聊天系统中的用户列表并发问题分析
1.问题描述
2.问题分析
class user{
public:
uint64_t user_id;
/*todo:用户信息基本信息*/
pthread_mutex_t mutex; /*用于保护user的多线程并发*/
}
std::map<uint64_t, user*> user_map;
pthread_mutex_t user_map_mutex; /*多线程操作时保护user_map*/
对map管理的用户列表需要提供增、删、改、查和遍历。例如向某一个用户进行操作:
LOCK(user_map_mutex);
std::map<uint64_t, user*>::iterator it = user_map.find(id);
if(it != user_map.end()){
UNLOCK(user_map_mutex);
LOCK(it->second->mutex);
operator(it->second); /*可能时间比较长,可能是发送网络报文、信息写盘、RPC调用等*/
UNLOCK((it->second->mutex);
}
else
UNLOCK(user_map_mutex);
其他操作类似。这个实现有几个严重的并发问题:
1.每次操作都需要对user_map进行LOCK
2.每次对某个用户操作都需要对用户LOCK
3.每次对用户操作的函数可能时间会比较长,例如socket发包、RPC调用等。3.user并发竞争优化
class user{
public:
string user_id;
/*其他的一些用户信息*/
Int ref; /*引用计数为0时,free掉这个对象*/
}
void add_ref(user* u){
u->ref ++;
}
void release_ref(user* u){
u->ref --;
if(u->ref <= 0) delete u;
}
引用计数的操作规则:
在用户信息加入用户列表的时候,add_ref
在用户从用户列表中删除的时候,release_ref
在用户信息被引用的时候,add_ref
在用户信息引用完毕的时候,release_ref那么对某个用户的操作就会变成:
LOCK(user_map_mutex);
std::map<uint64_t, user*>::iterator it = user_map.find(id);
if(it != user_map.end()){
user* u = it->second;
add_ref(u);
UNLOCK(user_map_mutex);
operator(it->second); /*有可能时间比较长*/
release_ref(u);
}
else
UNLOCK(user_map_mutex);
User对象引用计数很好的解决的User加锁的问题,但引用计数的引入了一个新的问题就是在多个线程同时修改某一个用户信息时,
会引发数据无法保护的问题。我们处理里这个问题很简单。不管是增加操作、修改操作和删除操作,都遵循先必须将user_map中已存在的对应的user信息从map中删除,再做信息新增。例如修改操作:
LOCK(user_map_mutex);
std::map<uint64_t, user*>::iterator it = user_map.find(id);
if(it != user_map.end()){
/*将旧的信息拷贝出来*/
user* u =it->second;
user_map.erase(it);
copy(update_u, u);
release_ref(u); /*解除引用*/
update(update_u); /*修改用户数据*/
Add_ref(update_u);
user_map.insert(update_u);
UNLOCK(user_map_mutex);
}
else
UNLOCK(user_map_mutex);
增加和删除的实现类似。对象引用计数很好的解决的用户数据锁竞争的问题,但在user_map的用户数小于1万以下,使用引用计数可以把增删改查操作的并发问题避免掉。不能解决全map扫描并发问题,也不能解决在user_map很大时大量需要操作用户信息的并发问题。问题出在不管是全map扫描还是对单个用户都需要对user_map进行上锁,这就是第一个问题了。在高并发请求下,这个user_map锁会产生大量的竞争,造成资源损耗。
4.放弃std::map
要去掉这个锁,这就回到了在 问题分析中的第一个问题上,众所周知,std::map是不支持多线程并发的,而且std::map操作对CPU cache并不友好。去掉这个全局锁改用更小粒度的锁,那就需要放弃std::map。在大量数据的情况下,一般会采用hash table或则btree来组织数据(研究过数据库存储引擎的人都知道,呵呵!)。简单起见,这里就以hash table为例来展开分析。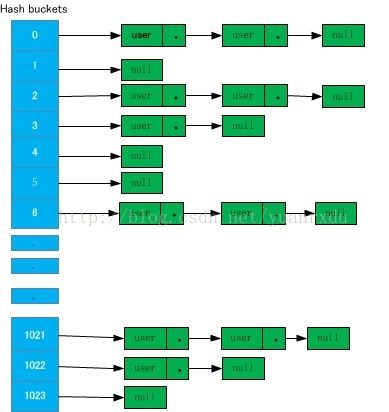
图-2是一个hash table的结构图,其中hash buckets是个数组。数组内有一个指向user结构的指针。好,了解了hash table的结构我们再回到前面缩小锁粒度的问题上来。例如我们定义了一个hash table,它的buckets个数为1024,我们再定义一个pthread_mutex_t数组,长度为256。缩小锁的粒度很简单。
第一个mutex数组单元负责0 256 512 768序号bucket的互斥,第二个负责1 257 512 769序号的并发互斥,类推。计算一个bucket序号是由哪个mutex负责互斥的其实就是:这样实现很容易理解,在内部的user对象操作我们还是采用引用计数的方法。细分了锁粒度,能让整个用户列表具有非常好的并发性,同时因为buckets是个连续的数组,对CPU L1/L2 cahce也非常的友好,也大大提高了CPU Cache的命中率问题。一般优化到此,基本上可以说做到了90%的工作。但还是有几个疑问:
Ø 为什么要用pthread_mutex_t?在高并发下它会不会引起不必要的操作系统上下文切换?
Ø 除了hash table之外还有什么数据结构能支持细粒度的锁?
void LOCK(int* q){
int i;
while(__sync_lock_test_and_set(q, 1)){
for(i = 0; i < 32; i ++) cpu_pause();
sched_yield(); /*释放CPU执行权,让操作系统重新调度本线程*/
}
};
#define UNLOCK(q) __sync_lock_release((q))
那么就可以将pthread_mutex_t数组去掉,由一个int数组来代替他的工作。
为什么可以这样实现?在lock函数里面难道空转不耗CPU么?这个可以结合我们的hash table来分析,一次hash table的增删改查操作,一般几百个CPU指令周期就可以完成(不计算hash函数运行时间,因为计算hash(key)无需等待锁),也就是说在LOCK等待的时间不长,而且CPU的指令执行速度远远大于CPU从内存中载入数据的速度,所以用CPU spin等待来换取操作系统因为pthread lock造成的上下文切换损耗是值得的。这个可以自行去测试,呵呵。
对于这种hashtable结构并发量,我做了个初步的测试,测试机配置:4核2.4GCPU,内存16G,程序启动8个线程进行测试,hashtable存有800万个用户信息,每秒可以支持100万个左右查询,50万左右的增删改。
5.思考
回到最初的问题,其实就是在内存中管理一个海量内存对象的问题,这不是什么新技术,在数据库存储引擎中,随处可以看到这样的解决方案,例如:memcache的索引实现、innodb的自适应hash索引实现和btree实现、lsm树的memtable实现,无一不是解决此类问题的。通过这个问题的分析,可以得到以下几个认识:
1. C++从业人员在高并发设计上应该慎用stl/boost,它们的很多数据结构对多核并发并不友好,这里仅仅是针对C++说的。
2. 很多看似非常难的问题,其实很多其他领域的系统有很好的解决方案。作为C/C++从业人员,应该多去了解数据库内核、操作系统内核或者编程语言内核(JVM/GOruntime)。这三个地方有挖不完的技术宝藏。
3. C/C++语言在多核并发控制上可以说很原始,作为C/C++从业人员的我们,应该多去了解CPU的工作机制、C/C++的内存模型等,这样有利于我们去分析系统瓶颈和优化系统。
4. 放弃意味着收获更多,放弃C++,选用更容易编写并发程序的语言编写此类系统,例如go、scala、erlang。
遗留的思考题:
1. 用CPU CAS + memory barrier怎么实现hash table的无锁并发?可以尝试去实现一下看看。
2. 除了用hash table解决海量用户列表问题,还可以用skip list、btree等数据结构来实现,怎么实现?skip list、btree和hash table对比优劣势在什么地方?
3. hashtable在管理海量用户列表时,它有缺点么?有什么样的缺点?