Hadoop开发周期(四):发布和运行MapReduce
在将MapReduce发布到全发布模式下运行,需要先在单机模式下运行看能否正常通过,以提前发现bug。
1 单机模式
单机模式不需要配置Hadoop文件,关于Hadoop安装见文章Hadoop开发周期(一):基础环境安装 。将编写的MapReduce查询打包,输入一下命令
hadoop jar wordcount.jar input output
说明:wordcount.jar为包含运行作业main函数类的jar包。
以单词统计为例,运行结果文件夹如下
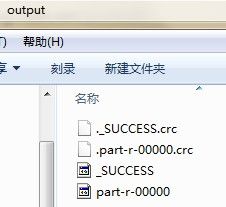
2 全发布模式
2.1 机器分配及用途
NameNode --------------10.3.11.30 (Master--NameNode)
DataNode-1-------------10.3.11.31(Slave1—DataNode)
DataNode-2-------------10.3.11.46 (Slave2—DataNode)
1)设置主机名[root@localhost ~]# vi /etc/sysconfig/network
修改文件内容如下:
NETWORKING=yes NETWORKING_IPV6=no HOSTNAME=NameNode
[root@localhost ~]# hostname NameNode
查看主机名是否修改成功
[root@localhost ~]# hostname
NameNode
2)创建用户hadoop,密码...
[root@NameNode ~]# userdel -r datanode1
[root@NameNode ~]# useradd -m hadoop
[root@NameNode ~]# passwd hadoop
3)IP 地址及别名配置为了能够使用别名来访问服务器,需要在 /etc/hosts 文件中进行 IP 地址及别名对应关系的配置。
[root@NameNode ~]# vi /etc/hosts
10.3.11.11NameNode 10.3.11.12DataNode-1 10.3.11.13 DataNode-2
在从服务器上的 /etc/hosts 文件中的配置如下(以 DataNode-1 为例,DataNode-2 同理):
[root@DataNode-1 ~]# vi /etc/hosts
10.3.11.11NameNode 10.3.11.12DataNode-14)创建/etc/hosts.equiv文件(在3台机器上都要创建)
[root@NameNode ~]# vi /etc/hosts.equiv
NameNode DataNode-1 DataNode-2
在完成上述配置服务器的配置后,在 NameNode上进行 ping DataNode-1 来验证别名与 IP 地址是否已经建立起了对应关系。如果能够拼通则表明配置成功。
[root@DataNode-1 ~]# ping -c 1 DataNode-1
2.2 ssh配置
配置SSH,实现集群节点间账户无密码RSH方式登录(NameNode启动其他服务器上的进程免去登陆这一环节)。配置方法如下:
登入NameNode节点,产生密钥;
将NameNode节点的公开密钥分发到各节点。
1)在~目录下创建文件夹
mkdir .ssh
ssh-keygen -t rsa // 接下来一路回车,则ok
cp id_rsa.pub authorized_keys //进入.ssh目录
3) 分发密钥并将生成的authorized_keys拷贝到所有其他节点下去。
[hadoop@NameNode ~]#scp ~/.ssh/authorized_keys hadoop@DataNode-1:/home/hadoop/.ssh
[hadoop@NameNode ~]#scp ~/.ssh/authorized_keys hadoop@DataNode-2:/home/hadoop/.ssh
在scp过程中会需要你输入密码,输入这一次以后再也不用输入了,这样ssh的无密码登陆就完成了。拷贝完成后,要修改authorized_keys文件的权限:
chmod 755 authorized_keys//在root权限下操作
2.3 在NameNode上部署hadoop
[hadoop@NameNode hadoop-0.20.2]$ viconf/hadoop-env.sh
# Set Hadoop-specific environment variables here. # The only required environment variable isJAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it iscorrectly defined on # remote nodes. # The java implementation to use. Required. # export JAVA_HOME=/usr/lib/j2sdk1.5-sun export JAVA_HOME=/home/hadoop/jdk # Extra Java CLASSPATH elements. Optional. # export HADOOP_CLASSPATH= # The maximum amount of heap to use, in MB. Defaultis 1000. # export HADOOP_HEAPSIZE=2000 # Extra Java runtime options. Empty by default. # export HADOOP_OPTS=-server # Command specific options appended to HADOOP_OPTSwhen specified exportHADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote$HADOOP_NAMENODE_OPTS"
配置slaves 文件,在其中添加有几个数据结点,本文的配置如下所示:
