hadoop1.2.1在linux中配置安装独立运行Standalone Operation,伪分布Pseudo-Distributed Operation,集群配置三种配置和测试
前言:
由于安装已经很长时间了,有些问题我已记不得太清,如果哪里有手误敬请指出。但是要记住遇到问题可以直接上网查,就算你不知道为什么有问题你让可以把报错的那句话复制直接查。
我这个大概适用的是1.X版本。要提醒各位,一定要学到东西,即使只是安装。不要犯直接复制别人代码ip,别人版本的问题!!!
1:安装sun jdk
我此处用的另一篇文章中的命令,但是安装的貌似是OPenJDK,老师要求不能安装这个一定要是sunjdk,否则后面会后问题,我决定后面有问题时我再改。而且此处我安装后并没有专门的配置环境变量后面的步骤中会有。
2:安装ssh(hadoop使用ssh来实现cluster中各node 的登录认证,即Namenode是通过SSH来启动和停止各个datanode上的各种守护进程的,所以一定要实现免密码登录,免密码 ssh 设置在后文中有介绍)
sudo apt-get install ssh
3.安装rsync(Ubuntu12.10已自带rsync)
sudo apt-get install rsync
4.其他为了方便,可以安装vim:
ubuntu系统:
普通用户下输入命令:sudo apt-get install vim-gtk
centos系统:
普通用户下输入命令:yum -y install vim*
下面开始安装Hadoop
1、创建hadoop用户组以及用户:
sudo addgroup hadoop
sudo adduser --ingroup hadoop hadoop
在/home/下会有一个新的hadoop文件夹,此时最好切换至新建的hadoop用户登陆Ubuntu。
2.将下载的hadoop拷贝至该新建文件夹下:
注意此处命令的目录,这是我们老师的目录,你的下载目录并不一定就在/mnt/hgfs下。
cp /mnt/hgfs/hadoop-1.2.1-bin.tar.gz /home/hadoop/
3.进入该目录(cd /home/hadoop/)之后,解压该文件:
tar xzf hadoop-1.2.1-bin.tar.gz
4.进入hadoop-env.sh所在目录(hadoop-1.2.1/conf/),对该文件进行如下内容的修改:
export JAVA_HOME=/usr/lib/jvm/java-7-oracle(/usr/java/jdk1.6.0_07为jdk安装目录)
5.为了方便执行Hadoop命令,修改/etc/profiles,在最后面加上
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export HADOOP_HOME=/home/hadoop/hadoop-1.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/htmlconverter.jar:$JAVA_HOME/lib/jconsole.jar:$JAVA_HOME/lib/sa-jdi.jar
重新启动,使得/etc/profiles生效;或者直接执行source etc/profile实现重启作用。
其实这时你的hadoop已经简单安装成功。
测试及配置文件:
一、单机版:
6. hadoop 默认是 Standalone Operation。可以按照官方文档进行测试:
在/home/hadoop目录下建立HadoopStandaloneTest目录
$ mkdir HadoopStandaloneTest
在/home/hadoop/HadoopStandaloneTest目录下执行以下命令:
$ mkdir input
$ cp $HADOOP_HOME/conf/*.xml input
$ hadoop jar $HADOOP_HOME/hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+'
(注意jar前面不要加-)
(bin/hadoop jar(使用hadoop运行jar包)hadoop-*_examples.jar ( jar 包的名字) grep(要使用的类,后边的是参数)input output ‘dfs[a-z.]+’
整个就是运行hadoop示例程序中的grep,对应的hdfs上的输入目录为input、输出目录为;output。)
提醒!此处成功标志就是在你的主目录下HadoopStandaloneTest的有input,output两个文件夹,且output里会有两个文件,显示执行的结果。建议下个java得反编译的工具查看/hadoop-examples-1.2.1.jar的代码,更能理解这个栗子。
二、伪分布:
7.测试Pseudo-Distributed Operation
7.1首先查看ssh服务器和ssh客户端是否启动
$ps -e|grep ssh
如看到如下二个进程则OK

注!!!如果此处你的ssh-agent没有启动成功,执行:
eval ‘ssh-agent’
7.2在/home/hadoop目录下建立HadoopPseudoDistributeTest目录【此处老师的命令目录中少了个e】
$ mkdir HadoopPseudoDistributeTest
$cd HadoopPseudoDistributeTest/
$mkdir conf
$cp $HADOOP_HOME/conf/* conf( 复制conf目录下的所有文件)
编辑HadoopPseudoDistributeTest/conf/下的配置文件
core-site.xml:用于配置Common组件的属性
hdfs-site.xml:用于配置HDFS的属性
mapred-site.xml:用于配置MapReduce的属性
masters指定master节点
slaves指定slave节点
注:下面配置文件中有两次用到ip地址(ifconfig命令查询IP地址),一定记得改成你自己的ip地址。而且如果你是直接复制老师的文件,记得把里面的注释前面的——改成--,否则低级错误!
