linux情景分析第二章-----存储管理(2)
2.4越界访问
linux中的虚拟地址通过PGD,PTE等映射到物理地址。但当这个映射过程无法正常映射时候,就会报错,产生page fault exception。那么什么时候会无法正常呢?
- 编程错误。程序使用了不存在的地址
- 不是编程错误,linux的请求调页机制。即:当进程运行时,linux并不将全部的资源分配给进程,而是仅分配当前需要的这一部分,当进程需要另外的资源的时候(这时候就会产生缺页异常),linux再分配这部分。
编程错误linux肯定不会手软的,直接弄死进程。请求调页机制,linux会申请页的。
当MMU对不存在的虚拟地址进行映射的时候,会产生异常,__dabt_usr: __dabt_svc。 他们都会调用do_DataAbort。
__dabt_usr: usr_entry kuser_cmpxchg_check @ @ Call the processor-specific abort handler: @ @ r2 - aborted context pc @ r3 - aborted context cpsr @ @ The abort handler must return the aborted address in r0, and @ the fault status register in r1. //说明了调用do_DataAbort时候传递给他的参数。 r0,r1, @ #ifdef MULTI_DABORT ldr r4, .LCprocfns mov lr, pc ldr pc, [r4, #PROCESSOR_DABT_FUNC] #else bl CPU_DABORT_HANDLER #endif @ @ IRQs on, then call the main handler @ enable_irq mov r2, sp //参数r2 adr lr, ret_from_exception b do_DataAbort //调用do_DataAbort ENDPROC(__dabt_usr)
do_DataAbor根据川进来的参数调用 inf->fn ,在这里就是 do_page_fault
asmlinkage void __exception
do_DataAbort(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
const struct fsr_info *inf = fsr_info + (fsr & 15) + ((fsr & (1 << 10)) >> 6);
struct siginfo info;
if (!inf->fn(addr, fsr, regs))
return;
printk(KERN_ALERT "Unhandled fault: %s (0x%03x) at 0x%08lx\n",
inf->name, fsr, addr);
info.si_signo = inf->sig;
info.si_errno = 0;
info.si_code = inf->code;
info.si_addr = (void __user *)addr;
arm_notify_die("", regs, &info, fsr, 0);
}
do_page_fault函数是页异常的重要函数:
ps:因为在,__dabt_usr: __dabt_svc这两种情况下都会调用do_DataAbort函数,然后调用do_page_fault,所以调用do_page_fault可能是在内核空间,也可能是在用户空间。在内核空间可能会是 进程通过系统调用,中断等进入的,也可能进程本来是内核线程。所以在do_page_fault中要行进判断的。到底是从哪里发生的异常。
一下函数的分析大部分参考了《深入linux内核》书中的 第9章。
static int __kprobes //__kprobes标志应该是调试的一种东西,等以后再专门研究一下。
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk;
struct mm_struct *mm;
int fault, sig, code;
if (notify_page_fault(regs, fsr)) //这个函数是专门和上面的__kprobes对应的,调试的东西
return 0;
tsk = current;
mm = tsk->mm; //将出现页异常的进程的 的进程描述符 赋给tsk,内存描述符赋给mm
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
if (in_atomic() || !mm) //判断发生发生异常的,in_atomic判断是否是在 原子操作中:中断程序,可延迟函数,禁用内核抢占的临界区。 !mm 判断进程是否是内核线程。参照博客线程调度的文章。
goto no_context; //如果缺页是发生在这些情况下,那么就要特殊处理,因为这些程序都是没有用户空间的,要特殊处理。
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
if (!down_read_trylock(&mm->mmap_sem)) {
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
down_read(&mm->mmap_sem);
} //down sem,没啥说的。
fault = __do_page_fault(mm, addr, fsr, tsk); //下面分析。
up_read(&mm->mmap_sem);
/*
* Handle the "normal" case first - VM_FAULT_MAJOR / VM_FAULT_MINOR
*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0; //如果返回值不是上面的值。那么就是MAJOR MINOR,说明问题解决了,return,如果是,那么还要go on
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
if (!user_mode(regs))
goto no_context; //如果是内核空间出现了 页异常,并且通过__do_page_fault没有没有解决,那么到on_context
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, or some other thing
* happened to us that made us unable to handle
* the page fault gracefully.
*/
printk("VM: killing process %s\n", tsk->comm);
do_group_exit(SIGKILL);
return 0;
}
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to
* successfully fix up this page fault.
*/
sig = SIGBUS;
code = BUS_ADRERR;
} else {
/*
* Something tried to access memory that
* isn't in our memory map..
*/
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
} //这上面的英文描述很清楚了
__do_user_fault(tsk, addr, fsr, sig, code, regs); //用户态错误,这个函数什么都不做,就是发个新号,弄死进程
return 0;
no_context:
__do_kernel_fault(mm, addr, fsr, regs); //内核错误,这个函数什么都不干,发送OOP:::啊啊啊 啊啊啊,这个警告曾经弄死多少好汉
return 0;
}
static int
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct task_struct *tsk)
{
struct vm_area_struct *vma;
int fault, mask;
vma = find_vma(mm, addr); //find_vma函数是从mm结构中找到一个vm_area_struct结构,这个结构的vm_end值 > 参数addr, 但是vm_start可能大于也可能小于,但fing_vma会尽可能找到小于的。即:addr在vma这个区间中。
fault = VM_FAULT_BADMAP;
if (!vma) //如果vma为0,那么想当于所有vma的vm_end地址都 < 参数addr,这个产生异常错误的地址 肯定是无效地址了。 因为根据进程的结构,如上图,所有vm中vm_end的最大值是3G。
goto out;
if (vma->vm_start > addr) //如果vm_start>addr,说明这个异常的地址是 图中 的那个 空洞中,那么则可能是在用户态的栈中出错的。则跳去 check_stack
goto check_stack;
/*
* Ok, we have a good vm_area for this
* memory access, so we can handle it.
*///如果上面条件都不是,那么得到的vma结构就包含 addr这个地址。有可能是malloc后出错的。 用户态下的malloc时候,其实并不分配物理空间,只是返回一个虚拟地址,并产生一个vm_area_struct结构,当真正要用到malloc的空间的时候,才会产生异常,在这里得到真正的物理空间。 当然也有可能是其他原因,比如在read only的时候进行write了。
good_area:
if (fsr & (1 << 11)) /* write? */ //fsr从第一段的汇编中得出意义,他是r1.状态。 这里看地址异常时候 是写还是其他。并复制到mask中
mask = VM_WRITE;
else
mask = VM_READ|VM_EXEC|VM_WRITE;
fault = VM_FAULT_BADACCESS;
if (!(vma->vm_flags & mask))
goto out; //如果是写,但是vma->vm_flag写没有set 1,说明的确是权限的问题,那么就set fault的值,退出。
/*
* If for any reason at all we couldn't handle
* the fault, make sure we exit gracefully rather
* than endlessly redo the fault.
*/
survive: //上面原因都不是,那么就给进程分配一个新的页框。成功返回VM_FAULT_MAJOR(在handle_mm_fault中得到一个页框时候出现了阻塞,进行了睡眠)/VM_FAULT_MINOR(没有睡眠)
fault = handle_mm_fault(mm, vma, addr & PAGE_MASK, fsr & (1 << 11));
if (unlikely(fault & VM_FAULT_ERROR)) {
if (fault & VM_FAULT_OOM) //返回OOM,没有足够的内存。 到out_of_memory中,sleep一会,retry。
goto out_of_memory;
else if (fault & VM_FAULT_SIGBUS)
return fault;
BUG();
}
if (fault & VM_FAULT_MAJOR)
tsk->maj_flt++;
else
tsk->min_flt++;
return fault;
out_of_memory:
if (!is_global_init(tsk))
goto out;
/*
* If we are out of memory for pid1, sleep for a while and retry
*/
up_read(&mm->mmap_sem);
yield();
down_read(&mm->mmap_sem);
goto survive;
check_stack:
if (vma->vm_flags & VM_GROWSDOWN && !expand_stack(vma, addr)) //检查堆栈,进行expand,扩展原来的栈的vma,然后goto good_area,去得到一个实际的物理地址。
goto good_area;
out:
return fault;
}
进程的用户空间结构:
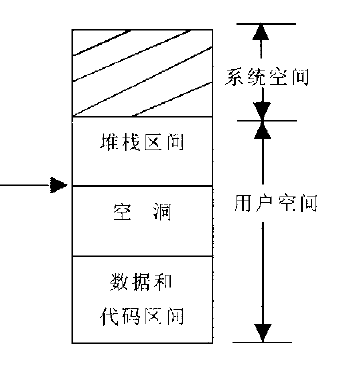
图上面的堆栈空间个人感觉不对,堆是堆,栈是栈, 准确的说应该是栈吧、、。。堆会在brk()函数中设置的。
这样分析之后基本上2.4和2.5节的内容已经全包含了,下面总结扩展并补充一下下:
- 当发生页面异常时候,会产生中断,当在用户态时候,会产生,__dabt_usr: 在内核态时__dabt_svc。但他们都会调用到do_DataAbort函数,do_DataAbort会根据中断的寄存器调用相应的处理函数。这里产生页面中断时候,会调用do_page_fault函数。
- 在do_page_fault函数中,首先会检查中断发生时,是不是在临界区,或者中断中,或者内核线程中。 如果是的话,那么就产生个OOPs。 因为这些地方是不允许异常的。如果异常会产生阻塞,阻塞就会死锁。死锁程序员就会被弄,被弄了程序员就发过来弄linux,所以linux就先弄了程序员,发出OOPs错误。
- 如果不在临界区中,那么调用__do_page_fault函数。这个函数会先检查 产生异常的地址,是不是进程的已有的线性空间中,即检查vm_area_struct的list中。
- 如果在的话,检查是不是因为 权限的问题产生的异常,如果是,那么说明应用程序是有问题的,直接弄死他。 如果不是,有可能是写时复制等一些linux机制。调用handle_mm_fault函数,进行分页等。
- 如果不在vm_area_struc的list中,如果大于所有的vm_area_struct的vm_end,那么说明是错误的地址,也是直接弄死。 如果有小于<vm_end,也小于vm_start,那么说明是在空洞中,应该是栈的问题,去申请更多的栈空间。(为什么<vm_end&&<vm_start就是在栈中,因为malloc等都是事先分配个vm_area_struct结构,当异常时,会找到相应的vm_area_struct结构的。如果找不到,那就是在栈里面了溢出了)。
下面再说handle_mm_fault函数:
- 他会首先 检查是否已经存在了PTE等映射,如果不在alloc 所有的 PUD,PMD,PTE等,建立映射。然后调用handle_pte_fault函数。注意:由于有些在刚建立的pte,所有pte里面全是0,有些是以前是建立好的,所以里面pte里面不是0,可能有其他值。所以下面还会做判断。
- handle_pte_fault函数会判断具体缺页的类型,具体分为3类, 会根据这三类调用不同的函数。具体调用的函数,以后再说吧。。。。。
- 1.这个页从来没有被访问过,也就是这个pte中全是0,pte_none这个宏返回1
- 2.以前访问过这个页,但这个页是非线性磁盘文件的映射,即:dirty位 置1, pte_file返回1
- 3. 以前访问过这个页,但内容已经被保存在磁盘上了,即:dirty位 0
下图是 understand linux kernel书中的一个图,中文图在中文书中的P378

2.6 物理页面的使用和周转
2.8 页面的定期换出
2.9 页面的换入
这三节都是讲的页框的回收和释放内容。
具体代码太难太难,简要介绍原理,尽可能是解释代码吧。
(参考书籍:《深入理解linux内核》17章 《Professional Linux Kernel Architecture》Chapter 18)
深入理解linux内核》讲的2.6内核,但有点老,有些函数对不上。 《professional linux kernel architecture》是新版(2.6.24)的linux介绍。但是于2.6.39相比也有点对不上。![]()
页框回收算法(page frame reclaiming algorithm,PFRA)
页框回收算法,是回收一些物理内存页。 在两种情况下会触发这个算法,
1, 当进行alloc_page时等申请内存时,但内存中空闲的page已经不够了。就会触发PFRA去回收一些页。得到更多的free的page。
2, 如果仅仅在第1个条件才触发PFRA,那alloc_page函数就会等待很长时间。所以,linux会创建一个kswapd内核线程。会定期的被唤醒去调用PFRA算法,尽量去保证linux有较多的物理内存空间。不会低于high_wmark_pages。
那么去回收那些页呢?PFRA会将“很久”不用的页reclaim到硬盘/flash上,然后释放这个页。对于页被reclaim到硬盘/flash的哪个位置?PFRA进行了分类:不可回收页,可交换页,可同步页,可丢弃页。
- 不可回收页,包括:本来就是空闲的页,内核空间使用的页,临时锁定的页。内核空间的页linux认为会比较频繁,也比较重要,不会reclaim。
- 可同步页。如一些打开的文件,过mmap映射到内存的占用的页。这样的页本来在硬盘中就有备份。所以系统只需要查看这些页是否被修改过,如果被修改过,就将其写到硬盘上,然后reclaim,如果没有被修改过,那么直接reclaim。
- 可交换页。这些页是对应于这2种页的。包括:用户进行的malloc的页,或者和其他进程共享的页等。这些页在硬盘上没有对应的区域,所以要想将其写到硬盘上,就要有一个 交换区(swap区),内核会将其写到 这个交换区。然后再reclaim。
- 可丢弃页。如:slab机制保留的未使用的页,文件系统目录项等的一些缓存的页。这些页可以直接丢弃。
那么如何判断页是否“很久”没有用呢?有个LRU()算法。

在zone这个结构体中,会有一些list:
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct zone_lru {
struct list_head list;
} lru[NR_LRU_LISTS];
用来连接这个zone中的各个不同状态的页。
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
LRU_INACTIVE_ANON 和LRU_ACTIVE_ANON对应于匿名页,就是上面说的可交换的页。 LRU_INACTIVE_FILE 和 LRU_ACTIVE_FILE对应于可同步页。LRU_UNEVICTABLE应该指不可回收的页。
讲解一下上图中相关的一些知识:
首先两个方框表示两个list,一个active,一个inactive。从了在zone的这个list中可以找到active的页,也可以从page这个结构体中检查。当page结构体中的 flag这个成员变量,flag&PG_active ==1时,page对应的页是active的,如flag&PG_active ==0,则是inactive的。
在每个方框中,也有两个部分,Ref0和Ref1。他代表页是否刚被访问过。如:当一个进程访问一个页时候,就会调用mark_page_accessed函数,这个函数将这个页的page结构的flag变量 flag |= PG_reference;这样标志页刚刚被访问过。但linux的kswap进程会扫描所有页,将 flag &= ~PG_reference;标志页有一段时间没有被访问过了。这样如果在Ref0中停留过长时间的话,就会调用shrink_active_list函数将这个页移动到inactive list中。
下面介绍回收的流程:

上图就是介绍的两个shrink memory的方法。一个是当alloc_page内存不够时,直接direct page reclaim。 一种是swap daemons。
当然他们shrink的强度是不一样的,direct page reclaim是紧急情况的,必须要回收到的。而swap daemons是尽量回收,保留更多的内存空间。所以在try_to_free_pages在调用shrink_zones函数中会传入个priority,这个priority代表shrink的强度,priority会不断减一,强度越来越大。直到释放了足够的alloc_page的空间。如果priority减到0了,还不能shrink足够的空间。那么就是调用out_of_memory函数,来kill 进程,释放空间。
在进行shrink_page_list中,会根据相关的页进行不同的设置。如:
如当shrink LRU_INACTIVE_ANON 里的page的时候,就会将所有对应这个页的页表(PTE)的present位和dirty位请0.但是其他位不为0. 其他位标志了这个页所在的swap区的位置(此时pte里的值已经不是页表信息了,而是表示这个页保存在磁盘的地址。具体意义可看《深入理解linux内核》的710页,换出页标识符)。
当shrink LRU_INACTIVE_FILE 里的page的时候,就会将所有对应这个页的页表(PTE)的present位请0,但dirty位置一.由于这些页在磁盘上本来就是有对应的文件的,所以不需要记录他的具体问题,linux可以找到。
所以就有了上面讨论缺页异常时候,读页的那三个函数。和判断。。。。。。![]()
在上面提到过,将所有对应于该页的pte,由于对应于一个页,可能会有不止一个的PTE映射在这个页上,那么如果通过这个page结构体来找到对应的所有的pte呢?这个机制叫反响映射,在《深入理解linux内核》的回收页框的 674页,反向映射。
终于写完了·······