结合linux功能实例理解软中断、tastlet以及工作队列
本文基于Linux2.6.32内核版本。
软中断、tasklet和工作队列并不是Linux内核中一直存在的机制,而是由更早版本的内核中的“下半部”(bottom half)演变而来。下半部的机制实际上包括五种,但2.6版本的内核中,下半部和任务队列的函数都消失了,只剩下了前三者。
介绍这三种下半部实现之前,有必要说一下上半部与下半部的区别。
上半部指的是中断处理程序,下半部则指的是一些虽然与中断有相关性但是可以延后执行的任务。举个例子:在网络传输中,网卡接收到数据包这个事件不一定需要马上被处理,适合用下半部去实现;但是用户敲击键盘这样的事件就必须马上被响应,应该用中断实现。
两者的主要区别在于:中断不能被相同类型的中断打断,而下半部依然可以被中断打断;中断对于时间非常敏感,而下半部基本上都是一些可以延迟的工作。由于二者的这种区别,所以对于一个工作是放在上半部还是放在下半部去执行,可以参考下面四条:
a)如果一个任务对时间非常敏感,将其放在中断处理程序中执行。
b)如果一个任务和硬件相关,将其放在中断处理程序中执行。
c)如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行。
d)其他所有任务,考虑放在下半部去执行。
有写内核任务需要延后执行,因此才有的下半部,进而实现了三种实现下半部的方法。这就是本文要讨论的软中断、tasklet和工作队列。
下表可以更直观的看到它们之间的关系。
(一)软中断
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet(请读者在遇到的时候根据上下文推断是否包含tasklet)。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
a)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
b)可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
(1) 相关数据结构
软中断描述符
<span style="white-space:pre"> </span>struct softirq_action{ void (*action)(struct softirq_action *);};软中断全局数组和类型
<span style="white-space:pre"> </span>static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
enum
{
HI_SOFTIRQ=0, /*用于高优先级的tasklet*/
TIMER_SOFTIRQ, /*用于定时器的下半部*/
NET_TX_SOFTIRQ, /*用于网络层发包*/
NET_RX_SOFTIRQ, /*用于网络层收报*/
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /*用于低优先级的tasklet*/
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};
(2) 相关API
注册软中断(注意:同一类型软中断可同时在多个cpu上运行这是与tasklet的区别)
void open_softirq(int nr, void (*action)(struct softirq_action *))
触发软中断
void raise_softirq(unsigned int nr)( 3)实现原理和实例
流程如下所示:
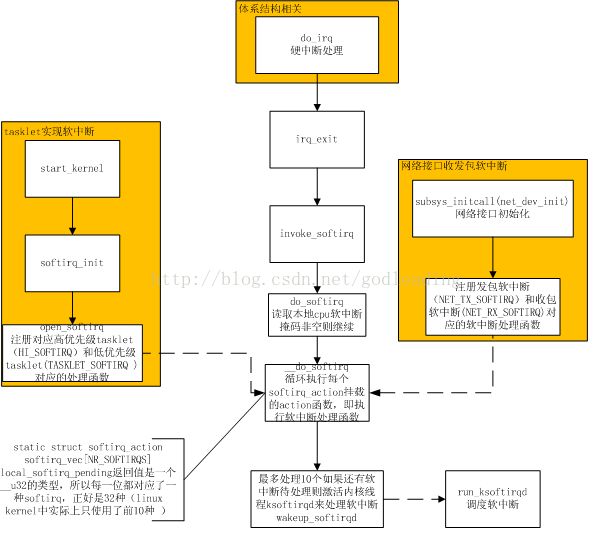
(二)tasklet
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
a)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
b)多个不同类型的tasklet可以并行在多个CPU上。
c)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
(1)相关数据结构
tasklet描述符
<span style="white-space:pre"> </span>struct tasklet_struct
<span style="white-space:pre"> </span>{
struct tasklet_struct *next;//将多个tasklet链接成单向循环链表
unsigned long state;//TASKLET_STATE_SCHED(Tasklet is scheduled for execution) TASKLET_STATE_RUN(Tasklet is running (SMP only))
