是说一个整型的4个字节的地址是不同的,有高低地址之分。对于一个整数,如632523,其对应的二进制位1001 10100110 11001011。需要3个字节才能放得下。这时就存在一个问题,对于低8位11001011是存放在整型的那4个字节的低地址位还是高地址位。
如果将低8位存放在4个字节中的低地址位,称为小端字节序,如果将低8位存放在高地址位,则为大端字节序。助记:沿着内存的增长方向,先存低8位是的小端;先存高8位的是大端。大小端字节序是由CPU决定的[1][2][3]。
虽然不同的CPU厂商可以随意选择一种字节序作为自己的内存字节序,但是网络字节序就不能任由各个CPU选择,网络字节序被规定为大端字节序。
一般来说,主机要先把端口号从主机字节序转换到网络字节序。有下面的函数可以相互转换。
#include<netinet/in.h> unsigned long int htonl(unsigned long int hostlong); unsigned short int htons(unsigned short int hostshort); unsigned long int ntohl(unsigned long int netlong); unsigned short int ntohs(unsigned short int netshort);
其中,htonl 表示”host to network long”。
有了这些转换函数,用户就不需要知道所在的OS/CPU用的什么字节序。反正这些函数会被我们想要的值转换成网络字节序的值。
除了这4个函数外,在头文件endian.h中,还定义了很多主机字节序和大小端字节序相互转换的函数。
从这里可以看到,下面函数是在glibc 2.9及之后的版本才支持。可以用$ldd --version命令 查看glibc的版本。
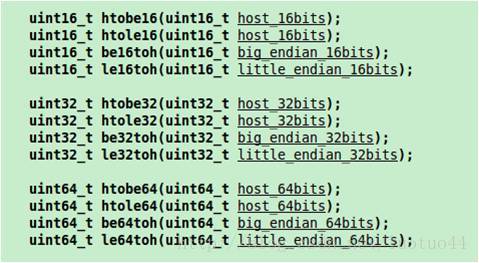
其中,be是表示大端,le是表示小端。
上图中的那些函数(其实那些是宏定义),用来配置端口号是没有用的,因为已经有htons函数了。但在解决TCP粘包问题中,这些函数就可以派上用场了。
解决TCP粘包问题的一个方法是,在每条消息的头部添加一个长度字段。每一个主机在发送消息前,都把长度转换成大端字节序存放(转换成小端字节序也行,只要CS两端统一即可)。然后发送消息。对端在收到消息的长度字段后,就将其从大端字节序转换成主机字节序。
这里存在一个问题,怎么将怎么将收到的字节流转换成大端字节序的整型变量。答案是用memcpy函数。在发送端将整型变量变成字节流也是用这个函数。
如下面代码所示:
//发送端
int len = htobe32(a);
char ch[10];
memcpy(ch, &len, sizeof(len) );
//接收端
int len;
char* message;
memcpy(&len, message, sizeof(len) );
a = be32toh(len);
参考:
[1] http://en.wikipedia.org/wiki/Endianness
[2] http://stackoverflow.com/questions/9237317/what-makes-a-system-little-endian-or-big-endian
[3] http://superuser.com/questions/308274/what-determines-endianness