基于MongoDB的php应用开发
转自: http://hi.baidu.com/pc1780/blog/item/6986070885cbcdc563d98636.html
2011-03-10 8:57
|
一、连接数据库主机
连接本地主机,端口为27017:
$connection = new Mongo();
连接远程主机,端口为默认端口:
$connection= new Mongo( "192.168.2.1" );
连接远程主机,端口为指定端口:
$connection = new Mongo( "192.168.2.1:65432" );
选择数据库,如果指定的数据库不存在,则会自动创建一个新的数据库,有2种方法:
$db = $connection->selectDB('dbname');
或
$db = $connection->dbname;
选择集合(collection),与使用关系型数据库中的表类似,有2种方法:
$collection = $db->selectCollection('people');
或
$collection = $db->people;
二、插入新文档(document)
collection对象用来执行信息管理,例如,想存储一个关于某人的信息,可以如下编码:
$person = array(
'name' => 'Cesar Rodas',
'email' => '[email protected]',
'address' => array(
array(
'country' => 'PY',
'zip' => '2160',
'address1' => 'foo bar'
),
array(
'country' => 'PY',
'zip' => '2161',
'address1' => 'foo bar bar foo'
),
),
'sessions' => 0,
);
$safe_insert = true;
$collection->insert($person, $safe_insert);
$person_identifier = $person['_id'];
其中:
$safe_insert参数用于等待MongoDB完成操作,以便确定是否成功,默认值为false,当有大量记录插入时使用该参数会比较有用。
插入新文档后,MongoDB会返回一个记录标识。
三、更新文档
例如,更新上面已经创建的个人信息,增加sessions属性值,在第1个address处增加address2属性,删除第2个address,代码如下:
首先,定义一个filter(过滤器)告诉MongoDB要更新一个指定的文档
$filter = array('email' => '[email protected]');
$new_document = array(
'$inc' => array('sessions' => 1),
'$set' => array(
'address.0.address2' => 'Some foobar street',
),
'$unset' => array('address.1' => 1),
);
$options['multiple'] = false;
$collection->update(
$filter,
$new_document,
$options
);
MongoDB也支持批量更新,与关系型数据库类似,可以更新给定条件的所有文档,如果想这么做的话,就需要设置options的multiple的值为true.
四、查询文档
定义一个符合给定标准的条件过滤器,通过使用查询选择器来获取文档。
例,通过e-mail address来获取信息:
$filter = array('email' => '[email protected]');
$cursor = $collection->find($filter);
foreach ($cursor as $user)
{
var_dump($user);
}
例,获取sessions大于10的信息:
$filter = array('sessions' => array('$gt' => 10));
$cursor = $collection->find($filter);
例,获取没有设置sessions属性的信息:
$filter = array(
'sessions' => array('$exists' => false)
);
$cursor = $collection->find($filter);
例,获取地址在PY并且sessions大于15的信息:
$filter = array(
'address.country' => 'PY',
'sessions' => array('$gt' => 10)
);
$cursor = $collection->find($filter);
有一个重要的细节需要注意,只有当需要结果的时候查询才会被执行,在第1个例子中,当foreach循环开始时,查询才被执行。
这是个很有用的特性,因为这可以通过在游标(cursor)中增加选项来取回结果,恰好在定义查询后,执行查询前这个时刻。例如,可以设置选项来执行分页,或者获取指定数目的匹配的文档。
$total = $cursor->total();
$cursor->limit(20)->skip(40);
foreach($cursor as $user) {
}
五、获取文档的聚类
MongoDB支持结果的聚类,类似于关系数据库,可以使用count,distinct和group等聚类操作。
聚类查询返回数组(array),而不是整个文档对象。
分组操作允许定义用Javascript编写的MongoDB服务器端功能,该操作执行分组属性。因为可以执行许多带有分组值的操作类型,所以会更灵活,但是相比SQL执行例如SUM(),AVG()等
简单的分组操作来说,这还是有些困难。
下面这个例子演示了如何获取国家的的地址列表,以及匹配地址的国家出现的次数:
$countries = $collection->distinct(
array("address.country")
);
$result = $collection->group(
array("address.country" => True),
array("sum" => 0),
"function (obj, prev) { prev.sum += 1; }",
array("session" => array('$gt' => 10))
);
六、删除文档
删除文档与获取或更新文档很类似。
$filter = array('field' => 'foo');