atomic_t count;//0:激活tasklet 非0:禁用tasklet
void (*func)(unsigned long); //用户自定义函数
unsigned long data; //函数入参
<span style="white-space:pre"> </span>};(2)相关API
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)初始化tasklet t
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data } 定义名字为name的激活和非激活tasklet。
static inline void tasklet_disable(struct tasklet_struct *t)函数暂时禁止给定的tasklet被tasklet_schedule调度,直到这个tasklet被再次被enable;若这个tasklet当前在运行, 这个函数忙等待直到这个tasklet退出
static inline void tasklet_enable(struct tasklet_struct *t)使能一个之前被disable的tasklet;若这个tasklet已经被调度, 它会很快运行。tasklet_enable和tasklet_disable必须匹配调用, 因为内核跟踪每个tasklet的"禁止次数"
static inline void tasklet_schedule(struct tasklet_struct *t)调度 tasklet 执行,如果tasklet在运行中被调度, 它在完成后会再次运行; 这保证了在其他事件被处理当中发生的事件受到应有的注意. 这个做法也允许一个 tasklet 重新调度它自己
<pre name="code" class="cpp">static inline void tasklet_hi_schedule(struct tasklet_struct *t)和tasklet_schedule类似,只是在更高优先级执行。当软中断处理运行时, 它处理高优先级 tasklet 在其他软中断之前,只有具有低响应周期要求的驱动才应使用这个函数, 可避免其他软件中断处理引入的附加周期
<pre name="code" class="cpp">void tasklet_kill(struct tasklet_struct *t)确保了 tasklet 不会被再次调度来运行,通常当一个设备正被关闭或者模块卸载时被调用。如果 tasklet 正在运行, 这个函数等待直到它执行完毕。若 tasklet 重新调度它自己,则必须阻止在调用 tasklet_kill 前它重新调度它自己,如同使用 del_timer_sync
(3)实现原理和实例
流程图如下所示:
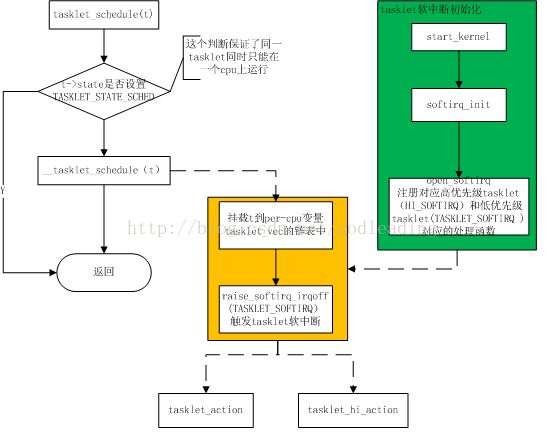
(三)工作队列
从上面的介绍看以看出,软中断运行在中断上下文中,因此不能阻塞和睡眠,而tasklet使用软中断实现,当然也不能阻塞和睡眠。但如果某延迟处理函数需要睡眠或者阻塞呢?没关系工作队列就可以如您所愿了。
把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ,而工作线程就是负责执行工作队列中的工作。系统默认的工作者线程为events。
工作队列(work queue)是另外一种将工作推后执行的形式。工作队列可以把工作推后,交由一个内核线程去执行—这个下半部分总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。最重要特点的就是工作队列允许重新调度甚至是睡眠。
通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则: 如果推后执行的任务需要睡眠,那么只能选择工作队列; 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时(内核定时器实现); 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程,同时不可睡眠; 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
(1)相关数据结构
正常工作结构体
struct work_struct {
atomic_long_t data; //传递给工作函数的参数
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; //链表结构,链接同一工作队列上的工作。
work_func_t func; //工作函数,用户自定义实现
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
