使用Flex Bison 和LLVM编写自己的编译器
使用Flex Bison 和 LLVM编写你自己的编译器
原文出处:http://gnuu.org/2009/09/18/writing-your-own-toy-compiler
1、介绍
我总是对编译器和语言非常感兴趣,但是兴趣并不会让你走的更远。大量的编译器的设计概念可以搞的任何一个程序员迷失在这些概念之中。不用说,我也曾今尝试过,但是并没有取得太大的成功,我以前的尝试都停留在语义分析阶段。本文的灵感主要来源于我最近一次的尝试,并且在这一次中我取得一点成就。
幸运的是,最近的几年,我参加了一些项目,这些项目给了我在建立编译器上很多有用的经验和观点。另外一件事是,我非常幸运得到LLVM的帮助。对于这个工具,我不知道改怎么去形容它,但是他给我的这个编译器的确带来非常大的帮助。
1.1、你为什么要阅读本文
你也许想看看我正在做的事情,但是更有可能的是,你也是和我一样对编译器和语言非常感兴趣,并且也可能遇到了一些在探索的过程中遇到了一些难题,你可能正打算解决这些难题,但是却没有发现好的资源。本文的目标就是提供这些资源,并以一种手把手的方式教你从头到尾的去创建一个具有基本功能的语言编译器。
在本文,我不会去解释一些编译器基本理论,所以你要在开始本文前去了解什么是BNF语法,什么是抽象语法树数据结构 AST data structure,什么是基础编译器流水线 complier pipline。就是说,我会把本文描述的尽量简单。本文的目的就是以一种简单易懂的方式来介绍相关编译器资源的方式来帮助那些从来没有编译器经验的人。
1.2、达到的成果
如果你根据文章内容一步步来,你将会得到一个能定义函数,调用函数,定义变量,给变量赋值执行基本数学操作的语言。这门语言支持两种基本类型,double和integer类型。还有一些功能还未实现,因此,你可以通过自己去实现这些功能得到你满意的功能并且能为你理解编写一个编译器提供不少的帮助。
1.3 问题解答
1.3.1 我需要了解什么样的语言
我们使用的工具是基于C/C++的。LLVM是基于C++的,我们的这个语言也基于C++,因为C++具有很多面向对象的优点和可以被重用的STL。此外对于C,Lex和Bison都具有那些初看起来令人迷惑的语法,但是我将尽可能的去解释他。我们需要处理的语法非常小,最多就100行,因此它是比较容易理解的。
1.3.2 很复杂吗?
是或否,这里面有很多的东西你需要了解,甚至多的让人感觉到害怕,但是老实说,其实这些都非常简单,我们同样会使用很多工具分解这些层次的复杂性,并使得这些内容可管理。
1.3.3 完成它需要多长时间
我们将要完成的编译器花了我三天的时间。但是如果你按“follow me”的方式来完成这个编译器的话,你将会花费更少的时间。如果要全部理解这里面的内容可能会花去稍微长一点的时间,但是你至少应该在一个下午就将整个编译器运行起来。
好,如果你已经准备好,我们开始吧。
2、准备开始
2.1 构成编译器的最基本的要素
一个编译器是由一组有三个到四个组件(还有一些子组件)构成,数据以管道的方式从一个组件输入并流向下一个组件。在我们这个编译器中,可能会用到一些稍微不同的工具。下面这个图展示了我们构造一个编译器的步骤,和每个步骤中将使用的工具。

从上图你可以看到在Linking这一步是灰掉的。我们的语言将不支持编译器的连接(很多的语言都不支持编译器的连接)。在文法分析阶段,我们将使用开源工具Lex,即如今的Flex,文法分析一般都伴随者语法分析,我们使用的语法分析工具将会是Yacc,或者说是Bison,最后一旦语义分析完成,我们将遍历我们的抽象语法树,并生成我们的”bytecode 字节码”,或”机器码 matchine code”。做这一步,我们将使用LLVM,它能生成快速字节码,我们将使用LLVM的JIT(Just In Tinme)来在我们的机器上编译执行它
总结一下,步骤如下:
- 文法分析用Flex:将数据分隔成一个个的标记token (标示符identifiers,关键字keywords,数字numbers, 中括号brackets, 大括号braces, 等等etc.)
- 语法分析用Bison: 在分析标记的时候生成抽象语法树. Bison 将会做掉几乎所有的这些工作, 我们定义好我们的抽象语法树就OK了.
- 组装用LLVM: 这里我们将遍历我们的抽象语法树,并未每一个节点生成字节/机器码。 这听起来似乎很疯狂,但是这几乎就是最简单的 一步了.
在我们开始下一步之前,你应该准备安装好Flex,Bison和LLVM。因为我们马上就要使用到它们。
2.2 定义我们的语法
我们语法是我们语言中最核心的部分,我们的语法使用类似标准C的语法,因为这样的语法非常熟悉,而且简单。我们语法的一个典型的例子如下:
|
1
2
3
4
5
|
int
do_math(
int
a) {
int
x = a * 5 + 3
}
do_math(10)
|
看起来很简单。它和C非常相似,但是它没有使用分号做语句的分隔,同时你也会注意到我们的语法中没有return语句。这就是你可以自己实现的部分。
现在我们还没有任何机制来验证结果。我们将通过检查我们编译之后LLVM打印出的字节码验证我们程序的正确性。
3、 第一步,使用Flex进行文法分析
这是最简单的一步,给定语法之后,我们需要将我们的输入转换一系列内部标记token。如前所述,我们的语法具有非常基础的标记token:标示符identifier ,数字常量(整型和浮点型),数学运算符号,括号,中括号,我们的文法定义文件称为token.l,它具有一些固定的语法。定义如下:
%{
#include
#include "node.h"
#include "parser.hpp"
#define SAVE_TOKEN yylval.string = new std::string(yytext, yyleng)
#define TOKEN(t) (yylval.token = t)
extern "C" int yywrap() { }
%}
%%
[ \t\n] ;
[a-zA-Z_][a-zA-Z0-9_]* SAVE_TOKEN; return TIDENTIFIER;
[0-9]+\.[0-9]* SAVE_TOKEN; return TDOUBLE;
[0-9]+ SAVE_TOKEN; return TINTEGER;
"=" return TOKEN(TEQUAL);
"==" return TOKEN(TCEQ);
"!=" return TOKEN(TCNE);
"<" return TOKEN(TCLT);
"<=" return TOKEN(TCLE);
">" return TOKEN(TCGT);
">=" return TOKEN(TCGE);
"(" return TOKEN(TLPAREN);
")" return TOKEN(TRPAREN);
"{" return TOKEN(TLBRACE);
"}" return TOKEN(TRBRACE);
"." return TOKEN(TDOT);
"," return TOKEN(TCOMMA);
"+" return TOKEN(TPLUS);
"-" return TOKEN(TMINUS);
"*" return TOKEN(TMUL);
"/" return TOKEN(TDIV);
. printf("Unknown token!\n"); yyterminate();
%%
在第一节(译者注:即%{%}中定义的部分)声明了一些特定的C代码。由于Bison不会去访问我门的yytext变量,我们使用宏”SAVE_TOKEN”来保证标示符的文本和文本长度是安全的(而不是靠标记本身来保证)。第一个token告诉我们要忽略掉那些空白字符。你会注意到我们有些一些等价性比较的标记和其他。还有一些标记还没有实现,你可以非常自由的将这些标记加到你自己的编译器中去。
现在我们在这里做的是定义这些标记和他们的符号名。符号(比如TIDENTFIER)将成为我们语法中的终结符。我们只是返回它,我们从未定义它,他们是在什么地方定义的?当然是在bison语法文件中。我们包含的parser.hpp头文件将会被bison所生成,并且里面的所有符号都将被生成,并被我们在这里使用。
我们对这个token.l运行flex命令,并生成tokens.cpp文件,这个程序将会和我们的语法分析器一起编译并提供yylex()函数来识别这些标记。我们将在稍后运行这个命令,因为现在我们需要从bison那里生成头文件。
4、第2步 使用Bison进行语法分析
这是我们工作中最富有挑战性的一部分。生成一个正确的无二义的语法并不是一项简单的工作,要经过很多实践努力。庆幸的是,我们例子中的语法是简单而完整的。在我们实现我们的语法之前,我们需要详细的讲解一下我们的设计。
4.1、设计AST(抽象语法树)
语法分析的最终结果是抽象语法树AST,正如我们将看到的,Bison生成抽象语法树的最优工具;我们唯一需要做的事情就是将我们的代码插入到语法中去。
文本形式字符串,例如”int x”代表了我们语言的文本形式,和这个类似,抽象语法树AST则代表了我们语言在内存中的表现形式一样(在语言在组装成而进程码之前)。正因如此,我们要在把这些插入在语法分析中的数据结构首先设计好。这个过程是非常直接的,因为我们为语法中的每个语义单元创建了一个结构。方法声明、方法调用,变量声明,引用,这些都构成了抽象语法树的节点。我们语言的抽象语法树的节点如下图:
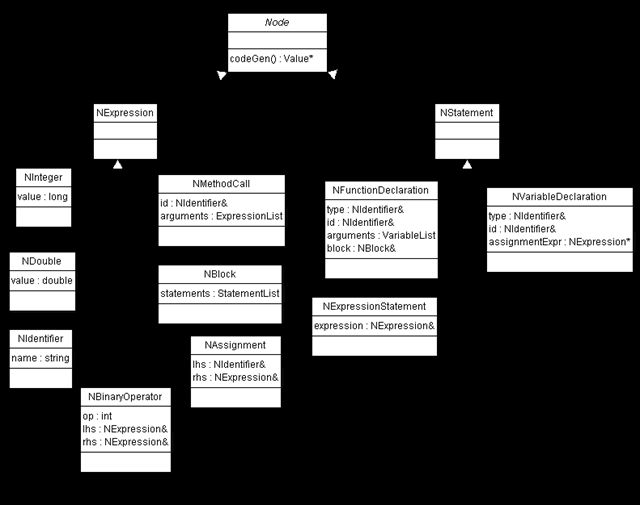
上图的C++代码如下:
node.h文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
|
#include <iostream>
#include <vector>
#include <llvm/Value.h>
class
CodeGenContext;
class
NStatement;
class
NExpression;
class
NVariableDeclaration;
typedef
std::vector<NStatement*> StatementList;
typedef
std::vector<NExpression*> ExpressionList;
typedef
std::vector<NVariableDeclaration*> VariableList;
class
Node {
public
:
virtual
~Node() {}
virtual
llvm::Value* codeGen(CodeGenContext& context) { }
};
class
NExpression :
public
Node {
};
class
NStatement :
public
Node {
};
class
NInteger :
public
NExpression {
public
:
long
long
value;
NInteger(
long
long
value) : value(value) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NDouble :
public
NExpression {
public
:
double
value;
NDouble(
double
value) : value(value) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NIdentifier :
public
NExpression {
public
:
std::string name;
NIdentifier(
const
std::string& name) : name(name) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NMethodCall :
public
NExpression {
public
:
const
NIdentifier& id;
ExpressionList arguments;
NMethodCall(
const
NIdentifier& id, ExpressionList& arguments) :
id(id), arguments(arguments) { }
NMethodCall(
const
NIdentifier& id) : id(id) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NBinaryOperator :
public
NExpression {
public
:
int
op;
NExpression& lhs;
NExpression& rhs;
NBinaryOperator(NExpression& lhs,
int
op, NExpression& rhs) :
lhs(lhs), rhs(rhs), op(op) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NAssignment :
public
NExpression {
public
:
NIdentifier& lhs;
NExpression& rhs;
NAssignment(NIdentifier& lhs, NExpression& rhs) :
lhs(lhs), rhs(rhs) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NBlock :
public
NExpression {
public
:
StatementList statements;
NBlock() { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NExpressionStatement :
public
NStatement {
public
:
NExpression& expression;
NExpressionStatement(NExpression& expression) :
expression(expression) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NVariableDeclaration :
public
NStatement {
public
:
const
NIdentifier& type;
NIdentifier& id;
NExpression *assignmentExpr;
NVariableDeclaration(
const
NIdentifier& type, NIdentifier& id) :
type(type), id(id) { }
NVariableDeclaration(
const
NIdentifier& type, NIdentifier& id, NExpression *assignmentExpr) :
type(type), id(id), assignmentExpr(assignmentExpr) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
class
NFunctionDeclaration :
public
NStatement {
public
:
const
NIdentifier& type;
const
NIdentifier& id;
VariableList arguments;
NBlock& block;
NFunctionDeclaration(
const
NIdentifier& type,
const
NIdentifier& id,
const
VariableList& arguments, NBlock& block) :
type(type), id(id), arguments(arguments), block(block) { }
virtual
llvm::Value* codeGen(CodeGenContext& context);
};
|
非常的清晰明了,我们省略了getter和setter方法,这里只列出了共有成员;这些类也不需要影藏私有数据,并省略了codeGen方法。在我们导出AST成LLVM的字节码时,就需要使用到这个方法。
4.2、Bison介绍
bison的语法定义文件同样是由这些标记构成的最复杂的部分。这并不是说技术上有多复杂,但是我也会花一些时间来讨论一下Bison的语法细节,好,现在让我们立刻来熟悉一下Bison的语法。我们将使用基于类似于BNF的语法,使用定义的好终结符和非终结符来组成我们有效的每一个语句和表达式(这些语句和表达式就代表我们之前定义的AST节点)。例如:
if_stmt : IF '(' condition ')' block { /* do stuff when this rule is encountered */ }
| IF '(' condition ')' { ... }
;
在上面例子中,我们定义了一个if语句(如果我们支持if语句话),它和BNF不同之处在于,每个语法后面都跟了一系列动作(在’{‘和’}'之间的内容)。这个动作将在此条语法被识别(译者注:归约)的时候被执行。这个过程将会递归地按从叶子符号到根节点符号的次序执行,在这个过程,每一个非终结符最终会被合并为一棵大的语法树。你将会看到的’$$’符号代表着当前树的跟节点(译者注:’$$’代表本条语法规则中冒号左边的部分的语义内容)。此外’$1′代表了本条规则叶子中的第一个符号(译者注:’$1′代表了本条语法规则冒号右边的内容,$1代表冒号右边的第一个符号的语义值)。在上面的例子中,当’condition’有效时我们将会把$3 赋值给$$。这个例子可以解释如何将我们AST和语法规则关联起来。我们将在每一条规则中通常赋值一个节点到$$,最后这些规则会合并成一个大的抽象语法树。Bison的部分是我们语言最复杂的部分,你需要花一点时间去理解它。此外到此为止,你还没有看到完整的代码。下面就是完整的Bison部分的代码:
parser.y
%{
#include "node.h"
NBlock *programBlock; /* the top level root node of our final AST */
extern int yylex();
void yyerror(const char *s) { printf("ERROR: %s\n", s); }
%}
/* Represents the many different ways we can access our data */
%union {
Node *node;
NBlock *block;
NExpression *expr;
NStatement *stmt;
NIdentifier *ident;
NVariableDeclaration *var_decl;
std::vector *varvec;
std::vector *exprvec;
std::string *string;
int token;
}
/* Define our terminal symbols (tokens). This should
match our tokens.l lex file. We also define the node type
they represent.
*/
%token TIDENTIFIER TINTEGER TDOUBLE
%token TCEQ TCNE TCLT TCLE TCGT TCGE TEQUAL
%token TLPAREN TRPAREN TLBRACE TRBRACE TCOMMA TDOT
%token TPLUS TMINUS TMUL TDIV
/* Define the type of node our nonterminal symbols represent.
The types refer to the %union declaration above. Ex: when
we call an ident (defined by union type ident) we are really
calling an (NIdentifier*). It makes the compiler happy.
*/
%type ident
%type numeric expr
%type func_decl_args
%type call_args
%type program stmts block
%type stmt var_decl func_decl
%type comparison
/* Operator precedence for mathematical operators */
%left TPLUS TMINUS
%left TMUL TDIV
%start program
%%
program : stmts { programBlock = $1; }
;
stmts : stmt { $$ = new NBlock(); $$->statements.push_back($1); }
| stmts stmt { $1->statements.push_back($2); }
;
stmt : var_decl | func_decl
| expr { $$ = new NExpressionStatement(*$1); }
;
block : TLBRACE stmts TRBRACE { $$ = $2; }
| TLBRACE TRBRACE { $$ = new NBlock(); }
;
var_decl : ident ident { $$ = new NVariableDeclaration(*$1, *$2); }
| ident ident TEQUAL expr { $$ = new NVariableDeclaration(*$1, *$2, $4); }
;
func_decl : ident ident TLPAREN func_decl_args TRPAREN block
{ $$ = new NFunctionDeclaration(*$1, *$2, *$4, *$6); delete $4; }
;
func_decl_args : /*blank*/ { $$ = new VariableList(); }
| var_decl { $$ = new VariableList(); $$->push_back($1); }
| func_decl_args TCOMMA var_decl { $1->push_back($3); }
;
ident : TIDENTIFIER { $$ = new NIdentifier(*$1); delete $1; }
;
numeric : TINTEGER { $$ = new NInteger(atol($1->c_str())); delete $1; }
| TDOUBLE { $$ = new NDouble(atof($1->c_str())); delete $1; }
;
expr : ident TEQUAL expr { $$ = new NAssignment(*$1, *$3); }
| ident TLPAREN call_args TRPAREN { $$ = new NMethodCall(*$1, *$3); delete $3; }
| ident { $$ = $1; }
| numeric
| expr comparison expr { $$ = new NBinaryOperator(*$1, $2, *$3); }
| TLPAREN expr TRPAREN { $$ = $2; }
;
call_args : /*blank*/ { $$ = new ExpressionList(); }
| expr { $$ = new ExpressionList(); $$->push_back($1); }
| call_args TCOMMA expr { $1->push_back($3); }
;
comparison : TCEQ | TCNE | TCLT | TCLE | TCGT | TCGE
| TPLUS | TMINUS | TMUL | TDIV
;
%%
5、生成Flex和Bison代码
现在我们有了Flex的token.l文件和Bison的parser.y文件。我们需要将这两个文件传递给工具,并由工具来生成c++代码文件。注意Bison同时会为Flex生成parser.hpp头文件;这样做是通过-d开关实现的,这个开关是的我们的标记声明和源文件分开,这样就是的我们可以让这些token标记被其他的程序使用。下面的命令创建parser.cpp,parser.hpp和tokens.cpp源文件。
$ bison -d -o parser.cpp parser.y $ lex -o tokens.cpp tokens.l
如果上述工作都没有出错的话,我们现在位置已经完成了我们编译器工作总量的2/3。如果你现在想测试一下我们的代码,你可以编译一个简单的main.cpp程序:
|
1
2
3
4
5
6
7
8
9
10
11
|
#include <iostream>
#include "node.h"
extern
NBlock* programBlock;
extern
int
yyparse();
int
main(
int
argc,
char
**argv)
{
yyparse();
std::cout << programBlock << endl;
return
0;
}
|
你可以编译这些文件:
$ g++ -o parser parser.cpp tokens.cpp main.cpp
现在你需要安装LLVM了,因为llvm::Value被node.h引用了。如果你不想这么做,只是想测试一下Flex和Bison部分,你可以注释掉node.h中codeGen()方法。
如果上述工作都完成了,你现在将有一个语法分析器,这个语法分析器将从标准输入读入,并打出在内存中代表抽象语法树跟节点的内存非零地址。
6、组装AST和LLVM
编译器的下一步很自然地是应该将AST转换成机器码。这意味着将每一个语义节点转换成等价的机器指令。LLVM将帮助我们把这步变得非常简单,因为LLVM将真实的指令抽象成类似AST的指令。这意味着我们真正要做的事就是将AST转换成抽象指令。
你可以想象这个过程是从抽象语法树的根节点开始遍历每一个树上节点并产生字节码的过程。现在就是使用我们在Node中定义的codeGen方法的时候了。例如,当我们遍历NBlock代码的时候(语义上NBlock代表一组我们语言的语句的集合),我们将调用列表中每条语句的codeGen方法。上面步骤代码类似如下的形式:
|
1
2
3
4
5
6
7
8
9
10
11
|
Value* NBlock::codeGen(CodeGenContext& context)
{
StatementList::const_iterator it;
Value *last = NULL;
for
(it = statements.begin(); it != statements.end(); it++) {
std::cout <<
"Generating code for "
<<
typeid
(**it).name() << endl;
last = (**it).codeGen(context);
}
std::cout <<
"Creating block"
<< endl;
return
last;
}
|
我们将实现抽象语法树上所有节点的codeGen方法,然后在向下遍历树的时候调用它,并隐式的遍历我们整个抽象语法树。在这个过程中,我们在CodeGenContext类来告诉我们生成字节码的位置。
6.1、关于LLVM要注意的一些信息
LLVM最大的一个确定就是,你很难找到LLVM的相关文档。在线手册、教程、或其他的文档都没有及时的得到相关维护,这些文档大部分都是过期的文档。除非你去深入研究,否则你很难找到关于C++ API的信息。如果你自己安装LLVM,docs
是最新的文档。
我发现最好学习LLVM的方法就是通过LLVM的例子去学习。在LLVM的压缩包的’example’目录下有很多快速生成字节码的例子。在LLVM demo site上可以将C做输入,然后生成C++ API的例子。以这些例子提供的方法,我找到了类似于int x = 5 ;的指令的生成方法。我使用这些工具实现大部分的节点。
关于LLVM的问题描述到此为止,我将在下面罗列出codegen.h和codegen.cpp的源代码
codegen.h的内容。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include <stack>
#include <llvm/Module.h>
#include <llvm/Function.h>
#include <llvm/PassManager.h>
#include <llvm/CallingConv.h>
#include <llvm/Bitcode/ReaderWriter.h>
#include <llvm/Analysis/Verifier.h>
#include <llvm/Assembly/PrintModulePass.h>
#include <llvm/Support/IRBuilder.h>
#include <llvm/ModuleProvider.h>
#include <llvm/ExecutionEngine/GenericValue.h>
#include <llvm/ExecutionEngine/JIT.h>
#include <llvm/Support/raw_ostream.h>
using
namespace
llvm;
class
NBlock;
class
CodeGenBlock {
public
:
BasicBlock *block;
std::map<std::string , Value*> locals;
};
class
CodeGenContext {
std::stack<codegenblock *> blocks;
Function *mainFunction;
public
:
Module *module;
CodeGenContext() { module =
new
Module(
"main"
); }
void
generateCode(NBlock& root);
GenericValue runCode();
std::map<std::string , Value*>& locals() {
return
blocks.top()->locals; }
BasicBlock *currentBlock() {
return
blocks.top()->block; }
void
pushBlock(BasicBlock *block) { blocks.push(
new
CodeGenBlock()); blocks.top()->block = block; }
void
popBlock() { CodeGenBlock *top = blocks.top(); blocks.pop();
delete
top; }
};
|
codegen.cpp的内容。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|