$collection->remove($filter);
要注意,默认所有符合条件的文档都会被删除,如果只想删除符合条件的第1个文档,那么在给remove函数的第二个参数赋值为true。
七、索引支持
有一个很重要的特点,使得决定选择MongoDB,而不是选择其它的类似的面向文档的数据库,这个特点就是对索引的支持,这和关系型数据库的表索引很类似,并不是所有的面向文档的数据库都
提供内置的索引支持。
使用MongoDB的创建索引功能可以避免在查询期间在所有文档中进行操作,这就象关系数据库中使用索引来避免全表查询一样。这可以加速那些涉及到索引属性的符合条件的文档的查询。
例如,如果想在e-mail地址属性上建立唯一的索引,如下所示:
$collection->ensureIndex(
array('email' => 1),
array('unique' => true, 'background' => true)
);
第1个数组参数描述将要成为索引的所有属性,可以是1个或多个属性。
默认情况下,索引的创建是一个同步操作,所以,如果文档数目很大的话,把索引的创建放在后台运行会是个好主意,就象上面例子所演示的。
只有一个属性的索引可能不够用,下面这个例子演示如何通过在2个属性上定义索引来加速查询。
$collection->ensureIndex(
array('address.country' => 1, 'sessions' => 1),
array('background' => true)
);
每个索引的值定义了索引的顺序:1表示降序(descending),-1表示升序(ascending)
索引顺序在有排序选项的查询优化中是有用的,如下例所示:
$filter = array(
'address.country' => 'PY',
);
$cursor = $collection->find($filter)->order(
array('sessions' => -1)
);
$collection->ensureIndex(
array('address.country' => 1, 'sessions' => -1),
array('background' => true)
);
八、实际应用
一些开发人员可能害怕使用一种新型的数据库,因为它和他们以前工作中用过的那些不同。
在理论上学习新事物不同于在实践中学习如何使用,所以,这部分内容将通过比较基于SQL的关系型数据库,比如MySQL,来解释如何用MongoDB来开发实际应用,这样就可以熟悉这两种途径
的不同。
例如,我们将构建一个blog系统,有用户,提交和评论功能。在使用关系型数据库的时候,你可以象下面这样通过定义表模式来实现它。
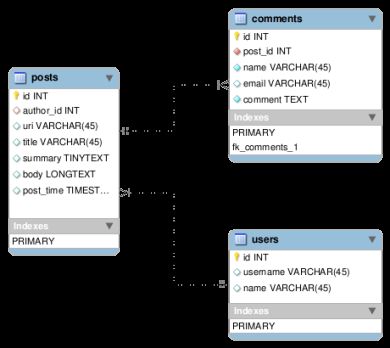
在MongoDB中实现同样的文档定义如下:
$users = array(
'username' => 'crodas',
'name' => 'Cesar Rodas',
);
$posts = array(
'uri' => '/foo-bar-post',
'author_id' => $users->_id,
'title' => 'Foo bar post',
'summary' => 'This is a summary text',
'body' => 'This is the body',
'comments' => array(
array(
'name' => 'user',
'email' => '[email protected]',
'content' => 'nice post'
)
)
);
你可能注意到,我们只用一个文档就代替了posts和comments两个表,这是因为comments是post文档的子文档。这样做使实现更简单,在你想存取发布内容和它的评论时,会节省查询数据库的时间。
为了更简洁,用户所做评论的细节可以和评论的定义合并,所以你可以用一个查询来获取所发布的内容,评论和用户这些信息。
$posts = array(
'uri' => '/foo-bar-post',
'author_id' => $users->_id,
'author_name' => 'Cesar Rodas',
'author_username' => 'crodas',
'title' => 'Foo bar post',
'summary' => 'This is a summary text',
'body' => 'This is the body',
'comments' => array(
array(
'name' => 'user',
'email' => '[email protected]',
'comment' => 'nice post'
),
)
);
这意味着会存在一些重复信息,但现在磁盘空间比CPU的RAM要便宜得多,以空间换时间,网站访问者的耐心和时间更重要。如果你关注重复信息的同步,那么在更新author信息的时候,你可以执行下面这个更新查询来解决这个问题。
$filter = array(
'author_id' => $author['_id'],
);
$data = array(
'$set' => array(
'author_name' => 'Cesar D. Rodas',
'author_username' => 'cesar',
)
);
$collection->update($filter, $data, array(
'multiple' => true)
);
以上是我们对数据模型的转换和优化,下面将重写一些用在MongoDB中的和SQL等价的查询。
SELECT * FROM posts
INNER JOIN users ON users.id = posts.user_id
WHERE URL = :url;
SELECT * FROM comments WHERE post_id = $post_id;
首先,增加索引:
$collection->ensureIndex(
array('uri' => 1),
array('unique' => 1, 'background')
);
$collection->find(array('uri' => '<uri>'));
INSERT INTO comments(post_id, name, email, contents)
VALUES(:post_id, :name, :email, :comment);
$comment = array(
'name' => $_POST['name'],
'email' => $_POST['email'],
