重组标签云-标签聚类及其评价研究
重组标签云-标签聚类及其评价研究
AlbertoPérez García-Plaza a*, Arkaitz Zubiaga b, Víctor Fresnoa,Raquel Martínez a
a NLP&IR Group, UNED Madrid, Spain
b Queens College and Graduate Center, City University of New York,New York, NY, USA
摘要
发现标签云中标签之间的语义关系并将其可视化可以增强用户体验,特别是在社会标签系统中访问和检索的网页。目前这些系统中的标签的关系已经有一些可视化方法。然而,先前的研究结果依赖于定性评价方法,并且没有提供健壮的和噪声可比的标准。为了支持定量评价我们提供了一个基准的社会标签数据集,它包含140个标签子集,来源于知名社会书签网站delicious,并且已经根据开放式目录(ODP)手动分类。这个手动分类使得定性评价可以作为一个基准,提供一种方法来推断不同聚类方法中最好的一种。在这组数据上,我们探索了不同的标签表示方法,提出利用自组织映射重组标签云的方法。此外,我们提出一个方法利用最大特征词丰富每个标签和标签组的合成标签云,通过标签和文档内容进一步过滤导航并缓和更深层次的定性评价聚类簇。
关键词
社会标签 大众分类法 聚类 自组织特征映射 资源 评价
1引言
社会化书签是一个社会媒体的应用程序,成功地成为一种缓解信息搜索和共享的手段。社会化书签网站允许用户用标签协同标记他们喜欢的网页。得益于这种协作哲学,大型社区的用户提供大量的标签聚合在web页面上,产生巨大的标注集有利于改善信息管理任务(Heymann, Koutrika, 和 Garcia-Molina,2008; Sun, Wang, Sun, 和 Lin, 2011; Zheng 和 Li, 2011).
__________
对应作者的电话号码: +34 91 398 79 57;传真: +34 91 398 65 35.
电子邮箱地址: [email protected] (A.Pérez García-Plaza), [email protected] (A. Zubiaga), [email protected] (V.Fresno), [email protected] (R.Martínez).
不同于传统分类法预定义类目,社会书签系统依赖于非控词汇,生产的标记集是无限制的。这一特性带来的灵活性也使得研究社区的信息组织和访问更具挑战性。在这些系统中,网页上标注的标签集随着标注数量的增长越来越具有代表性(Zubiaga,Martínez, 和 Fresno, 2009b)。此外,当一个信息需求可以被定义为一个信息检索方法中的查询时,在社会书签网站中信息需求是一个由用户提供的标签,用以获取与这个标签相关资源的有序列表。之后,系统提供一个相关标签的列表,允许在他的收藏中导航。但这不是在这些系统获取信息唯一的方法。
为了可以可视化浏览,社会书签系统通常提供一个成为称为标签云的接口模型。这些云的一个主要方法浏览和发现社交书签系统中的web文档,作为一个结构,提供了集合中最受欢迎主题的一个视觉总结。标签云由网站上最受欢迎的50到200标签组成,越受欢迎的标签,字体大小越大。有时,标签是按照字母顺序排列的,随机的或使用其他非语义序列。因此,一个开放的问题是确定在标签云中内在关联的标签和他们之间的关系,以提高社会标签系统的浏览阶段。这是本文的主要目的之一。
最近的研究都集中在获得进一步组织标签云中的标签,通过考虑标记之间的语义关系。在这项工作中,我们关注一个标签云的语义重组,基于使用聚类技术识别内在相关的标签组。尽管对这个任务的兴趣有所增加,但是比较不同标签的性能表示却没有成效,并且实验的分析和评价仅限于定性标准。
据我们所知,没有一个黄金标准来评估语义标签聚类,并且用于评估不同的方法的数据集都彼此不同。尽管他们中的一些来自相同的社会标签系统,爬行的标准(时间、框架、大小等)后续过滤或减少标准(频率、统一的形态变化,标记用户数量等)有所不同。在本文中,我们提出一个社会书签网站的定量标记聚类评价指标集合。我们手动分组标记的文档集合,使外部评估和比较不同的标签聚类方法。
此外我们建议我们分组标签云的浓缩借助最相关的术语列表以及相关的个性话标签和标签组,所以它更容易建立和和分析标记之间和它们相关的网页内容的语义关系。相关术语提取借助应用于文档内容的语言模型技术。因此,强化标签云变成了一个更丰富的,它提供了一个更通用的方式来可视化和浏览标签和术语,这个增强的标签云的目的是提高在社会标签网站的广义上的信息访问。
除此之外,该标签云浓缩方法允许我们进行定性分析标签及其相关的文本内容的一致性。它还允许社会标签网站推荐相关的标签,以及改善标记集订阅服务等任务。
本文的其余部分组织如下。接下来,在第二节中,我们提供社会书签系统的相关背景。在第三节中,我们总结这个领域相关的早期研究的。在第四节中,我们继续描述和分析的社会标签数据集,以及展示评估基准的创建过程。在第五节中,我们提出的不同的方法重组标签云。在第六节,继续通过描述定量评价措施,并呈现和分析其结果。在第七节,我们展示了一个依靠术语的增量定性评估方法,第八节,总结本文。
2 社会化书签
在社交书签系统中,标签是一个开放方式将标签分配给网页以便以后检索。在实践中,用户注释资源往往提供不同的标签,所以,聚集他们的注释结果更具代表性。例如,一个用户可以标记本文为社会化标签、集群、评价和delicious而另一个用户可以使用论文、研究和标签来标注。作为社区注解网页的结果,整个用于这个网站的标签集就建立了一个基于标签的组织系统,这就是所谓的大众分类法。大众分类法也被称为一个以社区为基础的分类,它的经典模式就是没有层次性,标签的词汇是开放的,到这种程度用户可以自由地定义自己的标记。
在社会书签系统中,有一组用户(U),他使用注释标记(T) 给资源(R)发布书签(B)。每个用户可以使用一组标签为资源发布一条书签,变量p表示标签数。当用户发布了,它可以使用一组带权标签集来描述,其中 表示特定标签分配的权重。总之,每个书签就是一个包含用户、标签集和资源的三元组:。这样,每个用户保存不同资源的书签,每个资源拥有来自不同用户标注的书签。一个用户整合书签中的标签的结果就认为是用户的一次个人分类:,其中m表示用户个人分类中不同标签的数量。
社会书签网站的性质提供多方面的积极方面,例如:(i)因为不同用户标注相同的来源,标签的权重可以由一致意见推断,(ii)词汇的开放性允许用户创建非现有标签涌现出与时事或个人需求相关词汇。
然而,另一方面,词汇的开放性带来了几个问题,如:(i)不同的标签可以同义词或相关(例如,照片和摄影),(ii)不同标签有不听的特征级别可能就是上位词/下位词(例如,编程和java),(iii)标记也可以有多种解释的(例如,图书馆,这可能意味着一个包含书籍的地方和子程序的集合),(iv)标记的目的可以是任何事实(例如,设计),主观标记(例如,有趣的),或个人标记(例如,要读)(Sen等,2006)。从社会书签系统的开放词汇出现的问题使标签的管理更具挑战性,强烈地需要一个方法来更好地处理标签。尽管这项工作没有对上面的问题进行特殊处理,但是实验的分析可以进一步了解为什么他们发生和什么时候发生
3相关工作
