yarn中的wordcount
hadoop hdfs yarn伪分布式运行,有如下进程
1320 DataNode
1665 ResourceManager 1771 NodeManager 1195 NameNode 1487 SecondaryNameNode
写一个mapreduce示例,在yarn上跑,wordcount数单词示例
![]() 代码在github上:https://github.com/huahuiyang/yarn-demo
代码在github上:https://github.com/huahuiyang/yarn-demo
步骤一
我们要处理的输入如下,每行包含一个或多个单词,空格分开。可以用hadoop fs -put ... 把本地文件放到hdfs上去,方便mapreduce程序读取
hadoop yarn
mapreduce
hello redis
java hadoop
hello world
here we go
wordcount程序希望完成数单词任务,输出格式是 <单词 出现次数>
步骤二
新建一个工程,工程结构如下,这个是个maven管理的工程
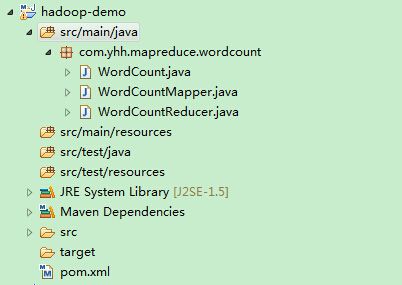
源代码如下:
pom.xml文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>hadoop-yarn</groupId> <artifactId>hadoop-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.1.1-beta</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.1.1-beta</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.1.1-beta</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.1.1-beta</version> </dependency> </dependencies> </project>
package com.yhh.mapreduce.wordcount; import java.io.IOException; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; public class WordCountMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text,IntWritable> { @Override public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); if(line != null) { String[] words = line.split(" "); for(String word:words) { output.collect(new Text(word), new IntWritable(1)); } } } }
package com.yhh.mapreduce.wordcount; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; public class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>{ @Override public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int count = 0; while(values.hasNext()) { values.next(); count++; } output.collect(key, new IntWritable(count)); } }
package com.yhh.mapreduce.wordcount; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobClient; public class WordCount { public static void main(String[] args) throws IOException { if(args.length != 2) { System.err.println("Error!"); System.exit(1); } JobConf conf = new JobConf(WordCount.class); conf.setJobName("word count mapreduce demo"); conf.setMapperClass(WordCountMapper.class); conf.setReducerClass(WordCountReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
步骤三
打包发布成jar,右击java工程,选择Export...,然后选择jar file生成目录,这边发布成wordcount.jar,然后上传到hadoop集群
[root@hadoop-namenodenew ~]# ll wordcount.jar
-rw-r--r--. 1 root root 4401 6月 1 22:05 wordcount.jar
运行mapreduce任务。命令如下
hadoop jar ~/wordcount.jar com.yhh.mapreduce.wordcount.WordCount data.txt /wordcount/result
可以用hadoop job -list看任务运行情况,运行成功大概会有如下输出
14/06/01 22:06:25 INFO mapreduce.Job: The url to track the job: http://hadoop-namenodenew:8088/proxy/application_1401631066126_0003/ 14/06/01 22:06:25 INFO mapreduce.Job: Running job: job_1401631066126_0003 14/06/01 22:06:33 INFO mapreduce.Job: Job job_1401631066126_0003 running in uber mode : false 14/06/01 22:06:33 INFO mapreduce.Job: map 0% reduce 0% 14/06/01 22:06:40 INFO mapreduce.Job: map 50% reduce 0% 14/06/01 22:06:41 INFO mapreduce.Job: map 100% reduce 0% 14/06/01 22:06:47 INFO mapreduce.Job: map 100% reduce 100% 14/06/01 22:06:48 INFO mapreduce.Job: Job job_1401631066126_0003 completed successfully 14/06/01 22:06:49 INFO mapreduce.Job: Counters: 43
然后mapreduce输出的任务结果如下,单词按照字典序排序
hadoop fs -cat /wordcount/result/part-00000 go 1 hadoop 2 hello 2 here 1 java 1 mapreduce 1 redis 1 we 1 world 1 yarn 1