Hadoop-2.5.0-cdh5.3.2 HA 安装
- 一 规划
- 1 软件版本
- 2 主机规划
- 3 变量名及目录路径规划
- 二 环境准备
- 1 创建 hadoop 用户
- 2 网络配置
- 3 安装 JDK
- 4 配置 SSH 免密码通信
- 5 VNC 配置 可选
- 三 安装 ZooKeeper
- 四 安装 Hadoop 重点
- 1 下载解压配置环境变量
- 2 修改配置文件
- 3 分发程序
- 五 启动集群
- 1 启动ZooKeeper集群
- 2 格式化 ZooKeeper 集群目的是在 ZooKeeper 集群上建立 HA 的相应节点
- 3 启动JournalNode集群
- 4 格式化集群的 NameNode
- 5 启动刚格式化的 NameNode
- 6 同步 NameNode1 元数据到 NameNode2 上
- 7 启动 NameNode2
- 8 启动集群中所有的DataNode
- 9 在 RM1 启动 YARN
- 10 在 RM2 单独启动 YARN
- 11 启动 ZKFC
- 12 开启历史日志服务
- 13 总结
- 六 运行 Hadoop自带 wordcount 程序
- 1 找到 Hadoop 自带的 examples 处
- 2 确保离开安全模式
- 3 在 HDFS 创建数据目录
- 4 上传本地文件到 HDFS
- 5 运行 WordCount 例子
一. 规划
集群中各机器的配置均相同:
- CPU x3
- 内存 25G
- 硬盘 1.5T
1.1 软件版本
| 组件名 | 版本 | 下载地址 |
|---|---|---|
| JDK | java version “1.8.0_60” | http://www.oracle.com/technetwork/java/javase/downloads/index.html |
| Hadoop | hadoop-2.5.0-cdh5.3.2.tar.gz | http://archive.cloudera.com/cdh5/cdh/5/ |
| Zookeeper | zookeeper-3.4.5-cdh5.3.2.tar.gz | http://archive.cloudera.com/cdh5/cdh/5/ |
1.2 主机规划
| IP | 主机名 | 用户名 | 部署模块 | 进程 |
|---|---|---|---|---|
| 10.6.3.43 | master5 | hadoop5 | NameNode ResourceManager |
NameNode DFSZKFailoverController ResourceManager JobHistoryServer |
| 10.6.3.33 | master52 | hadoop5 | NameNode ResourceManager |
NameNode DFSZKFailoverController ResourceManager JobHistoryServer |
| 10.6.3.48 | slave51 | hadoop5 | DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
| 10.6.3.32 | slave52 | hadoop5 | DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
| 10.6.3.36 | slave53 | hadoop5 | DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
1.3 变量名及目录路径规划
| 目录名 | 路径 |
|---|---|
| 临时 tar.gz 安装包 | /home/hadoop5/softwares/tar_packages |
| 环境变量修改文件 | /home/hadoop5/.bash_profile |
| 集群所在目录 | /usr/local/cluster |
| $JAVA_HOME | /usr/local/jdk1.8.0_60 |
| $HADOOP_HOME | /usr/local/cluster/hadoop |
| $ZOOKEEPER_HOME | /usr/local/cluster/zookeeper |
Note: 以上路径若不存在,则直接按照以下命令直接创建,并修改相关属性即可,其他类似
sudo mkdir -p /usr/local/cluster
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/二. 环境准备
2.1 创建 hadoop 用户
在集群中的每台机器都创建特定且相同的 Hadoop 用户账号可以区分 Hadoop 和本机上的其他服务,本教程创建的是 hadoop5 用户。
相关配置请参考 《Centos6.5 创建新用户》
2.2 网络配置
- 要确保集群中的每台机器之间能够 ping 通
- 关闭防火墙 和 SeLinux
- 集群中的所有机器的 /etc/hosts 文件内容均一致,都要将集群中的各 IP 和 主机名对应起来
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.6.3.43 master5
10.6.3.33 master52
10.6.3.48 slave51
10.6.3.32 slave52
10.6.3.36 slave53请参考 《Centos6.5 网络配置 》
2.3 安装 JDK
本教程安装的 java version “1.8.0_60” 的 jdk。相关配置请参考 《 Centos6.5 JAVA配置 》
安装 jdk 路径为 /usr/local/jdk1.8.0_60 。 请参考 《变量名及目录路径规划》
2.4 配置 SSH 免密码通信
相关配置请参考 《Centos6.5下SSH免密码登陆配置》
2.5 VNC 配置 (可选)
配置 VNC 是可选的,对搭建 hadoop 不是必需的,但因为提供了图形化操作界面,还是有必要安装下。相关教程请参考 《 Centos6.5 VNC 配置 》
三. 安装 ZooKeeper
按照 主机规划 中,仅在 slave51、slave52、slave53 的节点上安装搭建 ZooKeeper 的复制模式 (Replicated Mode)。
详细的安装步骤请参考 :《 ZooKeeper 搭建》
ZooKeeper 的主进程 QuorumPeerMain 可以先不用启动,本文的最后,会梳理整个 HA 模式下启动的流程顺序。
四. 安装 Hadoop (重点)
4.1 下载,解压,配置环境变量
在 master5 的节点上,将从官网上下载的 hadoop tar 包解压至相应目录,详见 《变量名及目录路径规划》
1. 创建相应目录
sudo mkdir -p /usr/local/cluster/hadoop
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/创建,并修改成功之后应该是如下这样,否则就是各种权限不足的问题了:

