使用Dom4j解析XML
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它.
对主流的Java XML API进行的性能、功能和易用性的评测,dom4j无论在那个方面都是非常出色的。如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,例如hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件
1.官网下载: http://www.dom4j.org/dom4j-1.6.1/
2.dom4j是sourceforge.net上的一个开源项目,因此可以到http://sourceforge.net/projects/dom4j下载其最新版.
对于下载的zip文件进行解压后的效果如下:
打开dom4j-1.6.1的解压文件

在这里可以看到有docs帮助的文件夹,也有需要使用dom4j解析xml文件的dom4j-1.6.1.jar文件.我们只需要把dom4j-1.6.1.jar文件构建到我们开发的项目中就可以使用dom4j开发了.
下面我以Myeclipse创建Java项目的构建方法为例说明.
首先创建一个demo项目,在demo项目中创建一个lib文件,把dom4j-1.6.1.jar文件拷贝到lib中,然后右键dom4j-1.6.1jar文件

点击Add to Build Path即可构建到项目中去了.
备注:如果进行的是web项目开发,我们只需要把它拷贝到web-inf/lib中去即可,会自动构建到web项目中.
在项目开发的过程中可以参考docs文件夹的(帮助文档),找到index.html打开,点击Quick start可以通过帮助文档进行学习 dom4j进行xml的解析.
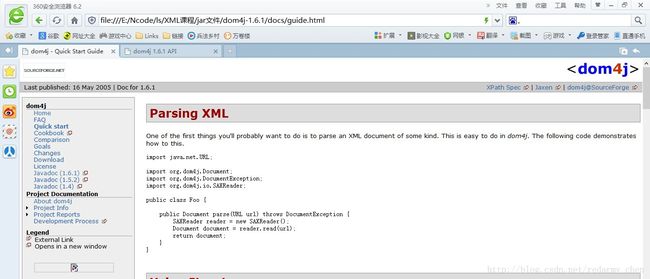
下面我对我认为api中重要的方法进行翻译说明如下:
一、DOM4j中,获得Document对象的方式有三种:
- 1.读取XML文件,获得document对象
- SAXReader reader = new SAXReader();
- Document document = reader.read(new File("csdn.xml"));
- 2.解析XML形式的文本,得到document对象.
- String text = "<csdn></csdn>";
- Document document = DocumentHelper.parseText(text);
- 3.主动创建document对象.
- Document document = DocumentHelper.createDocument(); //创建根节点
- Element root = document.addElement("csdn");
二、节点对象操作的方法
- 1.获取文档的根节点.
- Element root = document.getRootElement();
- 2.取得某个节点的子节点.
- Element element=node.element(“四大名著");
- 3.取得节点的文字
- String text=node.getText();
- 4.取得某节点下所有名为“csdn”的子节点,并进行遍历.
- List nodes = rootElm.elements("csdn");
- for (Iterator it = nodes.iterator(); it.hasNext();) {
- Element elm = (Element) it.next();
- // do something
- }
- 5.对某节点下的所有子节点进行遍历.
- for(Iterator it=root.elementIterator();it.hasNext();){
- Element element = (Element) it.next();
- // do something
- }
- 6.在某节点下添加子节点
- Element elm = newElm.addElement("朝代");
- 7.设置节点文字. elm.setText("明朝");
- 8.删除某节点. //childElement是待删除的节点,parentElement是其父节点 parentElement.remove(childElment);
- 9.添加一个CDATA节点. Element contentElm = infoElm.addElement("content"); contentElm.addCDATA(“cdata区域”);
三、节点对象的属性方法操作
- 1.取得某节点下的某属性 Element root=document.getRootElement(); //属性名name
- Attribute attribute=root.attribute("id");
- 2.取得属性的文字
- String text=attribute.getText();
- 3.删除某属性 Attribute attribute=root.attribute("size"); root.remove(attribute);
- 4.遍历某节点的所有属性
- Element root=document.getRootElement();
- for(Iterator it=root.attributeIterator();it.hasNext();){
- Attribute attribute = (Attribute) it.next();
- String text=attribute.getText();
- System.out.println(text);
- }
- 5.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring");
- 6.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("csdn");
四、将文档写入XML文件
- 1.文档中全为英文,不设置编码,直接写入的形式.
