高性能计算和数据密集型计算的存储需要差异分析
| 根据应用领域的不同,目前主流的分布式并行文件系统可分为2类:面向高性能计算(HPC:High Performance Computing)应用的并行文件系统,典型代表如Luster、Panasas和PVFS;面向数据密集型计算(DISC: Data Intensive Scalable Computing)的并行文件系统,典型代表为Google FS,以及重现Google FS的开源文件系统Hadoop HDFS等。这两种应用领域有何不同?它们对并行文件系统的需求有何本质差异?有无可能在并行文件系统中兼顾两种应用的需求?本文探讨并试图回答这些问题。
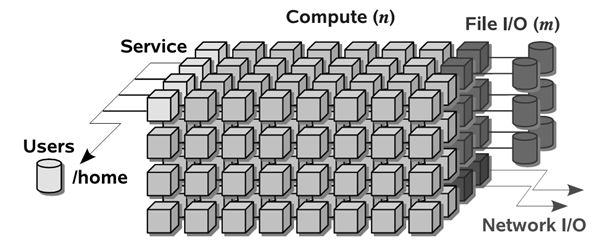
长期以来,HPC应用的主要领域是科学与工程计算,诸如高能物理、核爆炸模拟、气象预报、石油勘探、地震预报、地球模拟、药品研制、CAD设计中的仿真与建模、流体力学的计算等。 体系结构上,目前HPC系统中采用较多的是MPP架构,系统由计算节点和I/O节点、存储设备组成,这种架构也称为“Partitioned Architecture”,如图1所示【1】。计算节点上运行定制的、轻量化的OS,所有计算所需的数据都加载到DRAM中;I/O节点则使用传统的重量级的操作系统如Linux实现文件的访问。
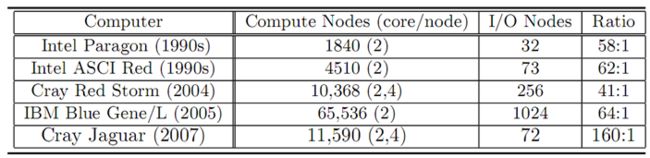
图1 HPC系统结构 在过去几十年里,HPC系统的计算能力快速提高,系统的规模也大规模扩展。表1显示了过去20年中HPC系统规模、以及计算节点和I/O节点数比例的变化趋势【1】。可以看出HPC系统中计算节点数高达几万,CPU数达到数十万,与此同时,计算节点和I/O节点的比例一直呈增加之势。
表1 HPC系统规模及计算节点与I/O节点的比例变化趋势
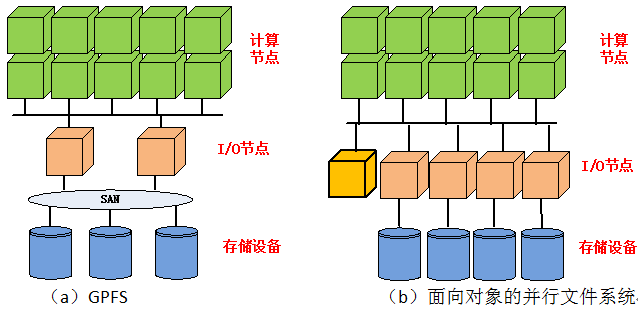
HPC执行的计算任务可能需要几个小时,也可能长达几天甚至数周。由于高性能计算系统规模高达上万个节点,故障难以避免,因此HPC系统中普遍使用“checkpoint”技术周期性地保持计算的状态和中间结果,当发生故障时,则从上次保存的“checkpoint”状态恢复计算。虽然由OS实现“checkpoint”在理论上是可行的,但开销巨大;由应用程序将任务分解为多个阶段,在每个阶段完成后保存计算结果的方法则更简单而高效。 目前HPC中使用较多的I/O (存储)系统的架构分别如图2(a)、(b)所示。
图2 HPC中的计算节点与I/O子系统
在图2(a)中,多个I/O节点为对称结构,以共享存储局域网(SAN)的方式组成集群文件系统,每个文件以条带化方式分布到多个存储设备上。计算节点则使用最广泛的网络文件访问协议NFS来访问集群文件系统。这种架构的典型代表是IBM研制的GPFS并行文件系统【8】。在图2(a)所示系统中,多个I/O节点以紧耦合方式协同工作,其扩展性受到很大限制,I/O节点数一般不超过32。 面向对象的并行文件系统具有更好的可扩展能力,其结构如图2(b)所示。典型的用于HPC的并行文件系统有Luster、Panasas、PVFS等。资料表明Luster系统的I/O节点数可扩展到103数量级。 在数据访问模式上,HPC呈现出高并发的特征。需要处理的数据往往以稀疏矩阵方式保存在一个或多个巨大的文件中(GB级甚至TB级),多个计算节点往往需要并发读写同一文件;而在有些应用中则会生成或访问大量的小文件,每个计算节点分布访问不同的文件。 HPC对存储系统的性能,包括吞吐量和延迟都有很高要求,因此大量使用并发技术来提高性能,如在存储节点内部基于RAID来实现多磁盘并发访问,采用条带花技术实现多个存储节点的并发访问;另外在数据访问时采用小块数据流水线传输的方式以隐藏延迟。
DISC是在近年来兴起的一种新型的计算方式,在互联网应用、超级计算、环境科学、生物医药、商业数据挖掘等领域具有广泛而重要的应用,已成为互联网和计算机科学研究的重要内容之一。 DISC所处理的对象是数据,是围绕数据而展开的计算,其计算方式完全不同于传统的高性能计算,HPC系统并不适用于DISC。首先,HPC系统动辄高达百万甚至千万元的价格使其很难应用到民用领域;从技术角度看,HPC的计算方式需要将数据从存储节点传输到计算节点,而对于高达PB级的海量数据而言,数据读取的时间将远高于数据处理所需时间,很显然,HPC的计算方式不适用于DISC。 出于成本考虑,DISC系统通常都采用大量廉价的商业化PC机;DISC面向的是理海量数据的处理,这些处理任务应尽量在存储节点本地进行,避免数据的迁移,因此DISC系统中的计算和存储是一体化的,节点是对等的。 由于DISC采用廉价的商业PC机,而且规模庞大,因此容错成为需要优先考虑的问题,目前采用的方法主要是数据复制,通常一份数据有3份副本,分别存储到不同的节点上,从而实现节点级的容错。数据访问模式上,呈现WORM(Write Once,Read Many)特性,系统实现上主要针对读操作进行优化;DISC系统对数据的处理为批处理方式、顺序访问,因此大块数据传输方式效率更高。 Google公司的基础信息支撑系统(GFS/Bigtable/MapReduce)是典型的DISC系统,而Hadoop则是该系统的开源实现,目前已被广泛研究和部署。