core-site.xml:
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:14px;"><configuration> <property> <name>fs.default.name</name> <!--最好不要用localhsot,否则Eclipse插件会出问题 ip地址换成自己的--> <value>hdfs://192.168.231.111:9000</value> </property> <property> <!--A base for other temporary directories(用来存储其他临时目录的根目录) --> <name>hadoop.tmp.dir</name> <value>/home/hadoop/HadoopPseudoDistributeTest/tmpdir</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration></span></span></span>
hdfs-site.xml
<span style="font-size:18px;"><span style="font-size:18px;"><configuration> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <!--指定namenode存储文件系统元数据的目录 --> <name>dfs.name.dir</name> <value>/home/hadoop/HadoopPseudoDistributeTest/tmpdir/hdfs/name</value> </property> <property> <!--指定datanode存储数据的目录 --> <name>dfs.data.dir</name> <value>/home/hadoop/HadoopPseudoDistributeTest/tmpdir/hdfs/data</value> </property> </configuration></span></span>mapred-site.xml
<span style="font-size:18px;"><span style="font-size:18px;"><configuration> <property> <name>mapred.job.tracker</name> <!-ip地址记得换--> <value>192.168.231.111:9001</value> </property> </configuration></span></span>
masters:
localhost
slave:
localhost
7.3注意不要在HadoopPseudoDistributeTest创建以下目录【rm -rf 文件夹 命令用来删除非空文件夹】tmpdir/hdfs/name tmpdir/hdfs/data
7.4测试ssh 测试可否使用 ssh 登陆 localhost
$ ssh localhost
发现需要输入密码
7.5实现免密码输入ssh 登录
假设A为客户机器, B 为目标机;
要达到的目的:
A机器ssh 登录 B 机器无需输入密码;
加密方式选rsa|dsa均可以,默认 dsa
做法:
1、登录A机器
2、ssh-keygen -t [rsa|dsa],将会生成密钥文件和私钥文件id_rsa, id_rsa.pub或 id_dsa,
id_dsa.pub
3、将.pub文件复制到 B 机器的 .ssh 目录, 并 cat id_dsa.pub >> ~/.ssh/authorized_keys
4、大功告成,从A机器登录 B 机器的目标账户,不再需要密码了;
$ ssh-keygen -t dsa –P '' -f ~/.ssh/id_dsa(先不要着急执行,看下面)
其中
-t dsa指定密码算法为dsa
-P ''指不需要passphrase
-f ~/.ssh/id_dsa 指定秘钥输出文件
其实在真正执行时,上面的那句命令会说太长无法执行,所以其实只输入前面“$ ssh-keygen -t dsa”即可,输入之后会有其他的提示,提示你输入密码时,直接回车就代表密码回空,具体如下:
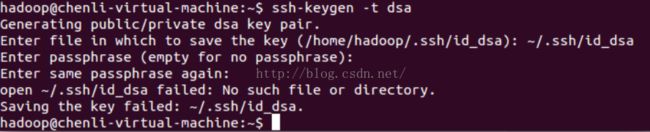
之后可以看到~/.ssh目录下多了二个文件:
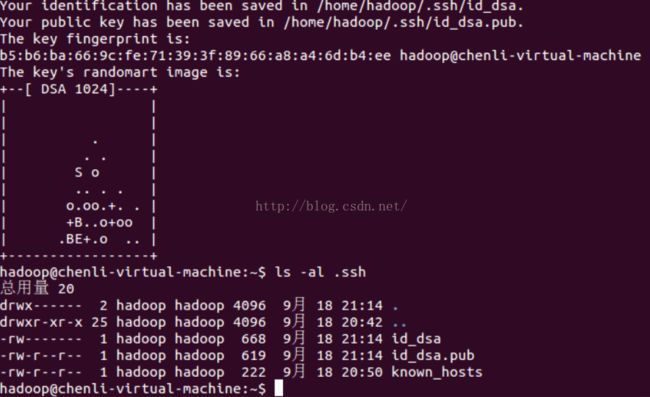
将ssh公钥追加到 authorized_keys 后面,即可实现免密钥登陆。
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
修改~/.ssh/authorized_keys的权限,要保证.ssh和authorized_keys 都只有用户自己有写权限。
否则验证无效。
$ chmod 600 ~/.ssh/authorized_keys
~/.ssh目录的权限为700, 因此不用修改。
ebkit-text-stroke-width: 0px; ">再利用ssh登录,发现不再需要输入密码
$ ssh localhost
7.7格式化HDFS 的 namenode(管理元数据)创建一个空的文件系统【可以直接不执行这句话,在7.8中第二句后执行“hadoop namenode -format”】
$ hadoop --config ~/HadoopPseudoDistributeTest/conf namenode-format
注意--config后面一定用绝对路径指定配置文件所在的路径
7.8运行hadoop(切记:首先使用ssh登陆 localhost)
$ ssh localhost
ssh localhost export HADOOP_CONF_DIR=~/HadoopPseudoDistributeTest/conf( 这 样 后 面 就 不 用 带 —config选项)
$HADOOP_HOME/bin/start-all.sh7.9打开浏览器
NameNode- http://localhost:50070/
JobTracker-http://localhost:50030/
7.10运行jps 命令看相应服务是否启动:
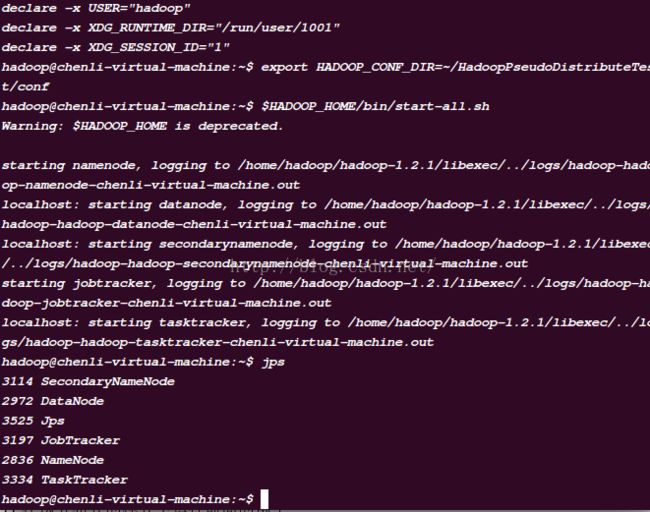
7.11在伪分布式的模式下运行前面的例子
1)Copy the input files into the distributed filesystem:
cd /home/hadoop/HadoopPseudoDistributeTest hadoop fs -put conf/*xml input
将本地文件系统目录conf拷贝到分布式文件系统的 input 下
hadoop fs -ls查看分布式文件系统的内容
cd ~/HadoopPseudoDistributeTest/ hadoop jar $HADOOP_HOME/hadoop-examples-1.0.4.jar grep input output 'dfs[a-z.]+' hadoop fs –ls output
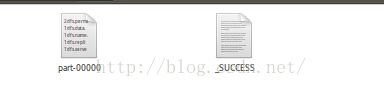
执行正确效果,在HadoopPseudoDistributeTest的目录下有input和output文件夹,output中存放两个文件:
7.12停止daemon
$ stop-all.sh
三、集群配置:
这里讲解一些hadoop的基础知识:Master: NameNode、JobTracker,负责总管分布式数据、分解任务的执行
Slave: DataNode、TaskTracker,负责分布式数据存储、任务的执行
namenode: 接收用户操作请求;维护文件系统的目录结构;管理文件与block之间关系,block与datanode之间关系 主从结构 主节点,只有一个namenode 从节点,有很多个datanodes datanode负责:存储文件;文件被分成block存储在磁盘上;为保证数据安全,文件会有多个副本
JobTracker负责: 接收客户提交的计算任务 把计算任务分给TaskTrackers执行 监控TaskTracker的执行情况
TaskTrackers负责: 执行JobTracker分配的计算任务
Namenode会有一个离线备份:SecondaryNamenode
现在介绍集群分布之前我的环境: 我是把之前一直安装好的ubuntu直接无联系的克隆出来两个ubuntu,也就是说我现在要用三个ubuntu。两个也是可以的。要说明的如果不是克隆出来的,还需要实现几台机器之间ssh登录无密码登录。因为我自己没有做这个不能确保给你们是否正确,可以看看这篇文章的4)如果是为了确保也可以使用克隆的方法。之后尝试ssh 到另两台ubuntu上,不需密码即可,如果需要密码,请重新确保不需密码。
我现在有三台ubuntu,他们的分配:node1:namenode 192.168.231.129
node2:datanode 192.168.231.130
node3:datanode 192.168.231.131
8.1在主目录下创建文件夹HadoopClusterTest,并且如上面7.2中把conf建在这个文件下。
8.2配置conf下的文件:
core-site.xml:ip是node1的。
<span style="font-size:18px;"><!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://192.168.231.129:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/HadoopClusterTest/tmpdir</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration></span></span></span>hdfs-site.xml:
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:14px;"><?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.name.dir</name> <value>/home/hadoop/HadoopClusterTest/tmpdir/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/HadoopClusterTest/tmpdir/hdfs/data</value> </property> </configuration></span></span></span>mapred-site.xml
ip地址改成自己的!!