随着社会标签系统的出现和流行,发现在社会标签中的语义关系的兴趣越来越高(Garcia-Silva, Corcho, Alani, 和 Gomez-Perez, 2011),提出了不同的方法。最近,Dattolo、Eynard Mazzola(2011)提出一种方法检测类似的标签组和它们之间的关系。作者应用聚类过程发现相关标签的不同类别,提出三种方法计算一个图中标签的重量权重:他们的研究结果表明,使用规范化的交集(标签之间的共现率)Jaccard系数(标准化的共现率)以及一个更加复杂的方法考虑标签在向量空间额外的分配措施。他们对减化的前20位的标签集只执行一个定性评估,一组模糊的标签,和个主观标记集。他们的研究结果表明,使用规范化的同现加权系数(Jaccard)返回更好的结果比交集(绝对共现):标签是不那么受欢迎,但仍然共享在子社区内,往往排名更高的暴露他们感兴趣的领域的典型词汇表。
Vandic, van Dam, Hogenboom, and Frasincar (2011)提出一个方法来提高搜索社会标签系统通过集聚相同意义标签的句法变种。他们使用基于同现向量的余弦相似度测量的语义相似度。他们的句法聚类方法错误率低于早先的由Specia and Motta (2007)介绍的通过使用结合浅预处理的策略和统计技术加之语义网上提供的本体技术的方法。更加特别地,其他作者表明他们关心通过标签云提高导航。Deutsch, Schrammel, and Tscheligi (2011)提出通过标签云中的标签簇可以提高用户体验。他们研究了标签云在普通web上下文中的优势和缺点。他们也分析可视化标签云语义聚类的不同方法,但是他们没有对其提供任何比较评价。Venetis、Koutrika Garcia-Molina(2011)提供了一个分析算法选择将在标签云中展示的标签。他们通过假设一个理想的用户模型评估标签云由不同的算法。然而,他们没有提供任何聚类方法,显示附近的有关标记。
至于标记表示方法,很多的工作考虑标签之间的共现,另外小部分依靠标记文档的文本内容。
一些方法使用标记共现应用图论聚类算法来组织相关标签组In man Au Yeung, Gibbins, and Shadbolt (2007),一旦一个标注的资源图建立好。其边被定义为资源的共享标签。这个图是后来分裂为资源和相关标签的聚类。为了消除标签模糊含义必须和几个主题相关。 Begelman, Keller, and Smadja (2006)建立了一个无向图表示标签空间,其中节点与标签对应,边表示共现标签频次。这个由共现标签对构建的标签空间更多的依赖频次而不是预期,通过查找截点(标签词对被认为是强相关的)。作者使用基于谱平分算法获得相关标签聚类簇。Karydis, Nanopoulos, Gabriel, and Spiliopoulou(2009)聚焦谱聚类算法研究了相似图每个项目与他的k个近邻(k-NN)相联系并且将每个项目与由相似图特征向量定义的特征空间相映射。他们构建拉普拉斯张量并且在特征空间中分解为运行一个K-means算法。这种方法应用于标注过的音乐信息,并且分化为用户-项目-标签关系。
标签共现也被应用于生成相关标签子树。Schmitz (2006)提出一个基于由共现标签派生的包容模型,其中共现标签通过从flickr网站的标签用法总结出的分面本体获得。在这个案例中,标签共现模型用来定义当标签X潜在的属于标签Y。Wu, Zhang, and Yu (2006)使用在可能生成模型中的共现标签、资源和用户信息来自动派生标签的浮现语义。他们定义一个多维的概念空间,其中每个维度代表一个不一样包含社会标注数据的知识类别。这种概念空间帮助消除模糊标签,并且在概念上分组同义标签。他们将这个模型应用于语义检索和发现系统中。Mika (2007)使用共现信息发现一个语义上相关的集群集。在他的概念示例图中边的权重就是标签的共现数。他使用三元图模型涉及用户(行为者)、标签(概念)和资源(概念和对象的实例)并且建立图与标签、用户以及带标签的资源相关联。然后,他应用网络分析技术发现的标记集集群。Specia and Motta(2007)的聚类过程是基于由共现关系得到的很多相似标签,其中整个标签集中的一个标签被表示为一个交集。在这个工作中作者设想标签空间和通过探索在线本体浓缩语义关系。Angeletou, Sabou,Specia, and Motta (2007)的工作基于Specia and Motta (2007)的工作,也是依赖于网络本体获取大众分类法标记浓缩的语义。作为隐式相关标签的输入集群。
文本内容也被认为可以代表和发现内在相关的的标签。Brooks and Montanez (2006) 基于赋权重的词频使用TF-IDF关键词权重函数分析了文档相似度。他们使用平均成对cosine相似度的方法和一个分块算法将文档中得标签共享到类簇中,然后比较了一个类簇中所有文档的相似度。Zubiaga, García-Plaza, Fresno, and Martínez (2009a)提出一套方法使用自组织图来获得和可视化相关标签云,其中标签间的关系展示时算作标注文档的文本内容。尽管组合出来的标签云是有很好的,但是我们不能比较基于表现的内容和基于表现的其它共现内容。这些问题将在以后的工作中处理。
关于标签可视化,最常用的方法就是创建标注数据的可视化的定向表现,主要由使用标签作为检索面和标签云组成。可视化是信息空间导航阐释语义不同质化的一个常用的重要的方法。一些作者也发现标签云缺乏有意义的空间解释。例如,Hassan-Montero andHerrero-Solana (2006)使用二分K-means算法组织每个标签的相似标签。一个可选的解决办法是用来增加标签云间的相互作用,例如,当悬浮于一个标签之上时将会高亮显示其余标签中的相似标签以支持对不同标签间联系的理解。
在本文中,除了其余的聚类算法,自组织组被用来聚类相关标签。SOMs算法比其他算法的优点在于聚类步骤自己产生一个大众分类法的文本图。其他的像基于图聚类的可视化方法,例如Simpson (2008)提出的也被用来产生一个标签的可视化图,但是这些图太过复杂,有很多的边并且需要高消耗的布局算法。SOMs算法的可视化能力可以提供一个直观的方法来展示数据的分布和对象的相似度。Sbodioand Simpson (2009)使用SOM方法对标签聚类,基于标签的共现展示标签。一旦,图训练好,作者就使用它来对新的标注文档分类,但是没有提出定量的评估方法。
Risi, Lehwark, and Ultsch (2008)使用SOM和U-Map技术来对Last.fm网站上标注的音乐数据可视化和聚类。这项工作,依靠标注模式来发现标签间的关系。例如,他们将包含“rock”的标签集合起来。Chen, Santaía, Butz, and Therón (2009).做了一个相似的工作,他们都采用标签共现的方法和其他的措施,例如TF-IDF权重函数、欧式距离以及cosine相似度计算标签语义相关度。但是,他们的方法不是自动的而是人工参与的,并且他们人工的定义将被聚类的相似词语。所以,他们的系统不能容易的更新和聚类标签云。其他的工作如Li and Zhu (2008), Gabrielsson (2006)使用自组织图来发现标签关系。
至于评价过程,(Markines et al., 2009)依靠Wordnet作为语义标准来计算标签相似度。尤其是他们使用了Jiang–Conrath距离(Jiang 和 Conrath, 1997)排序标签对,这个距离结合了分类学的和信息论的知识。然而,作者也展示了Bibsonomy上的一个有限的Wordnet数据其中有29%的标签有重叠。类似的,Cattuto, Benz, Hotho, and Stumme (2008)显示了一个delicious的有61%重叠标签的Wordnet。和(Markines et al., 2009)不同的是我们的测试标准提供了标签云中所有标签的类别,还考虑了在Wordnet中没有实例的标签。
我们的工作首先提出并分析一个定量评估方法允许进一步的比较不同的聚类和标签展示方法。我们介绍一个基础的社会化标注数据集带有热门标签的人工分类,并且使用了额外的评价方法作为数据集的实验集。我们还演示了一个基于语言模型技术的定量评估来提取每个标签和标签组的术语相似度。这些技术不仅允许对生成的云进行深入的纯正的分析,还可以为用户提供有用的信息加强用户访问标签云提供的信息的能力。
4 deliciousT140数据集
评价标签聚类算法释义个开放的问题,因为没有一个基础数据集有一个理想的解决方法来比较不同聚类系统的查询。我们的工作提供了这样一个基础数据集,可以把它作为标签聚类任务的“黄金标准”。除此之外,我们对文档和标注数据提出了一个人工标注的分类体系,其中每个标签都被划分到一个包含24个类目的分类体系中。当其他的工作还在使用定性评价方法评估结果时,我们推荐的基准数据集也可以提供定量评估方法。
4.1采集带标注的网页
我们从delicious网上采集了2008年6月份的网页文档和它们对应的标注数据集。我们从网站提供的140个最流行标签开始,这就是一个完整标签云(以下称为T140)。然后,我们T140中每个标签下的网址,获得379931个唯一的URL。基于这个URL列表我们查询delicious获得发布每个URL的用户数量,以及他们给热门标签的权重列表。这样,每个URL就附加到k个标注者和一个权重标签列表,其中n最多是25,由社会化书签系统书签生成的时间所限制。除了这些delicious上的社会化书签之外,我们还爬取按了那些URL以获取他们的HTML内容。
一旦我们下载了这些内容和标注数据,我们就把采集的结果过滤为英文文档。这就得到144574个文档和67104个不同的标签。这些数据2可以作为标签聚类评价的一个基础数据集。
4.2生成一个标签聚类的基础数据集
为了展示人工的组织情况,我们依据著名的统一的分类体系开放目录系统(ODP)3由两名技术人员根据标签与ODP中一个类目的相似性独立地组织T140中的标签。这个人工组织的执行是在两个交互影响的过程之下的。第一种交互影响是考虑到ODP的顶级类目。这两个技术人员人工地为T140中的每个标签分配ODP前16顶级类目中的一个,操作步骤如下:(1)他们将每个标签作为ODP检索框中的一个查询词;(2)如果技术人员统一第一级目录就和标签最匹配那就把这个标签划分到此类目中,否则,技术人员会建议另外一个统计类目给这个标签;(3)两个技术人员都标注了这140个标签之后,他们碰面讨论他们的决定,并最终生成一份标签人工组织。
技术人员使用了12个顶级类目,还增加了一个杂录类,然后,结果就是:艺术、商业、计算机、游戏、健康、家庭、科学、新闻、娱乐、参考、社会、购物和其他。这个人工组织的结果显示了计算机类目和其余的类目不平衡,因为此类包含了140个标签中的64个。这个事实清晰地展示了集合对计算机话题的偏好。这个也是为什么技术人员不用计算机这个顶级类目而使用二级子类目的原因。
____________
2http://nlp.uned.es/social-tagging/delicioust140/.
3 http://www.dmoz.org/ –ODP 是一个人工编辑的网页目录,由全球的志愿者参与编辑
这样在人工组织的第二次循环中计算机就被分成很好粒度的类目。技术人员把计算机的子类目划分给标签的过程跟第一次循环是一样的。
一些标签和ODP中的类目有很高的匹配值但是被划分到不同的类目中。比如,标签“生产力”按照ODP来说应该属于计算机,但是我们的技术人员都认为他应该属于商业类目。其他例子如标签“政治”与ODP中的区域类目最匹配但是被划分到社会类目下。同样的情况还有19个标签:net, 2008, article,articles, book, books, cool, environment, design, diy, food, green,images, politics, productivity, social, teaching, visualization, 和 work。另外,考虑到集合中计算机话题的偏好做了以下的一些分配改变:libbrary, tool 和 tools 标签被认为是程序设计类目;audio, music, video 和 videos被移动到多媒体类目中;tech被移到科学类目中。表1显示了最终的24个类目的人工组织情况。
注意到大多数情况下,技术人员是认可ODP建议的最大频次类目的。然而,我们认为这个人工类目的提供,通常上,一个好的基准数据中标签是单义的或者他们只常用它最常用的含义。然而,当标签是多义的或者被用在专业领域时,这个人工的分类体系可能产生一个好的组织像一个错误一样计算。
表1 :140个标签的最终人工类目
| 类目 |
标签 |
|
|
| 艺术 (17) |
architecture art au culture design english fic illustration inspiration movies photo photography photos portfolio tv typography writing |
|
|
| 商业 (11) |
advertising business economics fashion finance jobs marketing productivity resources socialmedia work |
|
|
| 操作系统(4) |
linux ubuntu windows osx |
|
|
| 多媒体(8) |
audio video videos images mp3 music youtube flickr |
|
|
| 程序设计(16) |
ajax.net css database java javascript jquery language library php programming python rails ruby tool tools |
|
|
| 互联网(22) |
blog blogging blogs email firefox flash flex google internet socialnetworking twitter web web2.0 webdesign webdev wiki collaboration development search seo wordpress online |
|
|
| 图像(4) |
3d graphics photoshop visualization |
|
|
| 系统(4) |
apple computer iphone mac |
|
|
| 软件(7) |
