Mahout推荐算法之SlopOne
Mahout推荐算法之SlopOne
一、 算法原理
有别于基于用户的协同过滤和基于item的协同过滤,SlopeOne采用简单的线性模型估计用户对item的评分。如下图,估计UserB对ItemJ的偏好

图(1)
在真实情况下,该方法有如下几个问题:
1. 为什么要选择UserA计算?
2. 对大量稀疏的情况如何处理,而这种情况是最为普遍的。
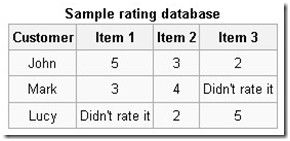
图(2)
Item1和item2的相似度:((5-3)+(3-4))/2=0.5
Item1和Item3的相似度:(5-2)/1=3
Lucy对Item1的评估预估计为:((2+0.5)*2+(3+5)*1)/(2+1)=4.333
Item3和Item1的相似度:(2-3)/1=-1
Item3和Item2的相似度:(5-2)/1=3
Make对item3的评分预估计为:((4+3)*1+(3-1)*1)/(1+1)=4.5
通过以上例子可以看出:需要计算item对之间的平均差别,以及item对之间的差别次数。
Mahout给出的训练伪代码:
| for every item i for every other item j for every user u expressing preference for both i and j add the difference in u’s preference for i and j to an average
|
推荐伪代码:
for every item i the user u expresses no preference for for every item j that user u expresses a preference for find the average preference difference between j and i add this diff to u’s preference value for j add this to a running average return the top items, ranked by these averages |
二、 单机模型实现
(一) 构建difference
1. 单机模型构建(MemoryDiffStorage)
private void buildAverageDiffs() throws TasteException { log.info("Building average diffs..."); try { buildAverageDiffsLock.writeLock().lock(); averageDiffs.clear(); long averageCount = 0L; LongPrimitiveIterator it = dataModel.getUserIDs(); while (it.hasNext()) { averageCount = processOneUser(averageCount, it.nextLong()); } pruneInconsequentialDiffs(); updateAllRecommendableItems(); } finally { buildAverageDiffsLock.writeLock().unlock(); } } private void pruneInconsequentialDiffs() { // Go back and prune inconsequential diffs. "Inconsequential" means, here, only represented by one // data point, so possibly unreliable Iterator<Map.Entry<Long,FastByIDMap<RunningAverage>>> it1 = averageDiffs.entrySet().iterator(); while (it1.hasNext()) { FastByIDMap<RunningAverage> map = it1.next().getValue(); Iterator<Map.Entry<Long,RunningAverage>> it2 = map.entrySet().iterator(); while (it2.hasNext()) { RunningAverage average = it2.next().getValue(); if (average.getCount() <= 1) { it2.remove(); } } if (map.isEmpty()) { it1.remove(); } else { map.rehash(); } } averageDiffs.rehash(); } private void updateAllRecommendableItems() throws TasteException { FastIDSet ids = new FastIDSet(dataModel.getNumItems()); for (Map.Entry<Long,FastByIDMap<RunningAverage>> entry : averageDiffs.entrySet()) { ids.add(entry.getKey()); LongPrimitiveIterator it = entry.getValue().keySetIterator(); while (it.hasNext()) { ids.add(it.next()); } } allRecommendableItemIDs.clear(); allRecommendableItemIDs.addAll(ids); allRecommendableItemIDs.rehash(); } private long processOneUser(long averageCount, long userID) throws TasteException { log.debug("Processing prefs for user {}", userID); // Save off prefs for the life of this loop iteration PreferenceArray userPreferences = dataModel.getPreferencesFromUser(userID); int length = userPreferences.length(); for (int i = 0; i < length; i++) { // Loop to length-1, not length-2, not for diffs but average item pref float prefAValue = userPreferences.getValue(i); long itemIDA = userPreferences.getItemID(i); FastByIDMap<RunningAverage> aMap = averageDiffs.get(itemIDA); if (aMap == null) { aMap = new FastByIDMap<RunningAverage>(); averageDiffs.put(itemIDA, aMap); } for (int j = i + 1; j < length; j++) { // This is a performance-critical block long itemIDB = userPreferences.getItemID(j); RunningAverage average = aMap.get(itemIDB); if (average == null && averageCount < maxEntries) { average = buildRunningAverage(); aMap.put(itemIDB, average); averageCount++; } if (average != null) { average.addDatum(userPreferences.getValue(j) - prefAValue); } } RunningAverage itemAverage = averageItemPref.get(itemIDA); if (itemAverage == null) { itemAverage = buildRunningAverage(); averageItemPref.put(itemIDA, itemAverage); } itemAverage.addDatum(prefAValue); } return averageCount; } private RunningAverage buildRunningAverage() { return stdDevWeighted ? new FullRunningAverageAndStdDev() : new FullRunningAverage(); } |
2. MapReduce模式构建(FileDiffStorage)
用MapReduce模式计算difference的部分参看下文。该方式是离线计算模式,不能实施更新,适合大数据量。由于mapreduce模式计算了所有item之间的全部值,故比单机模式更准确。构建好之后拷贝到本地,使用用FileDiffStorage(newFile("diff"), 500) 即可。FileDiffStorage不支持添加和删除pereference(实际上也是不能这么做的);
| private void buildDiffs() { if (buildAverageDiffsLock.writeLock().tryLock()) { try {
averageDiffs.clear(); allRecommendableItemIDs.clear();
FileLineIterator iterator = new FileLineIterator(dataFile, false); String firstLine = iterator.peek(); while (firstLine.isEmpty() || firstLine.charAt(0) == COMMENT_CHAR) { iterator.next(); firstLine = iterator.peek(); } long averageCount = 0L; while (iterator.hasNext()) { averageCount = processLine(iterator.next(), averageCount); }
pruneInconsequentialDiffs(); updateAllRecommendableItems();
} catch (IOException ioe) { log.warn("Exception while reloading", ioe); } finally { buildAverageDiffsLock.writeLock().unlock(); } } }
private long processLine(String line, long averageCount) {
if (line.isEmpty() || line.charAt(0) == COMMENT_CHAR) { return averageCount; }
String[] tokens = SEPARATOR.split(line); Preconditions.checkArgument(tokens.length >= 3 && tokens.length != 5, "Bad line: %s", line);
long itemID1 = Long.parseLong(tokens[0]); long itemID2 = Long.parseLong(tokens[1]); double diff = Double.parseDouble(tokens[2]); int count = tokens.length >= 4 ? Integer.parseInt(tokens[3]) : 1; boolean hasMkSk = tokens.length >= 5;
if (itemID1 > itemID2) { long temp = itemID1; itemID1 = itemID2; itemID2 = temp; }
FastByIDMap<RunningAverage> level1Map = averageDiffs.get(itemID1); if (level1Map == null) { level1Map = new FastByIDMap<RunningAverage>(); averageDiffs.put(itemID1, level1Map); } RunningAverage average = level1Map.get(itemID2); if (average != null) { throw new IllegalArgumentException("Duplicated line for item-item pair " + itemID1 + " / " + itemID2); } if (averageCount < maxEntries) { if (hasMkSk) { double mk = Double.parseDouble(tokens[4]); double sk = Double.parseDouble(tokens[5]); average = new FullRunningAverageAndStdDev(count, diff, mk, sk); } else { average = new FullRunningAverage(count, diff); } level1Map.put(itemID2, average); averageCount++; }
allRecommendableItemIDs.add(itemID1); allRecommendableItemIDs.add(itemID2);
return averageCount; }
private void pruneInconsequentialDiffs() { // Go back and prune inconsequential diffs. "Inconsequential" means, here, only represented by one // data point, so possibly unreliable Iterator<Map.Entry<Long,FastByIDMap<RunningAverage>>> it1 = averageDiffs.entrySet().iterator(); while (it1.hasNext()) { FastByIDMap<RunningAverage> map = it1.next().getValue(); Iterator<Map.Entry<Long,RunningAverage>> it2 = map.entrySet().iterator(); while (it2.hasNext()) { RunningAverage average = it2.next().getValue(); if (average.getCount() <= 1) { it2.remove(); } } if (map.isEmpty()) { it1.remove(); } else { map.rehash(); } } averageDiffs.rehash(); }
private void updateAllRecommendableItems() { for (Map.Entry<Long,FastByIDMap<RunningAverage>> entry : averageDiffs.entrySet()) { allRecommendableItemIDs.add(entry.getKey()); LongPrimitiveIterator it = entry.getValue().keySetIterator(); while (it.hasNext()) { allRecommendableItemIDs.add(it.next()); } } allRecommendableItemIDs.rehash(); } |
(二) 估值
private float doEstimatePreference(long userID, long itemID) throws TasteException { double count = 0.0; double totalPreference = 0.0; PreferenceArray prefs = getDataModel().getPreferencesFromUser(userID); RunningAverage[] averages = diffStorage.getDiffs(userID, itemID, prefs); int size = prefs.length(); for (int i = 0; i < size; i++) { RunningAverage averageDiff = averages[i]; if (averageDiff != null) { double averageDiffValue = averageDiff.getAverage(); if (weighted) { double weight = averageDiff.getCount(); if (stdDevWeighted) { double stdev = ((RunningAverageAndStdDev) averageDiff).getStandardDeviation(); if (!Double.isNaN(stdev)) { weight /= 1.0 + stdev; } // If stdev is NaN, then it is because count is 1. Because we're weighting by count, // the weight is already relatively low. We effectively assume stdev is 0.0 here and // that is reasonable enough. Otherwise, dividing by NaN would yield a weight of NaN // and disqualify this pref entirely } totalPreference += weight * (prefs.getValue(i) + averageDiffValue); count += weight; } else { totalPreference += prefs.getValue(i) + averageDiffValue; count += 1.0; } } } if (count <= 0.0) { RunningAverage itemAverage = diffStorage.getAverageItemPref(itemID); return itemAverage == null ? Float.NaN : (float) itemAverage.getAverage(); } else { return (float) (totalPreference / count); } } |
(三) 推荐
对于在线推荐系统,允许只有一个SlopeOneRecommender实例。
| 方法签名 |
说明 |
备注 |
| public void setPreference(long userID, long itemID, float value) |
添加偏好,线上系统经常需要。 |
动态添加偏好,添加之后会更新ItemID的和其他Item之间的相似度 |
| public void removePreference(long userID, long itemID) |
删除偏好,很少用。 |
删除偏好后,会更新itemId和其他Item之间的相似度 |
| public List<RecommendedItem> recommend(long userID, int howMany, IDRescorer rescorer) |
提供推荐。IDRescorer用于商业规则,调整item的得分 |
1.获取userId还未评分的item作为候选。2.估计每个Item的得分,选取topk 返回。 |
| public float estimatePreference(long userID,long itemID) |
估计userId对ItemId的评分 |
如userId对itemId有真实的值,则返回,否则估计。 |
1. 推荐接口
public List<RecommendedItem> recommend(long userID, int howMany, IDRescorer rescorer) throws TasteException { Preconditions.checkArgument(howMany >= 1, "howMany must be at least 1"); log.debug("Recommending items for user ID '{}'", userID); FastIDSet possibleItemIDs = diffStorage.getRecommendableItemIDs(userID); TopItems.Estimator<Long> estimator = new Estimator(userID); List<RecommendedItem> topItems = TopItems.getTopItems(howMany, possibleItemIDs.iterator(), rescorer, estimator); log.debug("Recommendations are: {}", topItems); return topItems; } |
2. 获取推荐候选项
public FastIDSet getRecommendableItemIDs(long userID) throws TasteException { FastIDSet result; try { buildAverageDiffsLock.readLock().lock(); result = allRecommendableItemIDs.clone(); } finally { buildAverageDiffsLock.readLock().unlock(); } Iterator<Long> it = result.iterator(); while (it.hasNext()) { if (dataModel.getPreferenceValue(userID, it.next()) != null) { it.remove(); } } return result; } |
3. 估计候选项的得分,返回topK个推荐列表
public static List<RecommendedItem> getTopItems(int howMany, LongPrimitiveIterator possibleItemIDs, IDRescorer rescorer, Estimator<Long> estimator) throws TasteException { Preconditions.checkArgument(possibleItemIDs != null, "argument is null"); Preconditions.checkArgument(estimator != null, "argument is null"); Queue<RecommendedItem> topItems = new PriorityQueue<RecommendedItem>(howMany + 1, Collections.reverseOrder(ByValueRecommendedItemComparator.getInstance())); boolean full = false; double lowestTopValue = Double.NEGATIVE_INFINITY; while (possibleItemIDs.hasNext()) { long itemID = possibleItemIDs.next(); if (rescorer == null || !rescorer.isFiltered(itemID)) { double preference; try { preference = estimator.estimate(itemID); } catch (NoSuchItemException nsie) { continue; } double rescoredPref = rescorer == null ? preference : rescorer.rescore(itemID, preference); if (!Double.isNaN(rescoredPref) && (!full || rescoredPref > lowestTopValue)) { topItems.add(new GenericRecommendedItem(itemID, (float) rescoredPref)); if (full) { topItems.poll(); } else if (topItems.size() > howMany) { full = true; topItems.poll(); } lowestTopValue = topItems.peek().getValue(); } } } int size = topItems.size(); if (size == 0) { return Collections.emptyList(); } List<RecommendedItem> result = Lists.newArrayListWithCapacity(size); result.addAll(topItems); Collections.sort(result, ByValueRecommendedItemComparator.getInstance()); return result; } |
三、 MapReduce实现(计算diff)
1. 计算每个user的item之间的差值
Map: 输入,文本文件,格式为:userId\t itemId\t val 输出:key userId,value itemId\t val |
Reduce: for(user u :users){ items of u for(int I =0 ;i<items.size;i++){ itema =items[i]; for(int j =i+1;j<items.size;j++){ itemb= items[j]; itemABdiff =itemb-itema; out.write(itemA\t itemb, itemABdiff); } } } |
2. 计算itemPair的全局平均
Map:输出数据不做处理,将item相同的数据传递到同一个reduce中。 |
Reduce: 输入 key itemA\t itemb ,val itemABdiff 计算改组数据的平均值(FullRunningAverageAndStdDev) 输出: key EntityEntityWritable ,valueFullRunningAverageAndStdDevWritable |
四、 实例演示
(一) 单机模式
MemoryDiffStorage mds =new MemoryDiffStorage(new FileDataModel(new File("pereference")), Weighting.WEIGHTED, 1000); SlopeOneRecommender sr =new SlopeOneRecommender(new FileDataModel(new File("pereference")),Weighting.WEIGHTED,Weighting.WEIGHTED,mds); System.out.println(sr.recommend(1, 10,new IDRescorer() { @Override public double rescore(long id, double originalScore) { int clickCount =10;//id的点击量 return originalScore*clickCount; } @Override public boolean isFiltered(long id) { //如果id和要推荐的item的id属于同一个类型,return false ,否则return true ; return false; } })); |
(二) MapReduce模式
String [] arg ={"-i","p","-o","diff"}; SlopeOneAverageDiffsJob.main(arg); DiffStorage ds =new FileDiffStorage(new File("diff"), 1000); SlopeOneRecommender sr =new SlopeOneRecommender(new FileDataModel(new File("pereference")),Weighting.WEIGHTED,Weighting.WEIGHTED,mds); System.out.println(sr.recommend(1, 10,new IDRescorer() { @Override public double rescore(long id, double originalScore) { int clickCount =10;//id的点击量 return originalScore*clickCount; } @Override public boolean isFiltered(long id) { //如果id和要推荐的item的id属于同一个类型,return false ,否则return true ; return false; } })); |
五、 参考文献
1. http://en.wikipedia.org/wiki/Slope_One
2. DanielLemire, Anna Maclachlan, SlopeOne Predictors for Online Rating-Based Collaborative Filtering
3. PuWang, HongWu Ye, A Personalized Recommendation Algorithm Combining Slope OneScheme and User Based Collaborative Filtering
4. DeJiaZhang, An Item-based Collaborative Filtering Recommendation AlgorithmUsing Slope One Scheme Smoothing
5. Mi,Zhenzhen and Xu, Congfu, A Recommendation Algorithm Combining Clustering Methodand Slope One Scheme
1. BadrulM. Sarwar, George Karypis, Joseph A. Konstan, John Riedl: Item-basedcollaborative filtering recommendation algorithms
2. GregLinden, Brent Smith, Jeremy York, "Amazon.com Recommendations:Item-to-Item Collaborative Filterin