基于文法分析的表达式计算器的实现
这个基于LL分析器的计算器是大三时上编译原理的一个作业。感觉是自己做过相对比较有深度的一个程序。第一次放出来跟大家分享。希望多多指教。
这个计算器支持带括号的四则运算和乘方运算。具体实现过程如下:
词法分析器:
相关正则定义:
DIGIT [0-9]
NUMBER {DIGIT}((.{DIGIT}+)|{DIGIT}*)
DELIM [ tn]
OPERATOR [+|-|*|/|^|(|)|=]
识别数值的DFA的状态转换图:
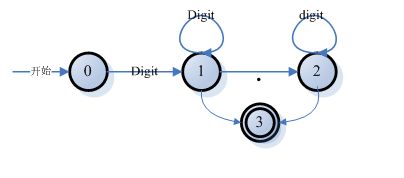
词法分析器的构造:
因为要识别表达式中的负数(形如1+ -1),这个工作有两个做法,一个是在词法分析的过程中使得词法分析器可以识别负数。一个是词法分析器只识别正数,让语法分析器去识别负数还是减法运算符。前一种方法不是一个标准的词法分析程序可以完成的,因为它要引用上下文。至少向前看一个字符。这就是LL文法或LR(1)文法的范围了。所以使用第二种方案。这也是大多数情况下所采用的方案。
文法分析器:
计算器的功能:计划包括含括号的实数四则运算和乘方运算。同时还可以识别出负号。
初期文法:
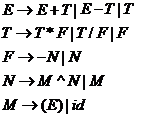
将上述文法消除左递归可得出下面的文法:注意乘方运算是具有右结合性的。而四则运算是左结合的。由于LL分析法本身的限制,要将一个非二义也非左递归的一个产生式:![]() 进行转化(因为它有公共的左因子),使其可以用LL分析法进行分析。
进行转化(因为它有公共的左因子),使其可以用LL分析法进行分析。

计算出上述文法的FIRST集和FOLLOW集,如下:
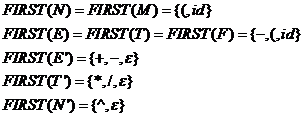

分析表的建立:因为空间原因,表项中只给出产生式的右部
| id | + | - | * | / | ^ | ( | ) | $ | |
| E | TE’ | TE’ | TE’ | ||||||
| E’ | +TE’ | -TE’ | |||||||
| T | FT’ | FT’ | FT’ | ||||||
| T’ | *FT’ | /FT’ | |||||||
| F | N | -N | N | ||||||
| N | MN’ | MN’ | |||||||
| N’ | ^N | ||||||||
| M | Id | (E) |
文法的分析表
文法分析表建立完成之后,就可以开始写程序了。代码如下:
Code
1/**///////////////////////////////////////////////////////////////////////////
2// ExpressionCalculator
3// Version 0.1
4// Powered by nankezhishi
5// All Right reserved.
6// 本计算器支持带括号的四则、乘方运算。并可包含独立的负号。
7/**///////////////////////////////////////////////////////////////////////////
8#include "iostream"
9#include "string"
10#include "cmath"
11using namespace std;
12
13//用于kind的值
14#define NUMBER 1000
15#define MYERROR 1001
16#define END 1002
17//词法分析器的当前状态
18int state;
19//读取的内容
20string input;
21//字符串的长度
22int inputlength;
23//字符串读取的位置.
24int i = 0;
25//词法分析器的返回值
26int returnvalue;
27//读取到数字时的值
28string strval;
29double yylval = 0;
30
31
32/**///////////////////////////////////////////////////////////////////////////
33//词法分析器
34/**///////////////////////////////////////////////////////////////////////////
35bool isdigit(char c){
36 return (c >= '0' && c <= '9')?true:false;
37}
38
39bool isoperator(char c){
40 return (c == '+'||c == '-'||c == '*'||c == '/'||c == '^'||c == '('||c == ')'||c == '=')?true:false;
41}
42
43//识别数字的DFA的状态转移函数
44int move(int state, char c){
45 if (isdigit(c)){
46 return (state==0)?1:state;
47 }
48 else if (state == 1 && c == '.'){
49 return 2;
50 }
51 else if (( state == 2 || state == 1) && (c == ' ' || c == 'n' || c == 0 || isoperator(c))){
52 i--; //操作符
53 return 3; //接受
54 }
55 else
56 return 0;
57}
58
59int lexer(){
60 if (i == inputlength)
61 return END;
62 if (isoperator(input[i]))
63 {
64 i++;
65 return input[i-1]; //返回非数字运算符
66 }
67 int start = i;
68 for (;i < inputlength;)
69 {
70 state = move(state,input[i++]);
71 if (state == 0)
72 return MYERROR;
73 else if (state == 3)
74 {
75 strval = input.substr(start,i-start);
76 yylval = atof(strval.c_str());
77 return NUMBER;
78 }
79 }
80}
81
82
83/**///////////////////////////////////////////////////////////////////////////
84//语法分析器采用自上而下的分析方法.
85/**///////////////////////////////////////////////////////////////////////////
86void match(int t){
87 if (returnvalue == t)
88 returnvalue = lexer();
89 else{
90 cout << "EXPRESSION ERRON IN MATCH!" << endl;
91 }
92}
93
94double E();
95
96double M(){
97 double temp;
98 switch(returnvalue)
99 {
100 case NUMBER:
101 temp = yylval;
102 match(NUMBER);
103 return temp;
104 case '(':
105 match('(');
106 temp = E();
107 match(')');
108 return temp;
109 default:
110 cout << "EXPRESSION ERROR IN M()!" << endl;
111 return 0;
112 }
113}
114
115double N();
116
117double N_(){
118 switch(returnvalue)
119 {
120 case '+':
121 case '-':
122 case '*':
123 case '/':
124 case ')':
125 case END:
126 return 1;
127 case '^':
128 match('^');return N();
129 default:
130 cout << "EXPRESSION ERROR IN N_()!" << endl;
131 return 0;
132 }
133}
134
135double N(){
136 double m,n_;
137 switch(returnvalue)
138 {
139 case NUMBER:
140 case '(':
141 m = M();
142 n_ = N_();
143 return pow(m,n_); //这里不可以写做pow(M(),N_())因为参数压栈的顺序是从右向左,这样就会先调用N_()而产生错误.
144 default:
145 cout << "EXPRESSION ERROR IN N()!" << endl;
146 return 0;
147 }
148}
149
150double F(){
151 switch(returnvalue)
152 {
153 case '-':
154 match('-');return -N();
155 case NUMBER:
156 case '(':
157 return N();
158 default:
159 cout << "EXPRESSION ERROR IN F()!" << endl;
160 return 0;
161 }
162}
163
164double T_(){
165 switch(returnvalue)
166 {
167 case '+':
168 case '-':
169 case ')':
170 case END:
171 return 1; //对于乘法,这里要返回1.
172 case '*':
173 match('*');return F() * T_();
174 case '/':
175 match('/');return 1/(F() / T_());
176 default:
177 cout << "EXPRESSION ERROR IN T_()!" << endl;
178 return 0;
179 }
180}
181
182double T(){
183 switch(returnvalue)
184 {
185 case NUMBER:
186 case '-':
187 case '(':
188 return F() * T_();
189 default:
190 cout << "EXPRESSION ERROR IN T()!" << endl;
191 return 0;
192 }
193}
194
195double E_(){
196 switch(returnvalue)
197 {
198 case '+':
199 match('+');return T() + E_();
200 case ')':
201 case END:
202 return 0;
203 case '-':
204 match('-');return -(T() - E_());
205 default:
206 cout << "EXPRESSION ERROR IN E_()!" << endl;
207 return 0;
208 }
209}
210
211double E(){
212 switch(returnvalue)
213 {
214 case NUMBER:
215 case '-':
216 case '(':
217 return T() + E_();
218 default:
219 cout << "EXPRESSION ERROR IN E()!" << endl;
220 return 0;
221 }
222}
223
224int main(){
225 while ((cin >> input) && (inputlength = input.length()) > 0)
226 {
227 state = 0;
228 i = 0;
229 returnvalue = lexer();
230 cout << E() << endl;
231 }
232
233 /**///////////////////////////////////////////////////////////////////////////
234 //词法分析器测试程序
235 /**///////////////////////////////////////////////////////////////////////////
236 //while (i < inputlength)
237 //{
238 // returnvalue = lexer();
239 // if (returnvalue == NUMBER)
240 // {
241 // cout << yylval << endl;
242 // }
243 // else if (returnvalue == MYERROR)
244 // {
245 // cout << "表达式错误" << endl;
246 // }
247 // else
248 // cout << (char)returnvalue << endl;
249 //}
250
251}
可以看到,一个简单的计算器就有如此多的步骤。一个复杂的编译器的建立过程,即使有Yacc和Lex等的帮助,也是不容易的。
来源:南柯之石博客 作者:南柯之石 责编:豆豆技术应用