- XMLWriter writer = new XMLWriter(new FileWriter("ot.xml"));
- writer.write(document);
- writer.close();
- 2.文档中含有中文,设置编码格式写入的形式.
- OutputFormat format = OutputFormat.createPrettyPrint(); // 创建文件输出的时候,自动缩进的格式
- format.setEncoding("UTF-8");//设置编码
- XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
- writer.write(document);
- writer.close();
五、字符串与XML的转换
- 1.将字符串转化为XML
- String text = "<csdn> <java>Java班</java></csdn>";
- Document document = DocumentHelper.parseText(text);
- 2.将文档或节点的XML转化为字符串.
- SAXReader reader = new SAXReader();
- Document document = reader.read(new File("csdn.xml"));
- Element root=document.getRootElement();
- String docXmlText=document.asXML();
- String rootXmlText=root.asXML();
- Element memberElm=root.element("csdn");
- String memberXmlText=memberElm.asXML();
1.sida.xml描述四大名著的操作,文件内容如下
- <?xml version="1.0" encoding="UTF-8"?>
- <四大名著>
- <西游记 id="x001">
- <作者>吴承恩1</作者>
- <作者>吴承恩2</作者>
- <朝代>明朝</朝代>
- </西游记>
- <红楼梦 id="x002">
- <作者>曹雪芹</作者>
- </红楼梦>
- </四大名著>
- package dom4j;
- import java.io.File;
- import java.io.FileOutputStream;
- import java.io.FileWriter;
- import java.io.OutputStreamWriter;
- import java.nio.charset.Charset;
- import java.nio.charset.CharsetEncoder;
- import java.util.Iterator;
- import java.util.List;
- import org.dom4j.Attribute;
- import org.dom4j.Document;
- import org.dom4j.Element;
- import org.dom4j.io.OutputFormat;
- import org.dom4j.io.SAXReader;
- import org.dom4j.io.XMLWriter;
- import org.junit.Test;
- public class Demo01 {
- @Test
- public void test() throws Exception {
- // 创建saxReader对象
- SAXReader reader = new SAXReader();
- // 通过read方法读取一个文件 转换成Document对象
- Document document = reader.read(new File("src/dom4j/sida.xml"));
- //获取根节点元素对象
- Element node = document.getRootElement();
- //遍历所有的元素节点
- listNodes(node);
- // 获取四大名著元素节点中,子节点名称为红楼梦元素节点。
- Element element = node.element("红楼梦");
- //获取element的id属性节点对象
- Attribute attr = element.attribute("id");
- //删除属性
- element.remove(attr);
- //添加新的属性
- element.addAttribute("name", "作者");
- // 在红楼梦元素节点中添加朝代元素的节点
- Element newElement = element.addElement("朝代");
- newElement.setText("清朝");
- //获取element中的作者元素节点对象
- Element author = element.element("作者");
- //删除元素节点
- boolean flag = element.remove(author);
- //返回true代码删除成功,否则失败
- System.out.println(flag);
- //添加CDATA区域
- element.addCDATA("红楼梦,是一部爱情小说.");
- // 写入到一个新的文件中
- writer(document);
- }
- /**
- * 把document对象写入新的文件
- *
- * @param document
- * @throws Exception
- */
- public void writer(Document document) throws Exception {
- // 紧凑的格式
- // OutputFormat format = OutputFormat.createCompactFormat();
- // 排版缩进的格式
- OutputFormat format = OutputFormat.createPrettyPrint();
- // 设置编码
- format.setEncoding("UTF-8");
- // 创建XMLWriter对象,指定了写出文件及编码格式
- // XMLWriter writer = new XMLWriter(new FileWriter(new
- // File("src//a.xml")),format);
- XMLWriter writer = new XMLWriter(new OutputStreamWriter(
- new FileOutputStream(new File("src//a.xml")), "UTF-8"), format);
- // 写入
- writer.write(document);
- // 立即写入
- writer.flush();
- // 关闭操作
- writer.close();
- }
- /**
- * 遍历当前节点元素下面的所有(元素的)子节点
- *
- * @param node
- */
- public void listNodes(Element node) {
- System.out.println("当前节点的名称::" + node.getName());
- // 获取当前节点的所有属性节点
- List<Attribute> list = node.attributes();
- // 遍历属性节点
- for (Attribute attr : list) {
- System.out.println(attr.getText() + "-----" + attr.getName()