'comment' => $_POST['comment'],
);
$filter = array(
'uri' => $_POST['uri'],
);
$collection->update($filter, array(
'$push' => array('comments' => $comment))
);
SELECT * FROM posts WHERE id IN (
SELECT DISTINCT post_id FROM comments WHERE email = :email
);
首先,增加索引:
$collection->ensureIndex(
array('comments.email' => 1),
array('background' => 1)
);
$collection->find( array('comments.email' => $email) );
九、用MongoDB存储文件
MongoDB也提供许多超过基本数据库操作的特点。例如,它提供了在数据库中存储小文件和大文件的解决方案。
文件被自动分块(块)。如果MongoDB运行在自动分片(auto-sharded)环境,文件块也会被跨多个服务器复制。
有效地解决文件的存储是一个相当困难的问题,尤其是当你需要管理大量的文件时。把文件保存在本地文件系统中通常不是个好的方案。
一个困难的例子是YouTube必须有效地服务那些上百万视频的小图片,或者由Facebook为数十亿图片提供的高效运行服务。
MongoDB通过创建两个内部集合(collections)来解决这个问题:文件集合保存关于文件元数据的信息,块集合保存关于文件块的信息。
如果你想存储一个大的视频文件,你可以使用如下这样的代码:
$metadata = array(
"filename" => "path.avi",
"downloads" => 0,
"comment" => "This file is foo bar",
"permissions" => array(
"crodas" => "write",
"everybody" => "read",
)
);
$grid = $db->getGridFS();
$grid->storeFile("/file/to/path.avi", $metadata);
正如你所看到的,这很简单且容易理解。
十、Map-Reduce
Map-Reduce是一种处理大量信息的操作手段。map操作应用于每个文档并产生一套新的key-value数据对。reduce操作使用map功能产生的结果并产生基本每个key的单一结果。
MongoDB Map-Reduce功能可以应用到集合上用于数据转换,这和Hadoop很类似。
当map处理完成后,结果被保存并且通过键值(key value)被分组。对每个结果键(key),使用2个参数来调用reduce功能:键(key)及其所有值的数组。
为了更好地理解它的工作原理,我们假设有了前面定义过的blog的提交文档,接下来你想使每个提交的内容有一系列的tag,如果你想获得关于这些tag的统计情况,你只需要像下面这样计算一下即可:
首先定义map和reduce功能代码,
$map = new MongoCode("function () {
var i;
for (i=0; i < this.tags.length; i++) {
emit(this.tags[i], {count: 1});
}
}");
$reduce = new MongoCode("function (key, values) {
var i, total=0;
for (i=0; i < values.length; i++) {
total = values[i].count;
}
return {count: total}
}");
然后执行map-reduce命令:
$map_reduce = array(
'out' => 'tags_info',
'verbose' => true,
'mapreduce' => 'posts',
'map' => $map,
'reduce' => $reduce,
);
$information = $db->command($map_reduce);
var_dump($information);
如果MongoDB运行在切片(sharded)环境,那么这个数据处理功能将会在所有shard节点上并行。
要知道执行map-reduce处理通常是很慢的。它的目的是把大量的数据分布在许多服务器上。所以,如果你有许多服务器,你就可以把这个操作分布在这些服务器上进行处理并获得结果,这会比在一台服务器上运行所需的时间要少得多。
建议在后台运行map-reduce处理,因为它们需要花比较长的时候才能完成。在这种情况下,如果通过Gearman来异步管理启动它是个不错的方法。
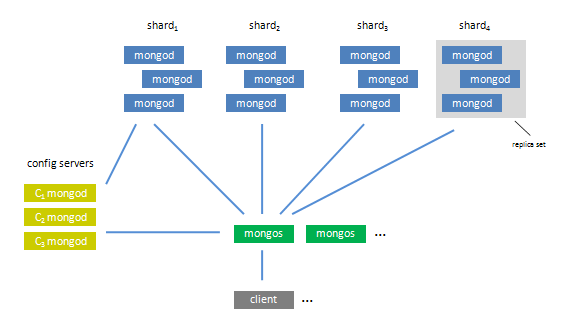
十一、Auto-sharding
在前面多次提到sharding,但你可能并不熟悉这个概念。
Data sharding是一种把数据分布在多个服务器上的数据库技术手段。
MongoDB只需要很少的配置就可完成auto-sharding。然而,安装和配置一个shard已超出本文章的范围。
下面这张图展示了工作在shard环境中的MongoDB,这样你会在你使用sharding时都发生了什么有个了解。
十二、其它
正则表达式使用面面的格式:
"/<regex>/<flags>"
和SQL语句中的 username LIKE '%bar%'等价的方式如下:
<?php
$filter = array(
'username' => new MongoRegex("/.*bar.*/i"),
);
$collection->find($filter);
?>
在使用Regex时要小心,大多时候它不能使用索引,因此它将对整个数据扫描,所以比较好的方法是对文档的数目进行限制。
<?php
$filter = array(
'username' => new MongoRegex("/.*bar.*/i"),
'karma' => array('$gt' => 10),
);
$collection->find($filter);
?>
使用Regex可以完成如下这个复杂的查询:
<?php
$filter = array(
'username' => new MongoRegex("/[a-z][a-z0-9\_]+(\_[0-9])?/i"),
'karma' => array('$gt' => 10),
);
$collection->find($filter);
?>
|