$vi slaves
DataNode-1 DataNode-2配置masters 文件,在其中添加 namenode 结点,本文的配置如下所示:
$vi masters
NameNode
在完成上述配置后,即已经完成了架构的部署。即有一台 master 及多台 slaves 。
配置 core-site.xml 文件
<property>
<name>hadoop.tmp.dir</name> //临时文件目录
<value>/home/hadoop/temp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://NameNode:54310</value> //此处应该是NameNode的别名,一定要加 hdfs://
</property>
配置hdfs-site.xml 文件
<property>
<name>dfs.replication</name> //DFS 备份的文件数目为 2
<value>2</value> //replication 默认为3,如果不修改,datanode 少于三台就会报错
</property>
<property>
<name>dfs.name.dir</name> //DFS 文件目录名字
<value>/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name> //DFS 文件数据
<value>/home/hadoop/hdfs/data</value>
</property>
配置mapred-site.xml 文件
<property>
<name>mapred.job.tracker</name>
<value>NameNode:54311</value> // 此处应该填写 NameNode 的别名
</property>
2.4 在数据节点部署hadoop
前面讲的这么多 Hadoop 的环境变量和配置文件都是在NameNode 这台机器上的,现在需要将 hadoop 部署到其他的机器上,保证目录结构一致。
如果是同构的机器,直接拷贝即可。[hadoop@NameNode ~]$scp -r /home/hadoop/hadoop-1.0.4/ DataNode-1:/home/hadoop/hadoop-1.0.4
$scp -r /home/hadoop/hadoop-1.0.4/ DataNode-2:/home/hadoop/hadoop-1.0.4
如果是异构,JDK环境不一样,需要将JDK的目录弄成一样。将所有节点的JDK目录做符号链接,命令如下:
[hadoop@NameNode ~]$ln –s /home/hadoop/jdk1.6.0_18 /home/hadoop/jdk
[hadoop@DataNode-1 ~]$ln -s /home/hadoop/jdk1.6.0_25 /home/hadoop/jdk
[hadoop@DataNode-2 ~]$ln -s /home/hadoop/jdk1.6.0_25 /home/hadoop/jdk
2.5 启动hadoop
1)格式化 Hadoop
启动之前,我们先要格式化 namenode ,执行下面的命令
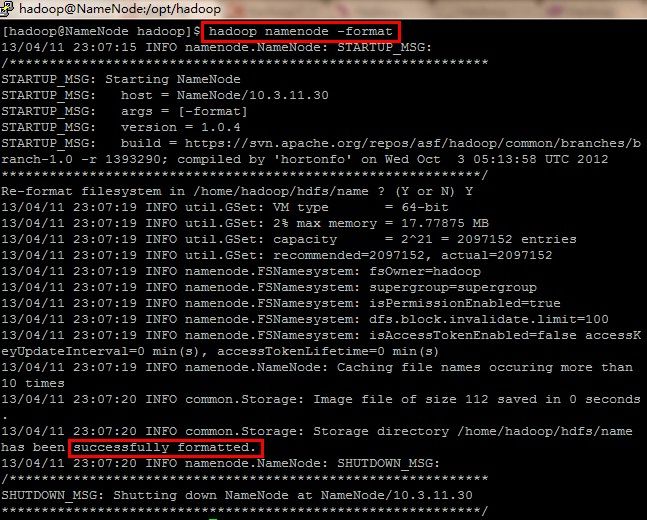
不出意外,应该会提示格式化成功。如果不成功,就去 hadoop/logs/目录下去查看日志文件 . 注意这里的交互式问题一定要输入大写的 Y 。
Warning: Do not format a running cluster because this will erase all existing data in the HDFS filesytem!
To format the filesystem (which simply initializes the directory specified by the dfs.name.dir variable on the NameNode), run the command
Background: The HDFS name table is stored on the NameNode’s (here: master) local filesystem in the directory specified by dfs.name.dir. The name table is used by the NameNode to store tracking and coordination information for the DataNodes.
2)启动hadoop
[email protected]]$ bin/start-all.sh
* start-all.sh 启动所有的 Hadoop 守护进程。包括 namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的 Hadoop
* start-mapred.sh 启动Map/Reduce 守护。包括 Jobtracker 和 Tasktrack
* stop-mapred.sh 停止Map/Reduce 守护
* start-dfs.sh 启动Hadoop DFS 守护 .Namenode 和 Datanode
* stop-dfs.sh 停止DFS 守护
3) 用jps命令查看进程,NameNode上的结果如下
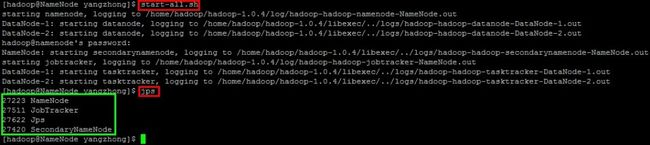
DataNode上的结果如下

在成功启动后,在主服务器上通过如下地址进行访问:
http://10.3.11.30:50070 即可以查看当前有几个数据结点,它们的状态如何。

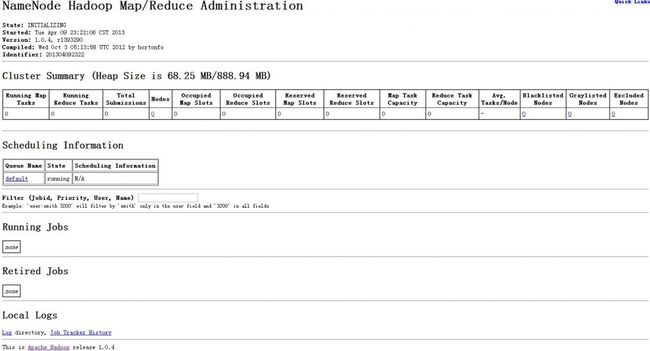
http://10.3.11.30:50030 即可以查看当前的 job 及 Task 的工作状态。
2.6 启动出错处理
见博客Hadoop常见问题总结