- + "---" + attr.getValue());
- }
- if (!(node.getTextTrim().equals(""))) {
- System.out.println("文本内容::::" + node.getText());
- }
- // 当前节点下面子节点迭代器
- Iterator<Element> it = node.elementIterator();
- // 遍历
- while (it.hasNext()) {
- // 获取某个子节点对象
- Element e = it.next();
- // 对子节点进行遍历
- listNodes(e);
- }
- }
- /**
- * 介绍Element中的element方法和elements方法的使用
- *
- * @param node
- */
- public void elementMethod(Element node) {
- // 获取node节点中,子节点的元素名称为西游记的元素节点。
- Element e = node.element("西游记");
- // 获取西游记元素节点中,子节点为作者的元素节点(可以看到只能获取第一个作者元素节点)
- Element author = e.element("作者");
- System.out.println(e.getName() + "----" + author.getText());
- // 获取西游记这个元素节点 中,所有子节点名称为作者元素的节点 。
- List<Element> authors = e.elements("作者");
- for (Element aut : authors) {
- System.out.println(aut.getText());
- }
- // 获取西游记这个元素节点 所有元素的子节点。
- List<Element> elements = e.elements();
- for (Element el : elements) {
- System.out.println(el.getText());
- }
- }
- }
七、字符串与XML互转换案例
- package dom4j;
- import java.io.File;
- import java.io.FileOutputStream;
- import java.io.OutputStreamWriter;
- import org.dom4j.Document;
- import org.dom4j.DocumentHelper;
- import org.dom4j.Element;
- import org.dom4j.io.OutputFormat;
- import org.dom4j.io.SAXReader;
- import org.dom4j.io.XMLWriter;
- import org.junit.Test;
- public class Demo02 {
- @Test
- public void test() throws Exception {
- // 创建saxreader对象
- SAXReader reader = new SAXReader();
- // 读取一个文件,把这个文件转换成Document对象
- Document document = reader.read(new File("src//c.xml"));
- // 获取根元素
- Element root = document.getRootElement();
- // 把文档转换字符串
- String docXmlText = document.asXML();
- System.out.println(docXmlText);
- System.out.println("---------------------------");
- // csdn元素标签根转换的内容
- String rootXmlText = root.asXML();
- System.out.println(rootXmlText);
- System.out.println("---------------------------");
- // 获取java元素标签 内的内容
- Element e = root.element("java");
- System.out.println(e.asXML());
- }
- /**
- * 创建一个document对象 往document对象中添加节点元素 转存为xml文件
- *
- * @throws Exception
- */
- public void test2() throws Exception {
- Document document = DocumentHelper.createDocument();// 创建根节点
- Element root = document.addElement("csdn");
- Element java = root.addElement("java");
- java.setText("java班");
- Element ios = root.addElement("ios");
- ios.setText("ios班");
- writer(document);
- }
- /**
- * 把一个文本字符串转换Document对象
- *
- * @throws Exception
- */
- public void test1() throws Exception {
- String text = "<csdn><java>Java班</java><net>Net班</net></csdn>";
- Document document = DocumentHelper.parseText(text);
- Element e = document.getRootElement();
- System.out.println(e.getName());
- writer(document);
- }
- /**
- * 把document对象写入新的文件
- *
- * @param document
- * @throws Exception
- */
- public void writer(Document document) throws Exception {
- // 紧凑的格式
- // OutputFormat format = OutputFormat.createCompactFormat();
- // 排版缩进的格式
- OutputFormat format = OutputFormat.createPrettyPrint();
- // 设置编码
- format.setEncoding("UTF-8");
- // 创建XMLWriter对象,指定了写出文件及编码格式
- // XMLWriter writer = new XMLWriter(new FileWriter(new
- // File("src//a.xml")),format);
- XMLWriter writer = new XMLWriter(new OutputStreamWriter(
- new FileOutputStream(new File("src//c.xml")), "UTF-8"), format);
- // 写入
- writer.write(document);
- // 立即写入
- writer.flush();
- // 关闭操作
- writer.close();
- }
- }