1-1、Partitioner 简介
1-1、Partitioner 简介
一、Partitioner简介
Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一个分组的数据交给同一个Reducer处理,它直接影响Reducer阶段的复杂均衡。
Partitioner只提供了一个方法:
getPartition(Text key,Text value,int numPartitions)
前两个参数是Map的Key和Value,numPartitions为Reduce的个数。
源码可以看到是一个抽象类,只包含一个抽象方法:
|
public abstract class Partitioner<KEY, VALUE> {
/**
* Get the partition number for a given key (hence record) given the total
* number of partitions i.e. number of reduce-tasks for the job.
*
* <p>Typically a hash function on a all or a subset of the key.</p>
*
* @param key the key to be partioned.
* @param value the entry value.
* @param numPartitions the total number of partitions.
* @return the partition number for the <code>key</code>.
*/
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
|
Partitioner的工作原理。如下图:
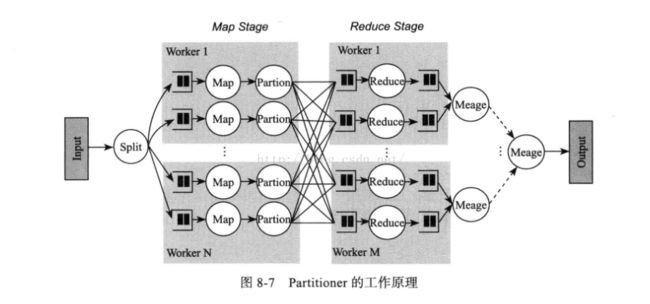
Partitioner有两个功能:
1、均衡负载:尽量将工作均匀地分配给不同的Reduce;
2、效率:分配速度一定要快;
二、MapReduce提供的Partitioner的实现
MapReduce提供了4种Partitioner,默认是HashPartitioner,如下图:
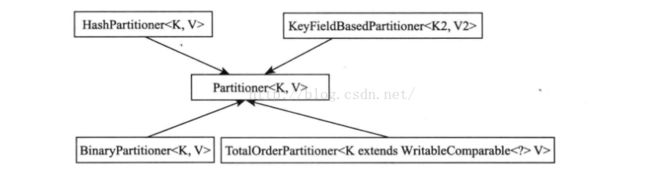
Partitioner是一个基类,如果定制Partitioner需要继承该类:
2.1、HashPartitioner是MapReduce的默认Partitioner:
源码如下所示:
|
/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
|
如源码所示,计算方法为:
which reducer=(key.hashCode() & Integer.MAX_VALUE ) % numReduceTasks
取key的hashCode码与Integer的最大值做按位与运算,得出的结果和Reducer的个数取模,最终将这个Key发送到相应Reducer上面。
Integer.MAX_VALUE表示int类型能够表示的最大值,
.hashCode()表示返回哈希值
.hashCode()表示返回哈希值
&是按位与运算符
2.2、BinaryPartitioner继承于Partitioner<BinaryComparable,V>,是Partitioner的字节码子类。
该类提供 leftOffset 和 rightOffset ,在计算which reducer时,仅对Key-Value中的Key的[rightOffset ,leftOffset ]区间取hash。
which reducer=(hash & Integer.MAX_VALUE) % numPartitions;
部分源码:
|
public class BinaryPartitioner<V> extends Partitioner<BinaryComparable, V>
implements Configurable {
public static final String LEFT_OFFSET_PROPERTY_NAME =
"mapreduce.partition.binarypartitioner.left.offset";
public static final String RIGHT_OFFSET_PROPERTY_NAME =
"mapreduce.partition.binarypartitioner.right.offset";
public static void setOffsets(Configuration conf, int left, int right) {
conf.setInt(LEFT_OFFSET_PROPERTY_NAME, left);
conf.setInt(RIGHT_OFFSET_PROPERTY_NAME, right);
}
public static void setLeftOffset(Configuration conf, int offset) {
conf.setInt(LEFT_OFFSET_PROPERTY_NAME, offset);
}
public static void setRightOffset(Configuration conf, int offset) {
conf.setInt(RIGHT_OFFSET_PROPERTY_NAME, offset);
}
@Override
public int getPartition(BinaryComparable key, V value, int numPartitions) {
int length = key.getLength();
int leftIndex = (leftOffset + length) % length;
int rightIndex = (rightOffset + length) % length;
int hash = WritableComparator.hashBytes(key.getBytes(),
leftIndex, rightIndex - leftIndex + 1);
return (hash & Integer.MAX_VALUE) % numPartitions;
}
}
|
2.3、KeyFieldBasedPartitioner是基于hash的Partitioner。与BinaryPartitioner不同的是,它提供了多个区间用于计算hash。
当区间数为0时,KeyFieldBashdPartitioner就变成了HashPartitioner。
部分源码:
|
public class KeyFieldBasedPartitioner<K2, V2> extends Partitioner<K2, V2>
implements Configurable {
private static final Log LOG = LogFactory.getLog(
KeyFieldBasedPartitioner.class.getName());
public static String PARTITIONER_OPTIONS =
"mapreduce.partition.keypartitioner.options";
private int numOfPartitionFields;
public int getPartition(K2 key, V2 value, int numReduceTasks) {