<span style="font-size:18px;"><span style="font-size:18px;"><span style="font-size:14px;"><?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>192.168.231.129:9001</value> </property> <property> <name>mapred.child.java.opts</name> <value>-Xmx512m</value> </property> <property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>6</value> </property> <property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>2</value> </property> <property> <name>mapred.job.reuse.jvm.num.tasks</name> <value>-1</value> </property> </configuration></span></span></span>master
192.168.231.129
slaves
192.168.231.130
192.168.231.131
8.3用scp命令把HadoopClusterTest拷贝到另外两台ubuntu上:
scp -r /home/hadoop/HadoopClusterTest 192.168.231.130:/home/hadoop/
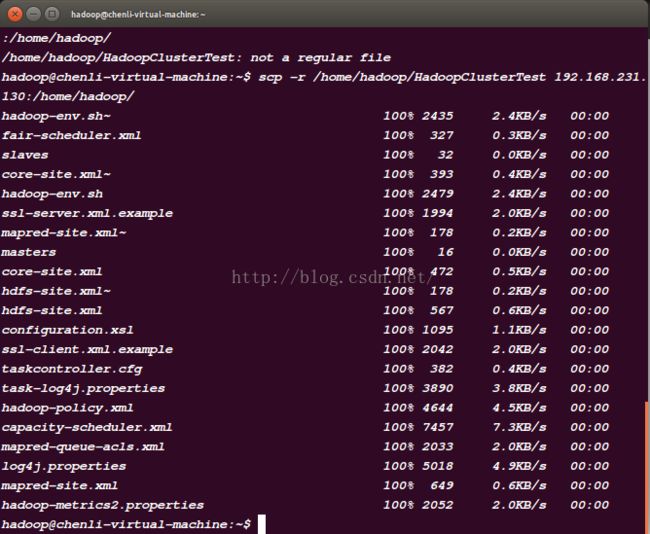
然后改变ip地址用相同命令拷到另一台里。
这样三台电脑的配置就完成了。
下面是它的使用方法(8.9是我后期稍微熟练之后的开启hadoop的方法):
8.4在三个ubuntu都执行:
export HADOOP_CONF_DIR=~/HadoopClusterTest/conf
确保三个ubuntu上HadoopClusterTest都没有的tmpdir文件夹然后执行下面的
8.5在node1上,即我的192.168.231.129上执行【执行之前确保node1,node2,node3上没有tmpdir文件夹,否则启动namenode和datanode会有问题】:
hadoop namenode -format
这时在HadoopClusterTest的目录会有tmpdir文件夹,但是node2和node3没有。
8.6在node1上,即我的192.168.231.129上执行:
$HADOOP_HOME/bin/start-all.sh
然后在node1上执行下面的:
8.7在node1上执行jps查看启动服务:
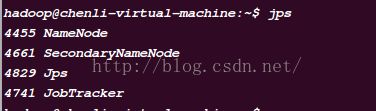
在node2、node3上jps查看:

8.8浏览NameNode和JobTracker的网络接口,它们的地址默认为:
NameNode - http://node1:50070/
JobTracker - http://node1:50030/
我的node1为192.168.231.129
8.9我自己后期开启集群方法:打开三个虚拟机(但其实下面的命令是只在一台虚拟机上执行的)
打开192.168.231.129的终端。依次输入:
ssh 192.168.231.130
export HADOOP_CONF_DIR=~/HadoopClusterTest/conf
ssh 192.168.231.131
export HADOOP_CONF_DIR=~/HadoopClusterTest/conf
ssh 192.168.231.129
export HADOOP_CONF_DIR=~/HadoopCluterTest/conf
$HADOOP_HOME/bin/start-all.sh
hadoop dfs -ls in 列出HDFS下某个文档中的文件
hadoop dfs -put test1.txt test 上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功
hadoop dfs -get in getin 从HDFS获取文件并且重新命名为getin,同put一样可操作文件也可操作目录
hadoop dfs -rmr out 删除指定文件从HDFS上
hadoop dfs -cat in/* 查看HDFS上in目录的内容
hadoop dfsadmin -report 查看HDFS的基本统计信息,结果如下
hadoop dfsadmin -safemode leave 退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式