2. 解压 tar 包至指定目录
sudo tar -zxvf ~/softwares/tar_packages/hadoop-2.5.0-cdh5.3.2.tar.gz -C /usr/local/cluster/hadoop --strip-components 1
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/hadoop
3. 替换本地库文件
因为在 lib/native 路径下,没有任何文件,这个就涉及到编译源码的问题了。有兴趣详见:Hadoop-2.5.0-cdh5.3.2 获取源码及编译。
将编译之后的 lib/native 下的所有库文件都拷贝到解压后的 hadoop 包下的 lib/native 下。如下图

需要注意的是:最好保证编译时的机器环境与你搭建的集群环境是相同的,不容易出错。相关的 lib/native 包,笔者已上传 http://download.csdn.net/detail/u011414200/9201161
4. 配置环境变量
登陆到集群中每台机器上完成该配置:
vim ~/.bash_profile添加如下:
export HADOOP_HOME=/usr/local/cluster/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin并执行以下命令,使环境变量生效
source ~/.bash_profile4.2 修改配置文件
需要修改文件名:
| 文件名称 | 格式 | 描述 |
|---|---|---|
| hadoop-env.sh | Bash 脚本 | 记录脚本中要用到的环境变量,以运行 Hadoop |
| core-site.xml | Hadoop 配置 XML | Hadoop Core 的配置项,例如 HDFS 和 MapReduce 常用的 I/O 设置等 |
| hdfs-site.xml | Hadoop 配置 XML | Hadoop 守护进程的配置项,包括 namenode 和 datanode |
| mapred-site.xml | Hadoop 配置 XML | MapReduce 守护进程的配置项 |
| yarn-site.xml | xml | Yarn 守护进程的配置项:资源管理器、作业历史服务器、Web 应用程序代理服务器和节点管理器 |
| slaves | 纯文本 | 运行 datanode 和 tasktracker 的机器列表(每行一个) |
cd /usr/local/cluster/hadoop/etc/hadoop/
1. 修改 $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim hadoop-env.sh其中修改的 JAVA_HOME 只要操作这一次,就能够保证整个集群使用同一版本的 Java。完整添加的代码如下
export JAVA_HOME=/usr/local/jdk1.8.0_60
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- 添加
-Djava.library.path到变量HADOOP_OPTS中,是为了让 HADOOP 能正确地指向本地库
2. 修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml
vim hdfs-site.xml在 <configuration> 与 </configuration> 之间添加如下内容
<property>
<name>dfs.nameservices</name>
<value>bigdata</value>
<description>the logical name for this new nameservice</description>
</property>
<property>
<name>dfs.ha.namenodes.bigdata</name>
<value>master5,master52</value>
<description>unique identifiers for each NameNode in the nameservice</description>
</property>
<!-- master5 RPC address -->
<property>
<name>dfs.namenode.rpc-address.bigdata.master5</name>
<value>master5:8020</value>
<description>the fully-qualified RPC address for NameNode master5 to listen on</description>
</property>
<!-- master5 http address -->
<property>
<name>dfs.namenode.http-address.bigdata.master5</name>
<value>master5:50070</value>
<description>the fully-qualified HTTP address for NameNode master5 to listen on</description>
</property>
<!-- master52 RPC address -->
<property>
<name>dfs.namenode.rpc-address.bigdata.master52</name>
<value>master52:8020</value>
<description>the fully-qualified RPC address for NameNode master52 to listen on</description>
</property>
<!-- master52 http address -->
<property>
<name>dfs.namenode.http-address.bigdata.master52</name>
<value>master52:50070</value>
<description>the fully-qualified HTTP address for NameNode master52 to listen on</description>
</property>
<!-- JournalNode Configuration -->
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
<description>listen port of JournalNode web UI </description>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<!-- NameNode data JournalNode postion -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave51:8485;slave52:8485;slave53:8485/bigdata</value>
<description>the URI which identifies the group of JNs where the NameNodes will write/read edits </description>
</property>
<!-- JournalNode in disk postion -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/cluster/data/journal</value>
<description> the path where the JournalNode daemon will store its local state </description>
</property>
<!-- on/off NameNode failed switch -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>on/off NameNode failed switch</description>
</property>
<!-- switch ways -->
<property>
<name>dfs.client.failover.proxy.provider.bigdata</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>the Java class that HDFS clients use to contact the Active NameNode</description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
<description>指定ZooKeeper超时间隔,单位毫秒</description>
</property>
<!-- isolation mechanism-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
<description>SSH to the Active NameNode and kill the process</description>
</property>
<!-- use sshfence isolation mechanism need ssh login -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop5/.ssh/id_rsa</value>
<description>use sshfence isolation mechanism need ssh login</description>
</property>
<!-- sshfence time -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
<description>sshfence time</description>
</property>
<!-- hdfs basic configuration -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/cluster/data/namenode</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:/usr/local/cluster/data/namenode/edit_files</value>