byte[] keyBytes;
List <KeyDescription> allKeySpecs = keyFieldHelper.keySpecs();
if (allKeySpecs.size() == 0) {
return getPartition(key.toString().hashCode(), numReduceTasks);
}
try {
keyBytes = key.toString().getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("The current system does not " +
"support UTF-8 encoding!", e);
}
// return 0 if the key is empty
if (keyBytes.length == 0) {
return 0;
}
int []lengthIndicesFirst = keyFieldHelper.getWordLengths(keyBytes, 0,
keyBytes.length);
int currentHash = 0;
for (KeyDescription keySpec : allKeySpecs) {
int startChar = keyFieldHelper.getStartOffset(keyBytes, 0,
keyBytes.length, lengthIndicesFirst, keySpec);
// no key found! continue
if (startChar < 0) {
continue;
}
int endChar = keyFieldHelper.getEndOffset(keyBytes, 0, keyBytes.length,
lengthIndicesFirst, keySpec);
currentHash = hashCode(keyBytes, startChar, endChar,
currentHash);
}
return getPartition(currentHash, numReduceTasks);
}
protected int hashCode(byte[] b, int start, int end, int currentHash) {
for (int i = start; i <= end; i++) {
currentHash = 31*currentHash + b[i];
}
return currentHash;
}
protected int getPartition(int hash, int numReduceTasks) {
return (hash & Integer.MAX_VALUE) % numReduceTasks;
}
}
|
2.4、TotalOrderPartitioner类可以实现输出额全排序。不同于以上3个Partitioner,这个类不是基于hash的。
每一个Reduce的输出在默认情况下都是有顺序的,但是Reduce之间在输入是无序的情况下也是无序的。如果要实现输出是全排序的,
就要用到TotalOrderPartitioner。
要使用TotalOrderPartitioner,需要给TotalOrderPartitioner提供一个partition file。这个文件要求key(这些key就是所谓的划分)的数量和当前Reducer的数量减一相同,并且是从小到大排序。
TotalOrderPartitioner对不同的Key的数据类型提供两种方案:
1、对于非BinaryComparable类型的Key,TotalOrderPartitioner采用二分法查找当前的Key所在的index。
例如Reducer的数量是5,partition file提供4个划分为[2,4,6,8]。如果当前的一个Key-Value值是<4,"good">,利用二分法查找到index=1,index+1=2,那么这个Key-Value值将会发送到第二个Reduce。如果一个Key-Value值为<4.5,"good">,那么二分查找将返回-3,同样对-3加一然后取反就是这个Key-Value值将要去的Reducer。 对于一些数值型的数据来说,利用二分法查找复杂度o(log(reducer count))速度比较快。
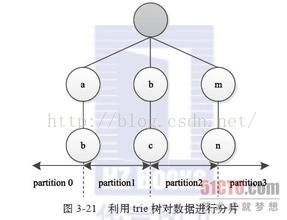
2、对于BinaryComparable类型的key(也可以直接理解为字符串)。字符串按照字典顺序也是可以进行排序的。
这样的话也可以给定一些划分,让不同的字符串Key分配到不同的Reduce里。这里的处理和数值类型比较相近。例如Reducer的数量是5,partition file提供4个划分为["abc","bce","eaa","fhc"],那么"ab"这个字符串将会被分配到第一个Reducer里,因为它小于第一个划分"abc"。但是不同于数值型的数据,字符串的查找和比较不能按照数值型数据的比较方法。MapReduce采用Tire Tree的字符串查找方法。查找的时间复杂度为o(m),m为树的深度,空间复杂度o(255^m-1)。Tire Tree的字符串查找是一个典型的空间换时间的案例。
三、自定义分区
MyPartitionerPar的功能是把Map端输出的Key为"hadoop"发送给reduce-0处理,结果存在part-r-00000里面;Key为"storm"发送给reduce-1处理,结果存在part-r-00001里面;Key为"spark"发送给reduce-2处理,结果存在part-r-00002里面。
四、采集器 Sampler
Hadoop自带的采集器(Sample)也是基于Partitioner实现的,是一种海量数据排序的算法。
Hadoop自带的Sample可以对输入目录下的数据进行采样。提供了如下3种采样方法:

输入采样一般在对海量数据进行排序的时候用的比较多,主要是用来缓解Reduce端的负载均衡,Hadoop自带的1TB的数据排序算法就用到了输入采样Sampler。Hadoop自带的采样方法如下图所示:

InputSampler类实现了三种采样方法:RandomSampler、SplitSampler 和 IntervalSampler。它们都是InputSampler的静态内部类,都实现了InputSampler的内部接口Sampler,接口的方法如下:
public interface Sampler<K,V>{
K[] getSample (InputFormat<K,V> inf ,JobConf job) throws IOException;
}
getSample
方法根据Job的配置信息以及输入格式获得抽样结果,三个采样类各自有不同的实现。
InputSampler 里面的 writePartitionFile方法定义如下:
public static <K,V> void writePartitionFile(JobConf job,org.apache.hadoop.mapreduce.lib.partition.InputSampler.Sampler<K,V> sampler) throws IOException,ClassNotFoundException,InterruptedException
writePartitionFile方法是将采样的结果排序,然后按照分区的个数n,将排序后的结果平均分为n份,取n-1个分割点,这个分割点具体取得时候,运用一些4舍5入得方法,可以理解是取后n-1个组中每组的第一个采样值。