延迟工作结构体(延迟的实现是在调度时延迟插入相应的工作队列)
struct delayed_work {
struct work_struct work;
struct timer_list timer; //定时器,用于实现延迟处理
};
工作队列结构体
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq; //指针数组,其每个元素为per-cpu的工作队列
struct list_head list;
const char *name;
int singlethread; //标记是否只创建一个工作者线程
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};每cpu工作队列(每cpu都对应一个工作者线程
worker_thread)
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
} ____cacheline_aligned;
(2)相关API
1.创建工作队列
静态创建
DECLARE_WORK(name,function); //定义正常执行的工作项
DECLARE_DELAYED_WORK(name,function);//定义延后执行的工作项
动态创建
INIT_WORK(_work, _func) //创建正常执行的工作项
INIT_DELAYED_WORK(_work, _func)//创建延后执行的工作项
工作队列执行函数的原型:
void (*work_func_t)(struct work_struct *work);该函数会由一个工作者线程执行,因此其在进程上下文中,可以睡眠也可以中断。但只能在内核中运行,无法访问用户空间。
2)调度默认工作队列
int schedule_work(struct work_struct *work)对正常执行的工作进行调度,即把给定工作的处理函数提交给缺省的工作队列和工作者线程。工作者线程本质上是一个普通的内核线程,在默认情况下,每个CPU均有一个类型为“events”的工作者线程,当调用schedule_work时,这个工作者线程会被唤醒去执行工作链表上的所有工作。
系统默认的工作队列名称是:keventd_wq,默认的工作者线程叫:events/n,这里的n是处理器的编号,每个处理器对应一个线程。比如,单处理器的系统只有events/0这样一个线程。而双处理器的系统就会多一个events/1线程。
默认的工作队列和工作者线程由内核初始化时创建:
start_kernel()-->rest_init-->do_basic_setup-->init_workqueues
int schedule_delayed_work(struct delayed_work *dwork,unsigned long delay)对延时执行的工作进行调度。
void flush_scheduled_work(void)刷新缺省工作队列。此函数会一直等待,直到队列中的所有工作都被执行。
static inline int cancel_delayed_work(struct delayed_work *work)flush_scheduled_work并不取消任何延迟执行的工作,因此,如果要取消延迟工作,应该调用cancel_delayed_work。
以上均是采用缺省工作者线程来实现工作队列,其优点是简单易用,缺点是如果缺省工作队列负载太重,执行效率会很低,这就需要我们创建自己的工作者线程和工作队列。
3)自定义工作队列
create_workqueue(name) //宏定义 返回值为工作队列,name为工作线程名称</span>创建新的工作队列和相应的工作者线程,name用于该内核线程的命名。
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
类似于schedule_work,区别在于queue_work把给定工作提交给创建的工作队列wq而不是缺省队列。
int queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork, unsigned long delay)调度延迟工作。
void flush_workqueue(struct workqueue_struct *wq)刷新指定工作队列。
void destroy_workqueue(struct workqueue_struct *wq)释放创建的工作队列。
(2)实现原理
流程图如下:
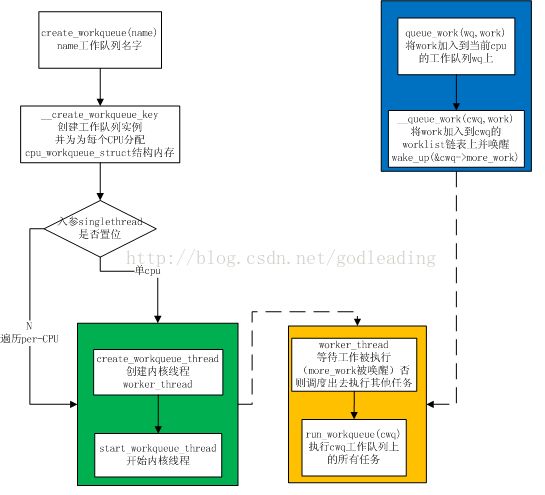
未完待续...
功能实例:
linux各个接口的状态(up/down)的消息需要通知netdev_chain上感兴趣的模块同时上报用户空间消息。这里使用的就是工作队列。具体流程图如下所示: