HANA Text Analysis中的分词功能
SAP HANA分词属于SAP HANA文本分析的一部分。我们可以通过创建全文索引的方式来实现SAPHANA分词功能。SAP HANA文本分析支持以下7种数据类型:TEXT, BINTEXT, NVARCHAR, VARCHAR, NCLOB, CLOB,and BLOB。你可以根据不同的应用需求选择不同的数据类型。
为了使用SAP HANA 实现中文分词,我们首先确认你安装的SAP HANA中是否有支持中文。如下图所示,看到有支持简体中文的一项则确认没有问题。
1. 测试
我们先创建一个用来测试的数据库表。
CREATE COLUMN TABLE SEGMENTATION_TEST(
URLVARCHAR(200)PRIMARY KEY,
CONTENTNCLOB,
LANGUVARCHAR(10)
);
其中CONTENT列是存储需要分词的文本。而LANGU列则指定了分词所使用的语言集,默认为EN,我们这里需要设置为ZH。
然后我们在刚创建的表SEGMENTATION_TEST的CONTENT建立全文索引,如下所示:
CREATE FULLTEXTINDEX FT_INDEX
ONSEGMENTATION_TEST(CONTENT) TEXT ANALYSIS
ON CONFIGURATION 'LINGANALYSIS_FULL'
LANGUAGE COLUMN "LANGU";
注意需要创建全文索引的表必须含有主键,否则会报错,如下图所示:

创建全文索引后,SAP HANA会自动生成一张以$TA_<index_name>为名称的表。
我们向表SEGMENTATION_TEST插入一条数据:
INSERT INTO SEGMENTATION_TEST(URL,CONTENT,LANGU)
VALUES('http://xxx.xxx.xxx','想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!','ZH');
然后就可以查看到分词的结果了:
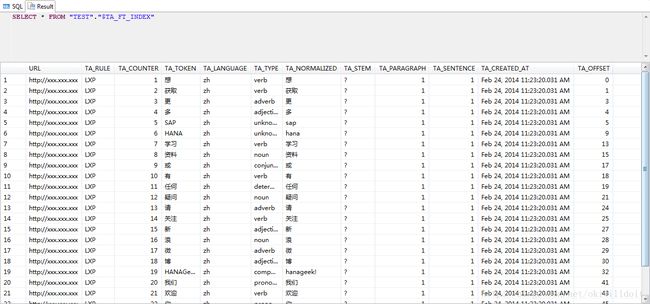
分词表不仅将中文文章分解成一个个单词,并且还为每个单词标识了词性。例如“获取”标识了动词,HANA为未知词性,标识了未知。当然对于HANA和SAP这种系统词典没有的词,我们可以通过自定义词典的方式进行标注。
HANA自定义词典
在一些基于SAP HANA的文本分析应用中,我们经常需要对特定的人名、产品等名词进行正确的识别。SAPHANA自带的分词组件可能无法正确识别新词,例如我们现在需要对“上网卡”、“上海中学”和“乔布斯”三个名词进行准确识别和提取。我们使用上篇blog建好的全文索引表SEGMENTATION_TEST进行测试:
CREATE COLUMN TABLE "TEST"."SEGMENTATION_TEST" (
"URL" VARCHAR(200),
"CONTENT" NCLOB,
"LANGU" VARCHAR(10),
PRIMARY KEY ("URL")
);
CREATE FULLTEXTINDEX FT_INDEX
ONSEGMENTATION_TEST(CONTENT) TEXT ANALYSIS
ON CONFIGURATION'LINGANALYSIS_FULL'
LANGUAGE COLUMN "LANGU";
INSERT INTO "TEST"."SEGMENTATION_TEST"(URL,CONTENT,LANGU)
VALUES('XXX.XXX.XXX','上网卡','zh');
INSERT INTO "TEST"."SEGMENTATION_TEST"(URL,CONTENT,LANGU)
VALUES('XXX.XXX.XXX2',‘上海中学’,'zh');
INSERT INTO "TEST"."SEGMENTATION_TEST"(URL,CONTENT,LANGU)
VALUES('XXX.XXX.XXX3',‘乔布斯','zh');
然后查询结果如下:
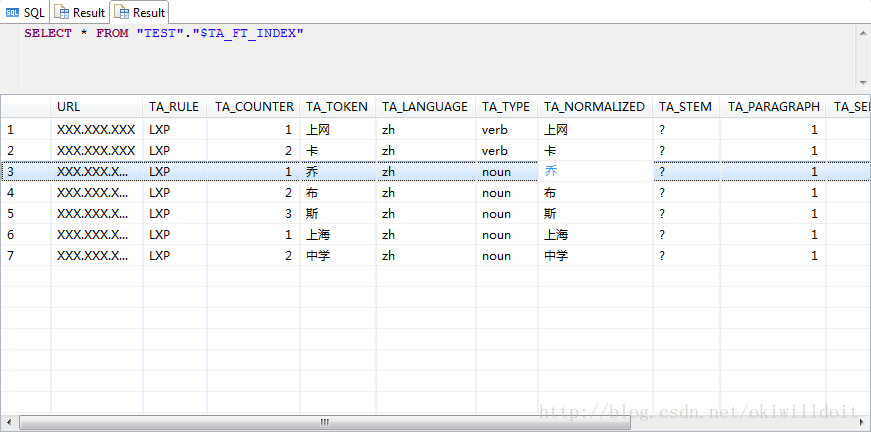
可以看出HANA没有能够正确的分出我们想要的结果。
面对上述问题,我们可以通过使用SAP HANA提供的自定义分词词典来解决。
SAP HANA用户自定义词典文件为simplified-chinese-std.sample-cd,目录为\usr\sap\XXX\SYS\global\hdb\custom\config\lexicon\lang\simplified-chinese-std.sample-cd其中XXX是你SAP HANA的实例名。文件示例内容如下所示:
<?xml encoding="euc-cn" ?>
<!--?Copyright 2013 SAP AG. All rights reserved.
SAP and the SAP logo are registered trademarks of SAP AG inGermany and other countries. Business Objects and the Business Objects logo areregistered trademarks of Business Objects S.A., which is an SAP company.
-->
<!-- Sample tagger-lexiconclientdictionary -->
<explicit-pair-list>
<!-- Common Nouns -->
<item key = "海缆" analysis = "海缆[Nn]"></item>
<item key = "船艏" analysis = "船艏[Nn]"></item>
<!-- Proper Names -->
<item key="张忠谋" analysis = "张忠谋[Nn-Prop]"></item>
<item key="奇摩" analysis = "奇摩[Nn-Prop]"></item>
</explicit-pair-list>
文件中支持两种类型的自定义词典,普通名词和人名,我们只需在自定义的人名analysis属性中加入[Nn-Prop]标识即可,然后将其它类型名词analysis属性加入[Nn]标识。最终我们更改过后的文件如下所示:
<?xml encoding="euc-cn" ?>
<!--?Copyright 2013 SAP AG. All rights reserved.
SAP and the SAP logo are registered trademarks of SAP AG inGermany and other countries. Business Objects and the Business Objects logo areregistered trademarks of Business Objects S.A., which is an SAP company.
-->
<!-- Sample tagger-lexicon client dictionary -->
<explicit-pair-list>
<!-- Common Nouns -->
<item key = "海缆" analysis = "海缆[Nn]"></item>
<item key = "船艏" analysis = "船艏[Nn]"></item>
<item key = "上网卡" analysis = "上网卡[Nn]"></item>
<item key = "上海中学" analysis = "上海中学[Nn]"></item>
<!-- Proper Names -->
<item key="张忠谋" analysis = "张忠谋[Nn-Prop]"></item>
<item key="奇摩" analysis = "奇摩[Nn-Prop]"></item>
<item key="乔布斯" analysis = "乔布斯[Nn-Prop]"></item>
</explicit-pair-list>
接着我们继续插入同样的数据,结果如下所示:
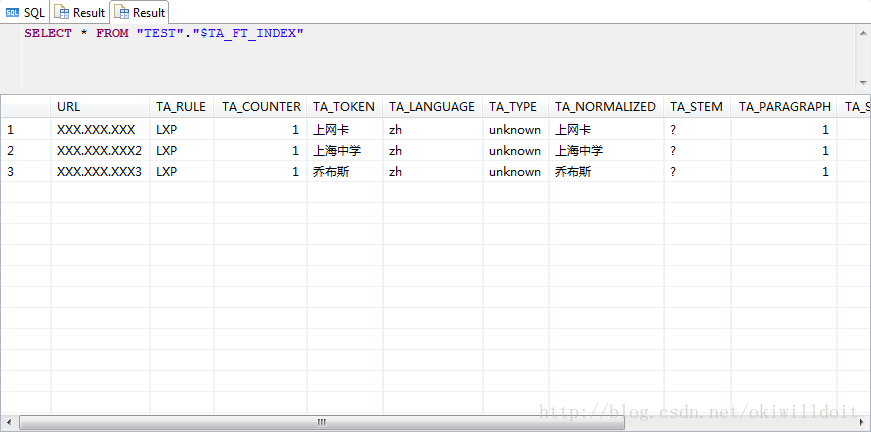
如上图所示,“上网卡”、“上海中学”和“乔布斯”已经正确的提取出来了。