DISC和HPC对存储系统有许多共性要求,如可扩展性和高I/O吞吐量。存储系统架构也是类似的,都采用面向对象的方法,存储系统都由MDS和OSD两类节点组成。虽然在宏观上有诸多相似,但深入分析就会发现两者在微观上有很多差异,这些差异见表2。
表2 DISC与HPC的存储需求差异
* Panasas和Luster都实现了细粒度的分布式锁;PVFS不支持锁操作,需要应用程序避免数据访问中可能存在的冲突。
从前面的分析可以看出,DISC和HPC对存储系统的需求有比较大的差异。从目前已有并行文件系统或存储产品来看,都未同时支持上述两种应用。 CMU大学的PDL实验室对传统面向HPC的存储系统能否适用于DISC计算进行了探索和研究【6】。他们将PVFS文件系统进行了局部改进,加入了数据复制、数据预取等优化。初步测试表明在经过上述改进后PVFS可达到与Hadoop HDFS同样的性能,但PVFS仍然缺乏DISC所必需的自动负载均衡等关键特征。
结语面向HPC的存储系统所管理的是“一次性”使用的数据,系统关注于高吞吐量和并发性;而DISC面向长期存储的数据,系统更侧重于渐进的可扩展性和数据的保护。虽然两者在宏观上有诸多相似,但在决定性的细节上有更多不同。兼顾两种应用增加了系统的技术复杂度,性能优化变得更加困难。大量分布式系统设计的经验表明,根据应用需求进行定制和简化是解决复杂问题行之有效的方法。在IT应用系统的“个性化”要求越来越高而技术发展相对成熟的今天,“One size fit all”模式已不再适用。 面向DISC和HPC的存储系统,是否应各行其道?
参考文献
【1】 Data movement approaches for HPC. http://www.crcnetbase.com/doi/abs/10.1201/b10249-15 【2】 Dean, J., S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters.” In 6th Symposium on Operating Systems Design and Implementation (OSDI’04). 【3】 Hadoop. Apache Hadoop Project. HTTP://HADOOP.APACHE.ORG/ 【4】 Borthakur, D., “The hadoop distributed file system: Architecture and design, 2009.” HTTP://HADOOP.APACHE.ORG/COMMON/DOCS/CURRENT/HDFS_DESIGN.HTML 【5】 Ghemawat, S., H. Gobioff, S.-T. Lueng, “Google File System.” In 19th ACM Symposium on Operating Systems Principles (SOSP’03) 【6】 Tantisiriroj, W., S. V. Patil, G. Gibson. “Data intensive file systems for internet services: A rose by any other name…” Tech. Report CMU-PDL-08-114, Carnegie Mellon University, Oct. 2008. 【7】 Garth Gibson. Understanding and Maturing the Data-Intensive Scalable Computing Storage Substrate. Carnegie Mellon University. 10-1-2009. 【8】 Frank Schmuck,Roger Haskin. GPFS: A Shared-Disk File System for Large Computing Clusters. Proceedings of the Conference on File and Storage Technologies (FAST’02),28–30 January 2002, Monterey, CA, pp. 231–244. 【9】 PVFS2. Parallel Virtual File System, Version 2. HTTP://WWW.PVFS2.ORG/ |