download free freeware howto software tutorial tutorials |
|
|
| 硬件(1) |
Hardware |
||
| 手机(1) |
Mobile |
||
| 开源(1) |
opensource |
|
|
| 性能(1) |
performance |
|
|
| 安全(1) |
Security |
||
| 游戏(2) |
game games |
|
|
| 健康(1) |
Health |
||
| 家庭(8) |
cooking diy food home lifehacks recipe recipes tips |
|
|
| 新闻(4) |
article articles media news |
|
|
| 旅行(4) |
fun funny humor travel |
|
|
| 参考(7) |
book books education learning reference research teaching |
|
|
| 科学(5) |
environment math science technology tech |
|
|
| 购物(2) |
shop shopping |
|
|
| 社会(5) |
community green history politics social |
|
|
| 其他(4) |
2008 cool toread interesting |
|
|
5标签云再组织
在这部分,我们描述了标签展示方法。我们使用实验和自组织图聚类算法来研究。
5.1标签表示
大多数展示标签的方法都是基于标签共现的。我们知道,基于标签共现的表示方法和其他的基于标注文档的文本内容展示的方法不能比较。这两种方法的核心是同一种类的信息,但它们以不同的方式强调。一方面,都考虑到文档的内容,一种是显示的(基于内容),另一种是隐式的(基于共现),因为考虑到标注文档内容中标签共现的假设关系。在另一方面,都使用标签共现数据,一种是隐式的(基于共现),另一种是显示的(基于内容),因为考虑到文本比一个考虑到共现信息的标签的隐式方式更能参与到文档的表示。
本文,我们尝试上面描述的这两种方法表示标签,来重组标签云:使用标签共现以及文本内容来表示。在每个方面我们都使用向量空间模型(VSM)。我们的研究使用了我们的基础数据集比较并评估了这两种方法。
5.1.1使用标签共现来表示
用户标注当前的兴趣特征用标签表示。当一个用户标注一个文档,标签中隐含的语义就分配给文档内容了。我们只考虑流行标签(只考虑标签云中的140个)我们可以认为用户标注的标签是集聚的,并且这些标签是最适合他们所表现的文档的。所以我们考虑用户提供的分类信息,用这种方法我们可以说我们建立了一个基于人类知识的标签表示。而且,这个分类是有大量用户完成的。因此,如果我们发现两个很高的标签标注了统一文档那么我们就可以认为文档的内容跟这两个标签都相关。这样的话,如果发现一些文档中的标签共现关系借助我们数据集中足够大数据量的文档,我们就可以总结出那些现存标签之间的关系。由于这个事实,那些系统使用者使用它们来标注同一个文档。从这个假说中我们可以表示我们标签共现的主要假设为:由同一个标签标注的文档的数量越多,这些标签的相似度就越大。
基于这些思想,我们提出四种不同的标签权重计算函数。除了标签共现之外,用户标注数量也被考虑在我们的模式之内。我们用它来选择相关标签来确认标签的集收敛。对每个标签,我们都建立了一个向量表示他和T140内其余标签的共现度。这样我们就获得了140维的140个向量,对应每个标签。因此,没个维度对用不同的T140标签,并且这个组分的值集,也就是以后的标签权重,测量了标签共现程度对应这个组分和向量表示的标签。公式(1)显示了一个标签向量是怎么组织的:
表示对应的向量,表示标签之间的权重。这样,标签向量对应的全集(140维)构成了下面的矩阵:
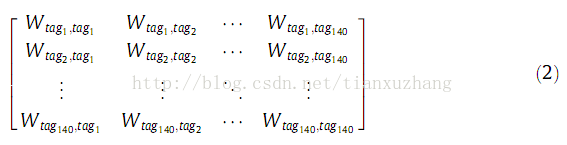
到这里我们使用表现出来的标签定义了一个向量空间。我们也讨论了用来构建向量的权重函数和我们考虑选择他们的主要思想。我们考虑了三种主要的特征由“由同一标签标注的文档数量”结合起来:(1)标签之间最小文档频次;(2)标签之间的最大文档频次;(3)至少有一个标签标注的文档数量。我们结合了这三个权重来定义四个不同的权重函数:
两个标签的交叉文档频次(如公式3所示):数据集中有统一反而标签标注的文档频次的绝对值。在这个案例中,我们直接使用前面用公式表示的主要假说。这个函数对不同的数据集是不正常的,并且这个值在数据集中不是相对的而是绝对的。
![]()
关于那些标签联合的文档频次的两个标签的交叉文档频次(如公式4所示):这个函数表示Jaccard相似系数。如果两个标签有很高的Jaccard分值,他们就可能总是在数据集中作为一个对共现,并且一个标签不会再另一个标签不出现的时候出现。这个函数也假设这个主要的假说,但是不在这个案例中。这个值会随着由这些标签标注的文档数量的而尺度下降。Jaccard相似系数出现在几个标签聚类研究中,像Simpson (2008), Sbodio and Simpson (2009)这也是为什么我们将这个权重函数考虑到我们的基础数据集中的原因。然而,它是不是合适和其他方法比较还没有被证明。在这些工作中我们也想看看Jaccard相似系数是不是适合这项工作。

关于两个标签之间的最小文档频次的交叉文档频次(如公式5所示):
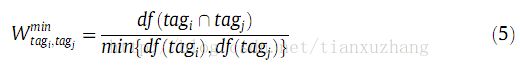
在这个情况中,我们使用数据集中的每个标签的最小标注文档频次来调整值,在这种方法中,由交叉值相连的最小共同标签标记的文档数量越多,她的权值就越小。这个函数也假定之前的假设,但是在这种情况下值会随着由最小共同标签标注的文档数量而尺度下降的。
关于两个标签之间的最大文档频次的交叉文档频次(如公式6所示):
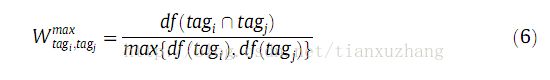
我们使用数据集中的每个标签的最大标注文档频次来调整值,在这种权重函数中,我们再次假定初始的假设。但是不同于第一个步骤,值会随着由最大共同标签标注的文档数量而尺度下降的。
我们还想标注一下,这四个结果矩阵中的每一个都采用四种方法中的一种来计算标签的权重并表示整个标注数据集。概念地,两个标签的共现频次应该像权重那样增长。
5.1.2用文档内容来表示
为了用内容来表示标签,我们考虑被标注的文档。特别地,我们限制是文本内容。因为,每个标签都有很多文档标注,所以,我们整合所有那些潜在的文档的文本内容。这个方法首先由Zubiaga et al. (2009a)介绍的。
然而,我们想再文档表示中不应该用同样的方法来总结所有的标签,它们中的一些可能几乎不重要,因为它们只有很少的标注数量,也因为联系的计算开销。为了决定哪个标签被看做是跟文档相关的,我们需要设置一个阈值;这种方法中,只有标签的标注数量高于阈值才会被选择。我们考虑平均标注数量(26)来推测集合中每个和像我们临界值的每个单独文档的平均值(见图1)。从此,只用最高排序的标签发现文档内容的语义和发现T140集合中标签的关系就会变得很清晰。
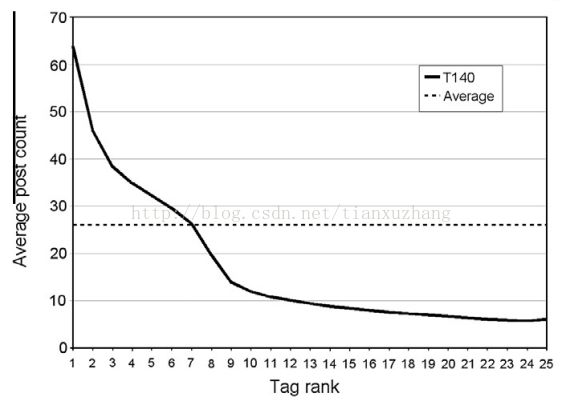
图1:X轴代表标注资源热门标签列表中标签的排序,Y轴代表每个序号的标签的标注数量。注意排名首位的标签和从资源到资源是不同的。虚线表示从第一个到第25个标签的平均标注数量。总的来说,只有拥有比平均值(虚线以上)高标注数量的标签才会使用文档内容表示。
然后,T140中的每个标签是由它对应的文档表示的,而不是每个都表示成文档向量,我们整合所有文档与其对应的独有标签(以后我们称之为超文档)。这样,我们就获得了140个超文档来表示T140中的标签。然后一个文档就会属于多于1个超文档(如果他被T140中1个以上标签标注了),文档可能表示多于一个标签,所以我们可以考虑白哦前共现信息作为一种隐式的方法。
下一步,就是讲超文档表示在向量空间模型中。首先,我们除去HTML标签得到纯文字。然后,我们用英文停用词表除去常见的停用词,并用Porter (1980)的算法提取词干。再用TF-IDF术语权重函数找出有意义的标签表示特征(单词)(其中IDF因子是,其中N是集合大小,df(t)是标签t的文档频次),降维阶段的执行是用来减少每个维度的特征数:我们把文档频次高于0.6低于0.02(Dittenbach, Merkl, 和 Rauber (2000))的术语剔除了。
最后的结果就是组成了一个140个术语向量,对应于T140中每个标签;向量的维度是17518。
5.2 自组织图(SOM)
作为一个正式的艺术的聚类算法,我们使用自组织图(SOM) (Kohonen, 1990, 2001)在我们的工作中。SOM被证明是一个组织信息和展示它的有效方法。并且允许内容可访问的检索(Barrón-Adame, Cortina-Januchs, Vega-Corona, 和 Andina, 2012;Chen, 2012; Dittenbach et al., 2000; Perelomov, Azcarraga, Tan, 和Chua, 2002; Roh, Oh, 和 Han, 2003; Russell, Yin, 和 Allinson, 2002;Vesanto 和 Alhoniemi, 2000)。Kohonen的自组织图是具有非监督神经网络结构的,它使用竞争的学习产生一个向量空间模型(VSM)中每个神经元的引用向量的空间拓扑关系;之后是训练过程,依靠高维输入向量。神经元被安排为一个正常的节点格子中,一般是2维。这样,训练完了后,相似的输入到图将产生邻接输出到节点格子中。
SOM大小是一个1212的集合。为了获得神经元数与标签数的直方图(144个神经元,140个标签)。在这种方法中,每个神经元至少有一个标签。我们不想强迫标签组织是图大小的原因。如果标签的数量大于神经元的数量,那么多个标签就必须分享同一个神经元,因为没有足够的空间可一把他们分配到分区中。考虑到格子我们采用方格。
在图学习的阶段,我们把初始的学习等级设置为0.1,初始间距设置为12和图的宽度相同,训练的迭代次数是50000.选择这些值是用不同的配置测试了几次之后为了用平均量化错误(AQE)来测量图的质量。AQE测量图中输入向量和他们相关的引用向量的平均距离。其他关于SOM的问题就是和标准的库一样了SOMlib4(Dittenbach et al. (2000))。
6定量评估
这个部分提出了我们用在实验阶段的评估方法,并且显示了这个实验的结果。
6.1外部评估方法
大量评估方法采用定量的评估方法并决定聚类的质量。这些方法允许我们比较带有算法方法的引用解决方案。使得分类成为一个引用的解决方案,聚类成为一个聚类算法的输出。这些外部评估方法主要的不同在于他们适合的属性。Meila
____________
4 http://www.ifs.tuwien.ac.at/~andi/somlib/.
(2003)使用了一个特殊的度量标注研究了12种数学约束。Amigó,Gonzalo, Artiles, and Verdejo (2009)按照4种约束比较了5个家族的度量标准。最近的工作中,我们采用4种约束选择最后的评估方法:
聚类均匀性
属于不同类别的两个文档应该划分为两个不同聚类簇。
聚类完整性
同一类文档应该在同一个聚类簇中
碎片袋
将混乱引入混乱的类簇比引入整齐的类簇的害处小。
聚类大小和质量比较
大聚类簇中的小错误会比小类簇中的大量错误好。
BCubed度量标准的精确度和召回率符合这些约束 (Bagga 和 Baldwin, 1998) 。尽管这些约束最初被建议用来处理共引链的得分,但是我们把它用在标签聚类上。在标签聚类中,这些约束评判聚类结果中标签和其他标签相关性的出现/缺席,给定一个标签i如公式7,BCubed召回函数定义如公式8.

然后, 代表tag i所在的聚类簇中与它包括它自己相关的标签的比率。是tag i所在的类中与它包括它自己相关的标签的比率。最后的如公式9,如公式10.

其中,N是标签的数量。即使最原始的建议是给每个术语不同的权重值,但是我们为每个标签设置了相同的权重,所以在我们的公式里可以被定义为1/N。
我们结合BCubed度量标准使用F方法(F1)van Rijsbergen (1974)。在我们的情况中,F方法和和都赋予了相同的权重;因此,结合的结果是和的调和值(见公式11)。

其中,。F值越接近1,聚类质量越好。
6.2 实验设置
为了促进聚类标签云可视化,我们依靠Kohonen的自组织图。然而,自组织图没能生成合适的聚类簇。由于这个原因我们使用了一个部分聚类算法,包含在著名的Cluto包5中:使用全局最优不断的重复二分(rbr)(Zhao 和 Karypis,2004)。这个算法用在自组织图的输出中把它结构化到一个类簇中6,允许执行一个定量评估。
我们还想知道这些使用SOM得到的结果能不能和那些由艺术状态算法得到的结果相比。我们执行了两个不同的方法来对T140数据集聚类6,不考虑表示方法。在第一重方法中,我们直接用Cluto对输入向量聚类。第二种方法中,我们使用SOM组合向量,然后我们对SOM结果聚类以便评估结果。然后,我们更深层地细化了这些方法:
基础数据:使用Cluto包聚类。
为了聚类标签向量,我们使用上面描述的算法。对T140数据集聚类每个表示。聚类的数量设置为技术人员定义的类别数,如,24。
这个过程之后我们获得了5个不同的聚类结果:4对应标签共现度量标准(见5.1.1部分)1对应内容矩阵(见5.1.2)。当我们把数据精确地聚类到人工选择的组中时,我们就可以直接评估这些结果和人工选择的比较。
基于SOM的方法:用自组织图聚类。
在这种方法中我们训练了一些SOM然后我们把他们的神经元分组到理想的类簇中。第一步就是执行5.2部分定义的程序。由于初始化的随机性,我们创建了5
____________
5 http://glaros.dtc.umn.edu/gkhome/cluto/cluto/overview
6 其他的算法参数,像相似函数或者标准函数默认使用了,明确指出只有聚类簇的数量是我们所要获得的。
个SOM给每一个表示,用这种方法异常的结果(过好或者过坏的结果)的效果
会缓和到平均值。
一旦T140标签映射到SOM上,下一步就是使用基础数据方法中相同的算法分组神经元。这个标注过程允许获得神经元的类簇所以我们可以使用外部评估方法。我们把每个单一的图单元或者神经元作为Cluto的输入向量。在这点,我盟不使用所有的SOM单元,只是那些在第一步中使用了至少一个标签标注的数据。输出就是由图神经元构成的期望数量的组。使用每个神经元的标签代替它们,我们获得了我们想要和人工解决方案比较的聚类簇。作为基础方法,我们获得了5个不同的聚类解决方案:4对应标签共现度量标准,1对应内容矩阵。
6.3结果
实验变为总共是10个分数:8对应2个聚类算法和4个共现权重函数的组合,和2个算法用文本表示。
表2展示了聚类算法的组合结果。SOM+Cluto和Cluto分别伴随着平均值和标准差值。从这些结果中,我们可以看出SOM+Cluto屈服于最好的F方法表现,但是可以和使用了Cluto的方法相比较。这就说明了我们前面6.2部分设置的问题:使用SOM得到的结果能不能和那些由艺术状态算法得到的结果相比。观察平均值,可以看出SOM和基础算法相比表现是相似的。,更进一步,适合可视化聚类结果。
表2:算法的平均值和标准差
| 算法 |
平均值 |
标准差 |
||||
|
|
BEP |
BER |
Fm |
BEP |
BER |
Fm |
| SOM + Cluto |
0.433 |
0.386 |
0.408 |
0.044 |
0.052 |
0.049 |
| Cluto |
0.439 |
0.348 |
0.388 |
0.039 |
0.032 |
0.035 |
这样,结果就显示SOM可以像Cluto那样精确地分组标签。
更进一步,表3显示了10个分数值展示了BCPrecision,BCRecall 和 F-measure度量标准,按照F-measure递减。根据F-measure最后的结合就是SOM结合Cluto rbr算法使用W权重函数(见公式3)。
表3:使用最后的基准全部排序

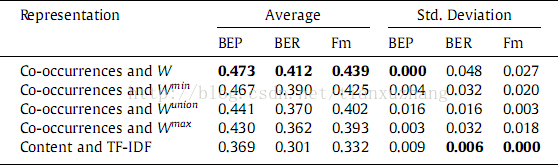
表4显示了用标签表示方法分组的结果。这种表示使用了最好的BCPrecision和BCRecall对就是对应W和函数。这对两种算法都是有效的可以从表3看出。其中每种方法的两个最好的结果都分别达到W和函数。另一方面,这些结果显示Wunion所谓的Jaccard系数,在这个案例中不是表示共现的最好方法这也被相似的工作总结出,例如Dattolo et al. (2011)。注意到表现的类型和F-measure平均值(见表4),这4个权重函数好过基于文档内容。所以,可以认为标签聚类表示任务中基于标签共现的表现比基于文档内容的要好。对于这4个共现权重函数W和表现的最好。我们相信这个可以是非平衡数据集的一个结果;这样这些权重函数正常化考虑使用大文档频率(W max和Wunion)是不对的。
表4:最终基础数据表示类型的平均值和标准差
7 丰富标签云:深度定量评估
标签聚类有很多的方法关注用户检索、标注、订阅和在社会化标签系统中浏览的时候推荐标签和网页。使用标签云访问信息提供了一个机会来利用用户信息和组织用户信息。图2显示了delicious原始的标签云,按字母排序。为了向用户提供信息和相关标签我们建议丰富我们组织的标签云见图3.使用和个人标签及神经元最相关的术语信息。这种方法能很简单的展示和分析标签之间的关系以及他们相关的内容。还允许定量评估来消除多义标签的歧义。

图2:原来的delicious标签云

图3:标签云聚类
7.1使用语言模型抽取术语
一旦标签被组织了,就可以通过分析标注文档的内容提取有代表性的术语。
首先,我们组织所有使用神经元标签标注的文档,并且我们生成一个术语排序表。为了完成这个工作,我们决定使用语言模型技术,因为它可以基于比起全局(所有的神经元)标签在神经元中的相关度排序。一个术语在一个神经元中越相关,它在其他神经元中就越不相关,最好的排序是要在那个神经元中得到。结果,每个神经元都要排出与它最相关的术语列表。
基于假设:术语在一个神经元中的分布是不同的,以及同一个标签再所有的神经元中的分布是不同的语义指示器。标签语义地表示一个神经元就更可能出现在这个神经元中而不是其他。
Kullback–Leibler分支 (KLD)权重函数是一个统计的方法来量化一个可能的分布P与一个模型(或说一种条件)分布Q接近度Cover and Thomas(1991)。因此KLD权重函数是适合于决定术语属于一个神经元而不是其余的神经元的(见公式12)。

其中pn(t)是术语属于神经元的可能性,Pm(t) 术语属于整个神经元集合的可能性。
KLD返回每个神经元中每个术语的值。这样,我们就可以推论出一个标签在一个神经元中比起其他标签的表现力。介绍KLD分值是为了在统计上反应术语对文档集的良好的描述性。术语的KLD分值小代表术语在一个神经元中出现的可能性和在其余神经元中出现的比率相同。术语的KLD分值小代表术语在一个神经元中出现的可能性比在其余神经元中出现的比率高,这显示了术语的区分度。一个区分度好的术语必须是在一个神经元中的贡献要大于其余的。
和神经元术语提取相同的过程也应用于标签,以获得每个标签相关的术语。一但我们使用了KLD分值,我们就可以将术语和神经元或者标签联系起来。最后我们得到了一个标签云聚类结果,其中每个术语和标签都有一个相关术语列表,帮助用户理解标签的含义,并提供更进一步的导航能力(见图3,图4)。
7.2定量评估
在我们实验中使用的每个算法和表现的定量结果允许我们比较每种方法的界限。但是,我们考虑这种评估方法作为一个可比较方法大部分是有用的。其中更高的结果意味着比人工组织有更好的表现。另一方面,人工注释分类过程不考虑我们集合中出现的标签的特殊含义而考虑单词最广泛的含义是值得的;这使得人工分类过程不是数据集敏感的了。正因为这,我们相信一个定量评估可以帮助理解和完成不同推荐的方法的比较结果。总之,我们总结我们的定量评估方法可以对聚类方法比较,但是他提供的表现不如定性的界面。
为了分析标签云的结果和参考的方法的接近程度,我们提出了一个标签云对应最好结果的表现(见图3)并提出了一个定性评估依靠标签云丰富(见图4)。
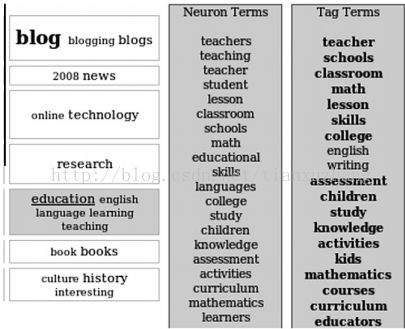
图4:术语对应教育标签,从神经元中提取(11/5)。粗体的单词代表在标签和神经元中都出现的术语
分析标签云的结果得出以下的思想:
·标签云结果显示了像”community”和”social”这样的标签,组织到人工分类中的”Society“类目中,并且由和社交网络相关的标签例如”twitter“、”collaboration”或者”socialmedia “包围而和其他和社会相关的标签很远,例如” history,“ politics ”或者” green “。这看起来是这个文档集合有关用户分享兴趣的组合中标签“社区”的真正意义,同样也出现在计算机科学中。用同样的方法,这里使用的单词“social”在社交网络上下文中,而不是在社会的上下文中。
·每个同一个单词的单复数标签对都被组织到了同一个神经元中(article/articles (3,6), photo/pho-tos(11,1),tutorial/tutorials(6,2),game/games(11,5),video/videos(11,7),recipe/recipes(11,11),book/books(6,11),blog/blogs(1,11))除了tool和tools是相邻的。
·同一个术语的标签分享神经元。这来自像下面这些情况的标签photo和 photography(11,1),blog和blogging(1,11),fun和funny(11,6),以及shop和 shopping(10,11).
·我们把标签划分到其他类别可能是错误的,因为它们表面上没有分享任何的语义相关性。然而,在这个集合中很特别,杂类中的标签和其他类别中的标签有很有意义的相关性。
-- 2008:大篇幅的出现在新闻中,看起来是个时间敏感的话题,并且可能和时间标签有联系。
-- Cool:尽管是单独出现的,它的最近邻和设计相关的话题相关,cool看起来是一个设计社区重用标签。
-- Toread:是一个和以后要读的资源相关的标签,和article以及articles共享一个神经元。
-- Interesting:这是另外一个不确定和主观的标签(类似cool),没有和具体的社区想了想。
7.3应用
为标签云中的每个标签和神经元建立一个术语列表可能是社会化术前系统中的一个有用的和可操作的:使用期望的话题和术语过滤可能是一个好的方法来订阅用户推送;查找具体集合中标签的关系可以发现用户社区,甚至是一个时间趋势;新闻可视化证明用户可以探索到所有文档集合的方法;分析标签关系随时间的演变可以显示每个标签的兴趣特征,例如,一个标签什么时候会变得流行。
这些列表可以帮助建立订阅来接收使用具体标签标注以及内容包含这个术语的页面。例如一个用户可能对使用教育标注过的网页,还有那些内容中包含了数学的页面感兴趣。用同样的方法,用户可以订阅整个神经元(包括教育、英语、语言、学习和讲解)的推送,还有那些内容中包含了术语数学的页面。图4 显示了属于标签“教育”以及对应的神经元相关的术语排序。
这样,基于进化图更新的标签随时间演变的分析就可以做了,例如:“新闻”这个标签可能由于在特定的时间段的新闻趋势偏离它的邻居。
8总结和展望
通过这个工作,我们探索了标签云中的标签聚类来提高社会化书签系统中的信息访问。我们探索了不同的标签聚类表示方法,发现语义相似的组。使用相似性聚类的标签帮助用户用一个简单的方法导航相关的内容。以前的研究基于标签共现和文本内容发现标签的关系。据我们所知,没有一个基于表桥共现和文本内容的可比较的方法,也没有一个基础数据及来定量评估聚类结果。鉴于越来越多的用户想要查找标签的语义关系。本文的工作填补了这两方面的空缺,基于标签共现和文本内容的比较方法,和提出一个社会化标签基础数据集包含人工分类,可以用来作为定量评估的基础数据。
在发现标签之间的语义的任务上,我们比较了5种不同的表现。我们使用了4种不同的基于标签共现的表现,和一种基于文本的内容的表现。我们建立了一个输入向量集,每一个标签都包含一个和向量标签以及其余T140中的标签的相似度。这四个基于标签共现的函数选来展示对比起基于内容的显示的基于标签共现的显示的一个基准,它是基于TF-IDF术语权重函数的。我们还显示了SOM可以组织标签云至少和经典的聚类算法一样好,还允许对结果可视化展示。
我们的结果显示使用基于标签共现展示标签屈服于更多精确的聚类,比起基于内容来。另外,基于标签共现的表现可以有意义地减少程序的计算机消耗因为(i)每个向量有更少的特征数量。(2)建立这些向量更容易。在4个不同的共现权重函数中,其中2个优于Jaccard相似系数,可以被广泛的应用于执行任务而不要探究它的适应性。另外,我们完成了使用定量标准分析聚类结果。文档的术语抽取帮助我们决定一些标签与具体数据集有意义偏向的情况。我们对这个术语抽取推荐了一些应用来提高信息访问。
我们相信我们的数据集给研究者建立更好的方法发现标签的关系时基于几种准则定量评估提供了一个可靠的解决方案。同样地,提供了一个内部视角关于不同的标签表示方法对发现标签之间的关系的适应性。在科学上铺平了道路,并且形成一个更好利用社会化书签的系统。
未来的工作,另外一个水平的组织可以达到在更好的粒度上扩展聚类。我们的聚类云显示神经元包含标签,并且每个标签有一个相关的文档集合。我们可以在神经元的水平上工作,组织文档对应的标签。用这种方法我们可以获得合神经元相关的文档组,提供一个深层的组织便于用户的导航。同样的,术语抽取过程可以提供一个更抽象的水平,提供聚类的术语列表,以及神经元和标签。最后,聚类的重叠部分可以对评估解决方案感兴趣。
致谢
感谢MA2VICMR 大学联盟 (S2009/TIC-1542, http://www.mavir.net)的资金支持、Madrid Regional政府网络卓越基金和西班牙研究项目Holopedia基金、Ministerio de Ciencia eInnovación 补助编号 TIN2010-21128-C02.
参考文献
Amigó, E., Gonzalo, J., Artiles, J., 和 Verdejo, F. (2009). A comparison ofextrinsic clustering evaluation metrics based on formal constraints.Information Retrival,12(5). 613-613.
Angeletou, S., Sabou, M., Specia, L., 和 Motta, E. (2007). Bridging the gap betweenfolksonomies and the semantic web. In Proceedings of ESWC 2007: workshop on bridgingthe gap between semantic web and web 2.0.
Bagga, A.,和 Baldwin, B. (1998). Entity-basedcross-document coreferencing using the vector space model. In Proceedings ofthe 17th international conference on computational linguistics. association forcomputational linguistics (pp. 79–85).
Morristown, NJ, USA. Barrón-Adame, J. M., Cortina-Januchs, M. G., Vega-Corona, A., 和 Andina, D. (2012).
Unsupervised system to classify SO2 pollutantconcentrations in Salamanca,Mexico. Expert Systems withApplications, 39(1), 107–116.
Begelman, G., Keller, P., 和 Smadja, F. (2006). Automated tagclustering: Improving search and exploration in the tag space. In WWW ’06:collaborative web tagging workshop.
Brooks, C. H., 和 Montanez, N. (2006). Improved annotation ofthe blogosphere via autotagging and hierarchical clustering. In Proceedings ofthe 15th international conference on World Wide Web WWW ’06 (pp. 625–632). New York, NY, USA:ACM.
Cattuto, C., Benz, D., Hotho, A., 和 Stumme, G. (2008). Semantic grounding oftag relatedness in social bookmarking systems. The Semantic Web-ISWC 2008,615–631.
Chen, J.-H. (2012). Developing SFNN models topredict financial distress of construction companies. ExpertSystems with Applications, 39(1), 823–827.
Chen, Y.-X., Santaía, R., Butz, A., 和 Therón, R. (2009). Tagclusters: Semantic aggregationof collaborative tags beyond tagclouds. In A. Butz, B. D. Fisher, M.
Christie, A. Krüger, P. Olivier, 和 R. Therón (Eds.), Smart graphics. Lecturenotes in computer science (Vol. 5531, pp. 56–67). Springer.
Cover, T., 和 Thomas, J. (1991). Elements of informationtheory (Vol. 6). Wiley Online Library, ISBN: 0-471-06259-6.
Dattolo, A., Eynard, D., 和 Mazzola, L. (2011). An integrated approachto discover tag semantics. In Proceedings of the 2011 ACM symposium on appliedcomputing SAC’11 (pp. 814–820). New York, NY, USA: ACM.
Deutsch, S., Schrammel, J., 和 Tscheligi, M. (2011). Comparing different layoutsof tag clouds: Findings on visual perception. In Proceedings of the Second IFIPWG 13.7 conference on human-computer interaction and visualization HCIV’09 (pp. 23–37).
Berlin, Heidelberg: Springer-Verlag.
Dittenbach, M., Merkl, D., 和 Rauber, A. (2000). The growing hierarchicalself- organizing map. IEEE Computer Society, pp. 15–19.
Gabrielsson, S. (2006). The Use of self-organizingmaps in recommender systems.Master’s thesis, Department of InformationTechnology at the Division of Computer Systems, Uppsala University.
Garcia-Silva, A., Corcho, O., Alani, H., 和 Gomez-Perez, A. (2011). Review of the state ofthe art: Discovering and associating semantics to tags in folksonomies. KnowledgeEngineering Review, 26(4).
Hassan-Montero, Y., 和 Herrero-Solana, V. (2006). Improving tag-clouds asvisual information retrieval interfaces. In international conference onmultidisciplinary information sciences and technologies.
Heymann, P., Koutrika, G., 和 Garcia-Molina, H. (2008). Can social bookmarking improveweb search? InWSDM ’08: Proceedings of the international conference on Websearch and web data mining (pp. 195–206). New York, NY, USA: ACM.
Jiang, J., 和 Conrath, D. (1997). Semantic similaritybased on corpus statistics and lexical taxonomy. cmp-lg/9709008.
Karydis, I., Nanopoulos, A., Gabriel, H., 和 Spiliopoulou,M. (2009). Tag-aware spectral clusteringof music items. In International symposium on music information retrieval.Citeseer.
Kohonen, T. (1990). The self-organizing map.Proceedings of the IEEE, 78(9),1464–1480.
Kohonen, T. (2001). Self-organizing maps.Self-organizing maps (3rd ed., ). Berlin:Springer. 2001, 501 p. Springer series ininformation sciences, ISBN3540679219.
Li, B., 和 Zhu, Q. (2008). The determination ofsemantic dimension in social tagging system based on som model. In Proceedingsof the second international symposium on intelligent information technologyapplication IITA ’08.man
Au Yeung, C., Gibbins, N., 和 Shadbolt, N. (2007). Tag meaningdisambiguation through analysis of tripartite structure of folksonomies. InWI-IATW ’07: Proceedings of the 2007 IEEE/WIC/ACM international conferences onweb intelligence and intelligent agent technology – workshops (pp. 3–6). Washington,DC, USA: IEEE ComputerSociety.
Markines, B., Cattuto, C., Menczer, F., Benz, D., Hotlo, A., 和 Stumme, G. (2009).Evaluating similaritymeasures for emergent semantics of social tagging. In Proceedings of theinternational world wide web conferenceWWW2009. (pp. 641–650).
Meila, M. (2003). Comparing clusterings bythe variation of information. In: COLT (pp. 173–187).
Mika, P. (2007). Ontologies are us: A unifiedmodel of social networks and semantics. Web Semantics: Science Services andAgents on the World Wide Web, 5(1), 5–15.
Perelomov, I., Azcarraga, A. P., Tan, J., 和 Chua, T. S. (2002). Using structured self-organizingmaps in news integration websites. 11th International World Wide Web Conference, 2002.
Porter, M. (1980). An algorithm for suffixstripping. Program, 14(3), 130–137.
Risi, S., Lehwark, P., 和 Ultsch, A. (2008). Visualization andclustering of tagged musicdata. Studies in classification, data analysis, and knowledgeorganization. Data analysis, machine learning and applications.Berlin Heidelberg: Springer.
Roh, T. H., Oh, K. J., 和 Han, I. (2003). The collaborative filteringrecommendation based on SOM cluster-indexing CBR. Expert Systems with Applications, 25(3),413–423.
Russell, B., Yin, H., 和 Allinson, N. M. (2002). Document clusteringusing the 1 + 1dimensional self-organising map. In Proceedings of the thirdIDEAL.Sbodio, M. L., 和 Simpson, E. (2009). Tags clustering withself organizing maps.
HPLabs Techincal Reports.Schmitz, P. (2006). Inducing ontology from flickrtags. In WWW ’06: collaborativeweb tagging workshop.
Sen, S., Lam, S. K., Rashid, A. M., Cosley, D., Frankowski, D., Osterhouse, J., Harper, F.M., Harper, J., 和 Riedl (2006). Tagging, communities, vocabulary, evolution. InProceedingsof the 2006 20th anniversary conference on Computer supportedcooperative workCSCW ’06 (pp. 181–190). New York, NY, USA: ACM.
Simpson, E. (2008). Clustering tags inenterprise and web folksonomies. HP LabsTechnical Reports.
Specia, L., 和 Motta, E. (2007). Integrating folksonomieswith the semantic web. TheSemantic Web: Research and Applications.
Sun, K., Wang, X., Sun, C., 和 Lin, L. (2011). A language modelapproach for tagrecommendation. Expert Systems with Applications, 38(3), 1575–1582.
Vandic, D., van Dam, J.-W., Hogenboom, F., 和 Frasincar, F. (2011). A semanticclustering-basedapproach for searching and browsing tag spaces. InProceedings of the 2011 ACMSymposium on Applied Computing, SAC ’11(pp. 1693–1699). New York, NY, USA: ACM.van Rijsbergen, C. J. (1974). Foundations ofevaluation. Journal of Documentation, 30,365–373.
Venetis, P., Koutrika, G., 和 Garcia-Molina, H. (2011). On the selection of tagsfor tag clouds. In Proceedings of the fourth ACM international conference onWeb search and data mining. WSDM ’11 (pp. 835–844). New York, NY, USA: ACM.Vesanto, J., 和 Alhoniemi, E. (2000). Clustering of theself-organizing map. IEEE-NN.
Wu, X., Zhang, L., 和 Yu, Y. (2006). Exploring social annotationsfor the semantic web.In Proceedings of WWW ’06 (pp. 417–426). New York, NY, USA: ACM.
Zhao, Y., 和 Karypis, G. (2004). Empirical and theoreticalcomparisons of selectedcriterion functions for document clustering. MachineLearning, 55(3), 311–331.
Zheng, N., 和 Li, Q. (2011). A recommender systembased on tag and timeinformation for social tagging systems. Expert Systemswith Applications, 38(4),4575–4587.
Zubiaga, A., García-Plaza, A. P., Fresno, V., 和 Martínez, R. (2009a). Content-basedclustering fortag cloud visualization. In ASONAM ’09: Proceedings of the 2009InternationalConference on Advances in Social Network Analysis and Mining(pp. 316–319). Washington, DC, USA: IEEE ComputerSociety.
Zubiaga, A., Martínez, R., 和 Fresno, V. (2009b). Getting the most out ofsocial annotations for web page classification. In Proceedings ofthe 9th ACM symposium on Document engineering. DocEng ’09 (pp. 74–83). New York, NY, USA: ACM.