《Hadoop:The Definitive Guide 4th Edition》Chapter 17 Hive——A部分
续篇见“《Hadoop:The Definitive Guide 4th Edition》Chapter 17 Hive——B部分”。
一、Hive基本概念
Hive框架基于HDFS文件系统,它是HDFS文件系统与用户之间的接口,通过Hive框架,用户可以以表的概念和形式操作存储于HDFS上的文件数据。用户使用HiveQL(SQL语言的变种)语言与Hive框架进行互操作,Hive框架能够将你的HiveQL查询转换成一系列运行在Hadoop上的任务。
现在完成分布式处理任务有两种模型:
1. 使用Java语言编写MapReduce程序
2. 使用HiveQL语言,借助于Hive框架,完成分布式任务。由于“HiveQL语言”本身的限制,“HiveQL语言+Hive框架”的解决方案只能够完成一些简单的小任务,不能够完成一些复杂的大任务。
二、Hive基本原理
2.1、metastore
Hive默认会创建一个存储表的定义等元数据信息的数据库——metastore。默认情况下,该数据库被存放在本地,具体是Hive命令所在目录下的“metastore_db”目录中。在正式的生产环境中,这个数据库需要被共享,因此不使用这种本地存放数据库的方式。
注意,这个数据库(metastore)跟Hive体系中数据库(database)是不同的概念,这个数据库(metastore)中保存Hive体系中数据库(database),表(table)等元数据信息。
2.2、表与文件的对应
由上面论述可知,Hive基于HDFS文件系统,其实Hive中的表对应于HDFS文件系统中的一个文件目录。比如创建一张Hive下的表——“HiveTable”,那么其实这对应于HDFS文件系统中的“HiveTable”文件目录。其实Hive表定义只是定义了数据的结构形式。比如有如下Hive表定义:
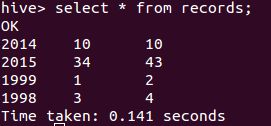
CREATE TABLE records (year STRING, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';该表定义表明了数据的结构形式为:数据有3列,列数据之间以“Tab”隔开,两行数据之间以“换行符”分开。此时如果在HDFS文件系统目录“records”下有一些文件(文件的名称是任意的),而这些文件的数据内容遵循上述的结构形式,那么这些文件的数据内容都是表“records”的数据。假如在本地有文件a和文件b,a的内容和b的内容分别如下所示:
2014 10 10
2015 34 431999 1 2
1998 3 4将两个文件复制到HDFS文件系统的“records”目录下,接着执行HiveQL查询语句“select * from records”,得到如图1所示结果。
图1
三、安装运行Hive
由上述介绍可知,Hive基于HDFS文件系统,要想正常运行Hive,首先必须满足以下条件:
1、设置HADOOP_HOME环境变量,该环境变量的值为Hadoop的安装目录
2、格式化Namenode,运行Namenode Daemon和Datanode Daemon,见“安装运行Hadoop”
接下来运行Hive有两种方式:
3.1、交互模式
执行“hive”命令,进入Hive的交互模式
3.2、非交互模式
3.2.1、“hive -f”方式
后面跟文件,文件中有HiveQL查询脚本。比如:
hive -f script.q3.2.2、“hive -e”方式
后面跟HiveQL查询脚本,最后的“;”可省略。比如:
hive -e "show tables"四、往Hive表添加数据文件
4.1、使用HDFS命令
如“2.2、表与文件的对应”中所述,可以使用HDFS命令直接将数据文件添加到Hive表对应的HDFS文件目录下。
4.2、使用HiveQL
先使用如下HiveQL脚本建立一个Hive表:
CREATE TABLE dummy(value STRING);接着在本地新建一个文件“data.in”,里面的内容如下:
X
Y
Z
J
K
L然后使用以下HiveQL脚本,将“data.in”文件添加到“dummy”表对应的HDFS文件目录下:
LOAD DATA LOCAL INPATH 'data.in' OVERWRITE INTO TABLE dummy此时,使用bin/hdfs dfs -ls /home/dsl/user/hive/warehouse/dummyHDFS命令,查看“dummy”表对应的HDFS文件目录,可得图2所示结果。
图2

五、Hive参数配置
5.1、Hive参数配置形式
- 在Hadoop配置文件中配置参数,比如在“core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml”等Hadoop配置文件中。由于Hive基于Hadoop,因而在Hadoop配置文件中配置的参数也属于Hive参数范畴
- 在Hive配置文件中配置参数,比如在“hive-site.xml”等Hive配置文件中
- 通过命令行选项“-hiveconf”来配置参数,比如如“hive -hiveconf fs.defaultFS=hdfs://localhost”命令所示
- 通过参数设置命令“set”来配置参数,比如在Hive交互模式中执行“set hive.enforce.bucketing=true”命令,就可以配置“hive.enforce.bucketing”参数的值为“true”
5.2、Hive参数配置的优先级
按照优先级从低到高排列:
- 通过Hadoop默认配置文件(比如“core-default.xml,hdfs-default.xml,mapred-default.xml和yarn-default.xml”等Hadoop默认配置文件)和Hive默认配置文件(比如“hive-default.xml”等Hive默认配置文件)
- 通过Hadoop一般配置文件(比如“core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml”等Hadoop一般配置文件)和Hive一般配置文件(比如“hive-site.xml”等Hive一般配置文件)
- 通过“-hiveconf”参数配置选项
- 通过参数设置命令“set”
5.3、参看参数配置
在Hive的交互模式中,使用“set”命令,可以查看参数配置值。
set key:表示列出该key的值
set -v:表示列出所有参数的值
比如在Hadoop配置文件“core-site.xml”中有如下片段:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9001</value>
</property>
</configuration>此时,在Hive的交互模式中,执行“set fs.defaultFS”命令,可得到如图3所示结果。
图3
![]()
5.4、重要参数配置
Hive默认使用MapReduce作为执行引擎,也可使用Apache Tez或者Spark作为执行引擎。具体可通过“hive.execution.engine”参数来完成上述配置,它的默认配置值为“hive.execution.engine=mr(即MapReduce的缩写)”。
Hive的错误日志文件路径默认为“${java.io.tmpdir}/${user.name}/hive.log”,一般为“/tmp/用户名/hive.log”,可通过“hive.log.dir”参数,自定义错误日志文件的父目录路径。
可通过“hive.root.logger”参数来自定义日志的打印级别。
Hive表文件存储的根目录由“hive.metastore.warehouse.dir”属性设置,默认值为“/user/hive/warehouse”。
六、Hive常见的两种运行模式和Metastore
6.1、Hive常见的两种运行模式
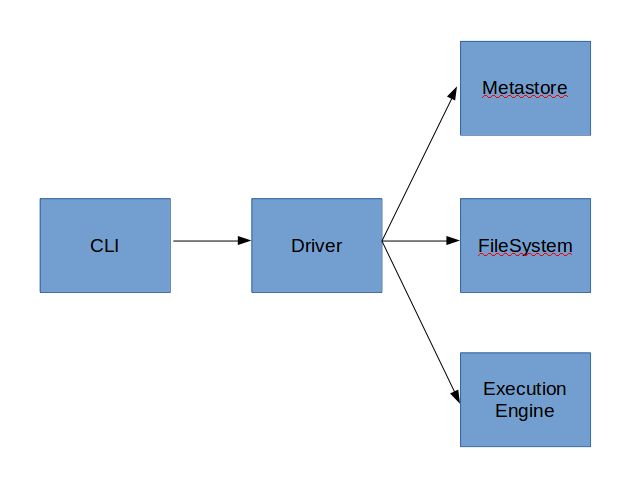
6.1.1、直接模式
最常见的使用模式,包括“Hive交互模式”和“Hive非交互模式”两种。背后的运行结构如图4所示。
图4
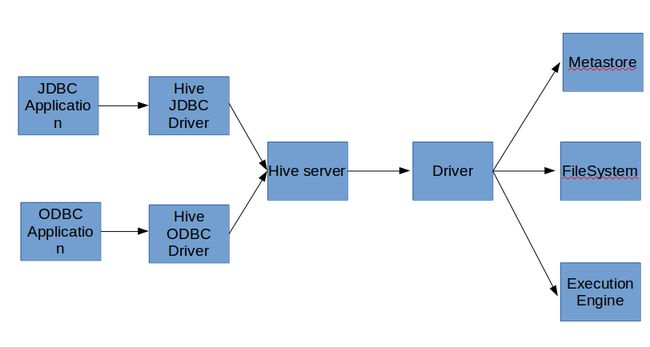
6.1.2、C/S模式
执行hive --service命令开启一个独立的“Hive Server”进程,然后使用编程语言编写一个应用程序,该应用程序与“Hive Server”之间通过“Driver”连接。背后的运行结构如图5所示。
图5
6.2、Metastore
有3种metastore机制:embedded metastore,local metastore和remote metastore。“embedded metastore”最简单,但是一次只允许一个Hive会话使用该“embedded metastore”;“local metastore”和“remote metastore”相比“embedded metastore”复杂,但功能也更加强大,一般生产环境中使用“local metastore”。