<description>path to restore transaction file(edits) in namenode</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/cluster/data/datanode</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
<description>max number of file which can be opened in a datanode</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
参数过多就不一一介绍了,首先笔者给所搭建的集群自定义取名为 “bigdata”,然后设置了 master5 和 master52 两台机器的 rpc 及 http 的端口号。接着设置了关于 zookeeper 的属性,其中 slave51,slave52,slave53 上运行 zookeeper 和 journal 进程,并设置了相应存储的本地目录。下一步就是设置了基本属性,比如副本数为 3,namenode 和 datanode 的本地文件目录,namenode 上最大处理打开的文件数为 4096。更多详细信息,请查看 《HDFS 详细配置》
3. 修改 $HADOOP_HOME/etc/hadoop/core-site.xml
vim core-site.xml在 <configuration> 与 </configuration> 之间添加如下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/cluster/data/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata</value>
<description>the default path prefix used by the Hadoop FS client when none is given </description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave51:2181,slave52:2181,slave53:2181</value>
<description>this lists the host-port pairs running the ZooKeeper service</description>
</property>hdfs://bigdata中的 bigdta 即为你所搭建的 nameservice ID,这在 hdfs-site.xml 中自定义设置过hadoop.tmp.dir是 hadoop 文件系统依赖的基础配置,自定义输出路径ha.zookeeper.quorum中,添加 zookeeper 集群中所有主机ip(或主机名):client 连接 zookeeper 端口号(默认2181)
更多解释请参考 《配置自动故障转移》
4. 修改 $HADOOP_HOME/etc/hadoop/yarn-site.xml
vim yarn-site.xml在 <configuration> 与 </configuration> 之间添加如下内容
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>Enable RM HA</description>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
<description>Enable automatic failover; By default, it is enabled only when HA is enabled</description>
</property>
<!-- 使嵌入式自动故障转移。HA环境启动,与 ZKRMStateStore 配合处理fencing -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
<description>Use embedded leader-elector to pick the Active RM, when automatic failover is enabled. By default, it is enabled only when HA is enabled</description>
</property>
<!-- RM cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_HA_ID</value>
<description>Identifies the cluster. Used by the elector to ensure an RM doesn’t take over as Active for another cluster</description>
</property>
<!-- RM name -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>List of logical IDs for the RMs. e.g., “rm1,rm2”</description>
</property>
<!-- RM address-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master5</value>
<description>For each rm-id, specify the hostname the RM corresponds to. Alternately, one could set each of the RM’s service addresses</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master52</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--zk address -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>slave51:2181,slave52:2181,slave53:2181</value>
<description>Address of the ZK-quorum. Used both for the state-store and embedded leader-election</description>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
<description>The class to be used by Clients, AMs and NMs to failover to the Active RM</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
<description>total memory (MB) which cen be used in computing in a datanode</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>3</value>
<description>total cpu number which cen be used in computing in a datanode</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master5:19888/jobhistory/logs/</value>
</property>
<!--当一台机器上运行大于1个的 RM 时,必须要在 namenode1 上单独配置rm1,在namenode2上单独配置rm2-->
<!--> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <description>Identifies the RM in the ensemble. If we want to launch more than one RM in single node, we need this configuration</description> </property> <-->- yarn.nodemanager.aux-services 设置为 mapreduce_shuffle 是因为 YARN 是一个通用目的服务,MapReduce 的 shuffle 句柄还需要显式地被启用
- yarn.nodemanager.resource.cpu-vcores 设置
- yarn.resourcemanager.ha.id 属性说明在同一个节点上,如果同时开启了不止一个的 RM,就必须在每个 RM 上 “单独”、”单独”、”单独” 地对这个属性进行配置。这跟我们一般喜欢把配置好的文件复制到其他机器上的习惯有点区别,切记!因为这个选项是可选的,换句话说,如果一个节点上只启动一个 RM ,就不用设置了,免得辣么麻烦了….
5. 修改mapred-site.xml
将 mapred-site.xml.template 复制 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml在 <configuration> 与 </configuration> 之间添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master5:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master5:19888</value>
</property>- 当 YARN 运行 MapReduce 时,mapred-site.xml 文件仍被用于记录通用的 MapReduce 属性
- mapreduce.framework.name 属性必须要设置为 yarn ,这样客户端才会使用 YARN 而非其他
6. 修改 yarn-env.sh
vim yarn-env.sh添加下图红框所标识处:

完整代码如下
if [ "x$JAVA_LIBRARY_PATH" != "x" ]; then
YARN_OPTS="$YARN_OPTS -Djava.library.path=$JAVA_LIBRARY_PATH"
else
YARN_OPTS="$YARN_OPTS -Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
fi如果不加这个,当启动 YARN 时会报如下 WARN ,添加之后,WARN 消失
WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
- 修改方式2:
添加以下代码,如下图所示
JAVA_LIBRARY_PATH="$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
7. 修改 slaves
vim /usr/local/cluster/hadoop/etc/hadoop/slaves把原来的 localhost 给删除了,随后添加所有 datanode 的主机名
slave51
slave52
slave534.3 分发程序
cd /usr/local/cluster
scp -r hadoop/ hadoop5@master52:/usr/local/cluster/
scp -r hadoop/ hadoop5@slave51:/usr/local/cluster/
scp -r hadoop/ hadoop5@slave52:/usr/local/cluster/
scp -r hadoop/ hadoop5@slave53:/usr/local/cluster/五. 启动集群
注意:在启动之前务必将配置文件都检查清楚,包括环境变量设置且生效,最后要严格按照以下的步骤启动。
5.1 启动ZooKeeper集群
在集群中安装 ZooKeeper 的主机上启动 ZooKeeper 服务。在本教程中也就是在 slave51、slave52、slave53 的主机上启动相应进程。分别登陆到三台机子上执行:
zkServer.sh startslave51、slave52、slave53 三台机子上启动了 Zookeeper 的主进程 QuorumPeerMain
5.2 格式化 ZooKeeper 集群,目的是在 ZooKeeper 集群上建立 HA 的相应节点
在任意的 namenode 上都可以执行,笔者还是选择了 master5 主机执行格式化命令,此操作仅仅表示和 zk 集群发生关联
hdfs zkfc -formatZKNote:上述命令强烈建议读者自己手打,别复制。不然可能会报 Bad Argument -formatZK 的错误
随便挑一台 ZooKeeper 的主机进行验证,如直接在 slave51 上执行:
zkCli.sh
ls /
ls /hadoop-ha
ls /hadoop-ha/bigdata出现如下即可(其中 bigdata 是你在 hdfs-site.xml 文件中设置的集群名称):

5.3 启动JournalNode集群
分别在 slave51、slave52、slave53 上执行以下命令,因为这些机器之前已经在 hdfs-site.xml 的 dfs.namenode.shared.edits.dir 属性中设置过的
hadoop-daemon.sh start journalnode
这三台机器一定都要出现 JournalNode 进程,且在 /usr/local/cluster/data 本地磁盘路径下生成一个 journal 目录。
5.4 格式化集群的 NameNode
在 master5 的主机上执行以下命令,以格式化 namenode:
hdfs namenode -format格式化 NameNode 会在磁盘 /usr/local/cluster/data/ 目录下会出现产生 namenode、edit_files 目录(该这两个路径在 hdfs-site.xml 中设置)
5.5 启动刚格式化的 NameNode
刚在 master5 上格式化了 namenode ,故就在 master5 上执行
hadoop-daemon.sh start namenode出现如下 namenode 进程 :

5.6 同步 NameNode1 元数据到 NameNode2 上
复制你 NameNode 上的元数据目录到另一个 NameNode,也就是此处的 master5 复制元数据到 master52 上。在 master52 上执行以下命令:
hdfs namenode -bootstrapStandby在 master52 主机上的 /usr/local/cluster 下生成了 data 目录,且该 data 目录下的含有与 master5 相同的 namenode 目录,甚至里面的文件都一样(除了 in_use.lock 这个文件)
5.7 启动 NameNode2
master52 主机拷贝了元数据之后,就接着启动 namenode 进程了,执行
hadoop-daemon.sh start namenode在 master52 上出现 namenode进程

5.8 启动集群中所有的DataNode
在 master5 上执行
hadoop-daemons.sh start datanode- 在 master5 (master52进程也一样)上显示:

- 在各个 slave 的上的进程(以 slave51 为例)

- 各个 slave 主机上 在 /usr/local/cluster/data/ 路径下生成 datanode 目录(路径在 hdfs-site.xml 设置)
5.9 在 RM1 启动 YARN
在 master5 的主机上执行以下命令:
start-yarn.sh在 master5 的主机上查看进程多了 ResourceManager:

在 slave51、slave52、slave53 上查看到进程多了 NodeManager

5.10 在 RM2 单独启动 YARN
虽然上一步启动了 YARN ,但是在 master52 上是没有相应的 ResourceManager 进程,故需要在 master52 主机上单独启动:
yarn-daemon.sh start resourcemanager在 master52 上多出了 ResourceManager 进程:

5.11 启动 ZKFC
在 master5 和 master52 的主机上分别执行如下命令:
hadoop-daemon.sh start zkfc在 master5 和 master52 上都可以看到多出了 DFSZKFailoverController 进程

此时在两个浏览器上分别输入:
http://10.6.3.43:50070/dfshealth.html#tab-overview
http://10.6.3.33:50070/dfshealth.html#tab-overview

5.12 开启历史日志服务
只在 master5 的主机上执行
mr-jobhistory-daemon.sh start historyserver在 master5 上可以看到多出的 JobHistoryServer 进程

5.13 总结
- 安装完成后各节点上的进程,请点 这里
- 关于Hadoop 启动过程详解,请点 这里
- 关于启动常见问题与解答,请点 这里
- 关于 HDFS 的 HA 手工/自动故障切换,请点 这里
- 关于 YARN 的 HA 手工/自动故障切换,请点 这里
- HA 模式下的 Hadoop+ZooKeeper+HBase 启动顺序,请点 这里
六. 运行 Hadoop自带 wordcount 程序
6.1 找到 Hadoop 自带的 examples 处
cd /usr/local/cluster/hadoop/share/hadoop/mapreduce
ls -al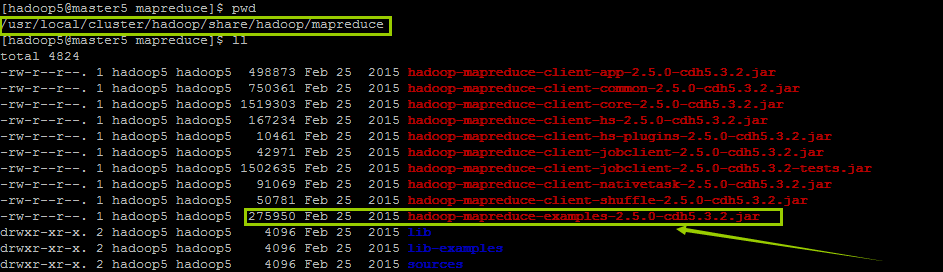
就是图中的 hadoop-mapreduce-examples-2.5.0-cdh5.3.2.jar ,它所包含的测试用例包括

6.2 确保离开安全模式
- 查看当前 hdfs 是否处于安全模式
hdfs dfsadmin -safemode get
若都是 OFF ,则说明当前不处于安全模式,否则执行以下命令
hdfs dfsadmin -safemode leave6.3 在 HDFS 创建数据目录
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output/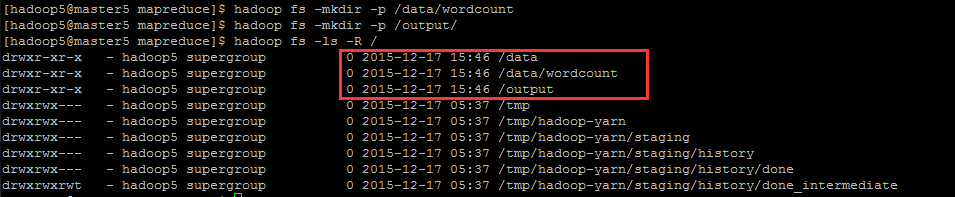
6.4 上传本地文件到 HDFS
hadoop fs -put /usr/local/cluster/hadoop/etc/hadoop/slaves /data/wordcount/
hadoop fs -ls /data/wordcount
hadoop fs -text /data/wordcount/slaves- 将 slaves 文件上传到 HDFS 中,并能直接查看上传到 HDFS 中 slaves 文件的内容

6.5 运行 WordCount 例子
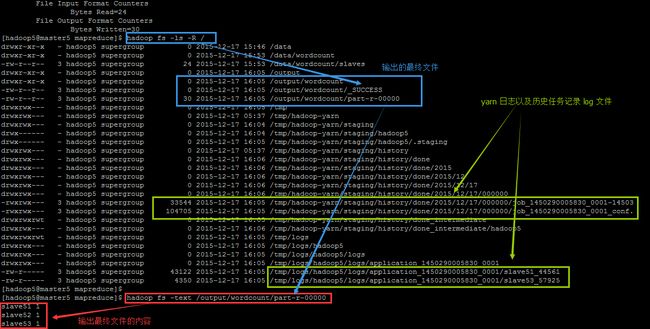
hadoop jar hadoop-mapreduce-examples-2.5.0-cdh5.3.2.jar wordcount /data/wordcount /output/wordcount在成功执行之后,查看 HDFS 文件目录和最终的输出文件内容
hadoop fs -ls -R /
hadoop fs -text /output/wordcount/part-r-00000能出现如下界面,那么恭喜你,安装成功!不谢~: