Today, companies regularly generate terabytes of data in their daily operations. The sources include everything from data captured from network sensors, to the Web, social media, transactional business data, and data created in other business contexts. Given the volume of data being generated, real-time computation has become a major challenge faced by many organizations. A scalable real-time computation system that we have used effectively is the open-source Storm tool, which was developed at Twitter and is sometimes referred to as "real-time Hadoop." However, Storm is far simpler to use than Hadoop in that it does not require mastering an alternate universe of new technologies simply to handle big data jobs.
This article explains how to use Storm. The example project, called "Speeding Alert System," analyzes real-time data and raises a trigger and relevant data to a database, when the speed of a vehicle exceeds a predefined threshold.
Storm
Whereas Hadoop relies on batch processing, Storm is a real-time, distributed, fault-tolerant, computation system. Like Hadoop, it can process huge amount of data—but does so in real time — with guaranteed reliability; that is, every message will be processed. Storm also offers features such as fault tolerance and distributed computation, which make it suitable for processing huge amounts of data on different machines. It has these features as well:
- It has simple scalability. To scale, you simply add machines and change parallelism settings of the topology. Storm's usage of Hadoop's Zookeeper for cluster coordination makes it scalable for large cluster sizes.
- It guarantees processing of every message.
- Storm clusters are easy to manage.
- Storm is fault tolerant: Once a topology is submitted, Storm runs the topology until it is killed or the cluster is shut down. Also, if there are faults during execution, reassignment of tasks is handled by Storm.
- Topologies in Storm can be defined in any language, although typically Java is used.
To follow the rest of the article, you first need to install and set up Storm. The steps are straightforward:
- Download the Storm archive from the official Storm website.
- Unpack the bin/ directory onto your PATH and make sure the bin/storm script is executable.
Storm Components
A Storm cluster mainly consists of a master and worker node, with coordination done by Zookeeper.
Master Node:
The master node runs a daemon, Nimbus, which is responsible for distributing the code around the cluster, assigning the tasks, and monitoring failures. It is similar to the Job Tracker in Hadoop.
Worker Node:
The worker node runs a daemon, Supervisor, which listens to the work assigned and runs the worker process based on requirements. Each worker node executes a subset of a topology. The coordination between Nimbus and several supervisors is managed by a Zookeeper system or cluster.
Zookeeper
Zookeeper is responsible for maintaining the coordination service between the supervisor and master. The logic for a real-time application is packaged into a Storm "topology." A topology consists of a graph of spouts (data sources) and bolts (data operations) that are connected with stream groupings (coordination). Let's look at these terms in greater depth.
Spout:
In simple terms, a spout reads the data from a source for use in the topology. A spout can either be reliable or unreliable. A reliable spout makes sure to resend a tuple (which is an ordered list of data items) if Storm fails to process it. An unreliable spout does not track the tuple once it's emitted. The main method in a spout is nextTuple(). This method either emits a new tuple to the topology or it returns if there is nothing to emit.
Bolt:
A bolt is responsible for all the processing that happens in a topology. Bolts can do anything from filtering to joins, aggregations, talking to files/databases, and so on. Bolts receive the data from a spout for processing, which may further emit tuples to another bolt in case of complex stream transformations. The main method in a bolt is execute(), which accepts a tuple as input. In both the spout and bolt, to emit the tuple to more than one stream, the streams can be declared and specified in declareStream().
Stream Groupings:
A stream grouping defines how a stream should be partitioned among the bolt's tasks. There are built-in stream groupings provided by Storm: shuffle grouping, fields grouping, all grouping, one grouping, direct grouping, and local/shuffle grouping. Custom implementation by using the CustomStreamGroupinginterface can also be added.
Implementation
For our use case, we designed one topology of spout and bolt that can process a huge amount of data (log files) designed to trigger an alarm when a specific value crosses a predefined threshold. Using a Storm topology, the log file is read line by line and the topology is designed to monitor the incoming data. In terms of Storm components, the spout reads the incoming data. It not only reads the data from existing files, but it also monitors for new files. As soon as a file is modified, spout reads this new entry and, after converting it to tuples (a format that can be read by a bolt), emits the tuples to the bolt to perform threshold analysis, which finds any record that has exceeded the threshold.
The next section explains the use case in detail.
Threshold Analysis
In this article, we will be mainly concentrating on two types of threshold analysis: instant threshold and time series threshold.
- Instant threshold checks if the value of a field has exceeded the threshold value at that instant and raises a trigger if the condition is satisfied. For example, raise a trigger if the speed of a vehicle exceeds 80 km/h.
- Time series threshold checks if the value of a field has exceeded the threshold value for a given time window and raises a trigger if the same is satisfied. For example, raise a trigger if the speed of a vehicle exceeds 80 km/h more than once in last five minutes.
Listing One shows a log file of the type we'll use, which contains vehicle data information such as vehicle number, speed at which the vehicle is traveling, and location in which the information is captured.
Listing One: A log file with entries of vehicles passing through the checkpoint.
AB 123, 60, North city
BC 123, 70, South city
CD 234, 40, South city
DE 123, 40, East city
EF 123, 90, South city
GH 123, 50, West city
A corresponding XML file is created, which consists of the schema for the incoming data. It is used for parsing the log file. The schema XML and its corresponding description are shown in the table.
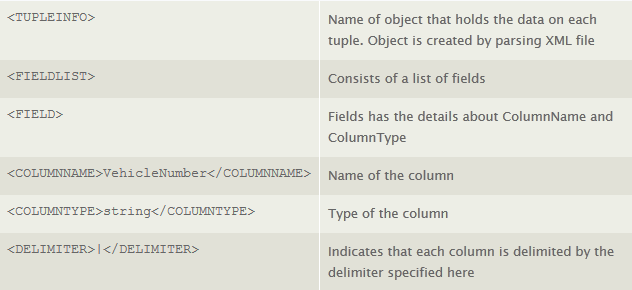
The XML file and the log file are in a directory that is monitored by the spout constantly for real-time changes. The topology we use for this example is shown in Figure 1.
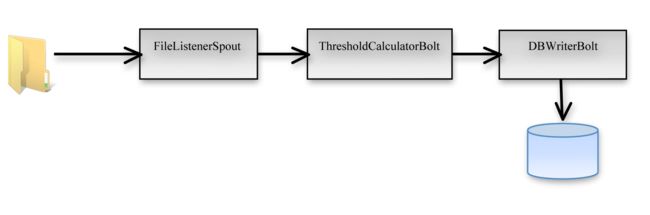
Figure 1: Topology created in Storm to process real-time data.
As shown in Figure 1, the FileListenerSpout accepts the input log file, reads the data line by line, and emits the datea to the ThresoldCalculatorBolt for further threshold processing. Once the processing is done, the contents of the line for which the threshold is calculated is emitted to the DBWriterBolt, where it is persisted in the database (or an alert is raised). The detailed implementation for this process is explained next.
Spout Implementation
Spout takes a log file and the XML descriptor file as the input. The XML file consists of the schema corresponding to the log file. Let us consider an example log file, which has vehicle data information such as vehicle number, speed at which the vehicle is travelling, and location in which the information is captured. (See Figure 2.)

Figure 2: Flow of data from log files to Spout.
Listing Two shows the specific XML file for a tuple, which specifies the fields and the delimiter separating the fields in a log file. Both the XML file and the data are kept in a directory whose path is specified in the spout.
Listing Two: An XML file created for describing the log file.
<TUPLEINFO>
<FIELDLIST>
<FIELD>
<COLUMNNAME>vehicle_number</COLUMNNAME>
<COLUMNTYPE>string</COLUMNTYPE>
</FIELD>
<FIELD>
<COLUMNNAME>speed</COLUMNNAME>
<COLUMNTYPE>int</COLUMNTYPE>
</FIELD>
<FIELD>
<COLUMNNAME>location</COLUMNNAME>
<COLUMNTYPE>string</COLUMNTYPE>
</FIELD>
</FIELDLIST>
<DELIMITER>,</DELIMITER>
</TUPLEINFO>
An instance of Spout is initialized with constructor parameters of Directory, Path, and TupleInfoobject. The TupleInfo object stores necessary information related to log file such as fields, delimiter, and type of field. This object is created by serializing the XML file using XStream.
Spout implementation steps are:
- Listen to changes on individual log files. Monitor the directory for the addition of new log files.
- Convert rows read by the spout to tuples after declaring fields for them.
- Declare the grouping between spout and bolt, deciding the way in which tuples are given to bolt.
The code for Spout is shown in Listing Three.
Listing Three: Logic in Open, nextTuple, and declareOutputFields methods of Spout.
public void open( Map conf, TopologyContext context,SpoutOutputCollector collector )
{
_collector = collector;
try
{
fileReader = new BufferedReader(new FileReader(new File(file)));
}
catch (FileNotFoundException e)
{
System.exit(1);
}
}
public void nextTuple()
{
protected void ListenFile(File file)
{
Utils.sleep(2000);
RandomAccessFile access = null;
String line = null;
try
{
while ((line = access.readLine()) != null)
{
if (line !=null)
{
String[] fields=null;
if (tupleInfo.getDelimiter().equals("|"))
fields = line.split("\\"+tupleInfo.getDelimiter());
else fields = line.split(tupleInfo.getDelimiter());
if (tupleInfo.getFieldList().size() == fields.length)
_collector.emit(new Values(fields));
}
}
}
catch (IOException ex) { }
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
String[] fieldsArr = new String [tupleInfo.getFieldList().size()];
for(int i=0; i<tupleInfo.getFieldList().size(); i++)
{
fieldsArr[i] = tupleInfo.getFieldList().get(i).getColumnName();
}
declarer.declare(new Fields(fieldsArr));
}
declareOutputFields() decides the format in which the tuple is emitted, so that the bolt can decode the tuple in a similar fashion. Spout keeps on listening to the data added to the log file and as soon as data is added, it reads and emits the data to the bolt for processing.
Bolt Implementation
The output of Spout is given to Bolt for further processing. The topology we have considered for our use case consists of two bolts as shown in Figure 3.

Figure 3: Flow of data from Spout to Bolt.
ThresholdCalculatorBolt
The tuples emitted by spout is received by the ThresholdCalculatorBolt for threshold processing. It accepts several of inputs for threshold check. The inputs it accepts are:
- Threshold value to check
- Threshold column number to check
- Threshold column data type
- Threshold check operator
- Threshold frequency of occurrence
- Threshold time window
A class, shown Listing Four, is defined to hold these values.
Listing Four: ThresholdInfo class.
public class ThresholdInfo implements Serializable
{
private String action;
private String rule;
private Object thresholdValue;
private int thresholdColNumber;
private Integer timeWindow;
private int frequencyOfOccurence;
}
Based on the values provided in fields, the threshold check is made in the execute() method as shown in Listing Five. The code mostly consists of parsing and checking the incoming values.
Listing Five: Code for threshold check.
public void execute(Tuple tuple, BasicOutputCollector collector)
{
if(tuple!=null)
{
List<Object> inputTupleList = (List<Object>) tuple.getValues();
int thresholdColNum = thresholdInfo.getThresholdColNumber();
Object thresholdValue = thresholdInfo.getThresholdValue();
String thresholdDataType =
tupleInfo.getFieldList().get(thresholdColNum-1).getColumnType();
Integer timeWindow = thresholdInfo.getTimeWindow();
int frequency = thresholdInfo.getFrequencyOfOccurence();
if(thresholdDataType.equalsIgnoreCase("string"))
{
String valueToCheck = inputTupleList.get(thresholdColNum-1).toString();
String frequencyChkOp = thresholdInfo.getAction();
if(timeWindow!=null)
{
long curTime = System.currentTimeMillis();
long diffInMinutes = (curTime-startTime)/(1000);
if(diffInMinutes>=timeWindow)
{
if(frequencyChkOp.equals("=="))
{
if(valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else if(frequencyChkOp.equals("!="))
{
if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else
System.out.println("Operator not supported");
}
}
else
{
if(frequencyChkOp.equals("=="))
{
if(valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else if(frequencyChkOp.equals("!="))
{
if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
}
}
else if(thresholdDataType.equalsIgnoreCase("int") ||
thresholdDataType.equalsIgnoreCase("double") ||
thresholdDataType.equalsIgnoreCase("float") ||
thresholdDataType.equalsIgnoreCase("long") ||
thresholdDataType.equalsIgnoreCase("short"))
{
String frequencyChkOp = thresholdInfo.getAction();
if(timeWindow!=null)
{
long valueToCheck =
Long.parseLong(inputTupleList.get(thresholdColNum-1).toString());
long curTime = System.currentTimeMillis();
long diffInMinutes = (curTime-startTime)/(1000);
System.out.println("Difference in minutes="+diffInMinutes);
if(diffInMinutes>=timeWindow)
{
if(frequencyChkOp.equals("<"))
{
if(valueToCheck < Double.parseDouble(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else if(frequencyChkOp.equals(">"))
{
if(valueToCheck > Double.parseDouble(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else if(frequencyChkOp.equals("=="))
{
if(valueToCheck == Double.parseDouble(thresholdValue.toString()))
{
count.incrementAndGet();
if(count.get() > frequency)
splitAndEmit(inputTupleList,collector);
}
}
else if(frequencyChkOp.equals("!="))
{
. . .
}
}
}
else
splitAndEmit(null,collector);
}
else
{
System.err.println("Emitting null in bolt");
splitAndEmit(null,collector);
}
}
The tuples emitted by the threshold bolt are passed to the next corresponding bolt, which is theDBWriterBolt bolt in our case.
DBWriterBolt
The processed tuple has to be persisted for raising a trigger or for further use. DBWriterBolt does the job of persisting the tuples into the database. The creation of a table is done in prepare(), which is the first method invoked by the topology. Code for this method is given in Listing Six.
Listing Six: Code for creation of tables.
public void prepare( Map StormConf, TopologyContext context )
{
try
{
Class.forName(dbClass);
}
catch (ClassNotFoundException e)
{
System.out.println("Driver not found");
e.printStackTrace();
}
try
{
connection driverManager.getConnection(
"jdbc:mysql://"+databaseIP+":"+databasePort+"/"+databaseName, userName, pwd);
connection.prepareStatement("DROP TABLE IF EXISTS "+tableName).execute();
StringBuilder createQuery = new StringBuilder(
"CREATE TABLE IF NOT EXISTS "+tableName+"(");
for(Field fields : tupleInfo.getFieldList())
{
if(fields.getColumnType().equalsIgnoreCase("String"))
createQuery.append(fields.getColumnName()+" VARCHAR(500),");
else
createQuery.append(fields.getColumnName()+" "+fields.getColumnType()+",");
}
createQuery.append("thresholdTimeStamp timestamp)");
connection.prepareStatement(createQuery.toString()).execute();
// Insert Query
StringBuilder insertQuery = new StringBuilder("INSERT INTO "+tableName+"(");
String tempCreateQuery = new String();
for(Field fields : tupleInfo.getFieldList())
{
insertQuery.append(fields.getColumnName()+",");
}
insertQuery.append("thresholdTimeStamp").append(") values (");
for(Field fields : tupleInfo.getFieldList())
{
insertQuery.append("?,");
}
insertQuery.append("?)");
prepStatement = connection.prepareStatement(insertQuery.toString());
}
catch (SQLException e)
{
e.printStackTrace();
}
}
Insertion of data is done in batches. The logic for insertion is provided in execute() as shown in Listing Seven, and consists mostly of parsing the variety of different possible input types.
Listing Seven: Code for insertion of data.
public void execute(Tuple tuple, BasicOutputCollector collector)
{
batchExecuted=false;
if(tuple!=null)
{
List<Object> inputTupleList = (List<Object>) tuple.getValues();
int dbIndex=0;
for(int i=0;i<tupleInfo.getFieldList().size();i++)
{
Field field = tupleInfo.getFieldList().get(i);
try {
dbIndex = i+1;
if(field.getColumnType().equalsIgnoreCase("String"))
prepStatement.setString(dbIndex, inputTupleList.get(i).toString());
else if(field.getColumnType().equalsIgnoreCase("int"))
prepStatement.setInt(dbIndex,
Integer.parseInt(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("long"))
prepStatement.setLong(dbIndex,
Long.parseLong(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("float"))
prepStatement.setFloat(dbIndex,
Float.parseFloat(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("double"))
prepStatement.setDouble(dbIndex,
Double.parseDouble(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("short"))
prepStatement.setShort(dbIndex,
Short.parseShort(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("boolean"))
prepStatement.setBoolean(dbIndex,
Boolean.parseBoolean(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("byte"))
prepStatement.setByte(dbIndex,
Byte.parseByte(inputTupleList.get(i).toString()));
else if(field.getColumnType().equalsIgnoreCase("Date"))
{
Date dateToAdd=null;
if (!(inputTupleList.get(i) instanceof Date))
{
DateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
try
{
dateToAdd = df.parse(inputTupleList.get(i).toString());
}
catch (ParseException e)
{
System.err.println("Data type not valid");
}
}
else
{
dateToAdd = (Date)inputTupleList.get(i);
java.sql.Date sqlDate = new java.sql.Date(dateToAdd.getTime());
prepStatement.setDate(dbIndex, sqlDate);
}
}
catch (SQLException e)
{
e.printStackTrace();
}
}
Date now = new Date();
try
{
prepStatement.setTimestamp(dbIndex+1, new java.sql.Timestamp(now.getTime()));
prepStatement.addBatch();
counter.incrementAndGet();
if (counter.get()== batchSize)
executeBatch();
}
catch (SQLException e1)
{
e1.printStackTrace();
}
}
else
{
long curTime = System.currentTimeMillis();
long diffInSeconds = (curTime-startTime)/(60*1000);
if(counter.get()<batchSize && diffInSeconds>batchTimeWindowInSeconds)
{
try {
executeBatch();
startTime = System.currentTimeMillis();
}
catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public void executeBatch() throws SQLException
{
batchExecuted=true;
prepStatement.executeBatch();
counter = new AtomicInteger(0);
}
Once the spout and bolt are ready to be executed, a topology is built by the topology builder to execute it. The next section explains the execution steps.
Running and Testing the Topology in a Local Cluster
- Define the topology using
TopologyBuilder, which exposes the Java API for specifying a topology for Storm to execute. - Using Storm Submitter, we submit the topology to the cluster. It takes name of the topology, configuration, and topology as input.
- Submit the topology.
Listing Eight: Building and executing a topology.
public class StormMain
{
public static void main(String[] args) throws AlreadyAliveException,
InvalidTopologyException,
InterruptedException
{
ParallelFileSpout parallelFileSpout = new ParallelFileSpout();
ThresholdBolt thresholdBolt = new ThresholdBolt();
DBWriterBolt dbWriterBolt = new DBWriterBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", parallelFileSpout, 1);
builder.setBolt("thresholdBolt", thresholdBolt,1).shuffleGrouping("spout");
builder.setBolt("dbWriterBolt",dbWriterBolt,1).shuffleGrouping("thresholdBolt");
if(this.argsMain!=null && this.argsMain.length > 0)
{
conf.setNumWorkers(1);
StormSubmitter.submitTopology(
this.argsMain[0], conf, builder.createTopology());
}
else
{
Config conf = new Config();
conf.setDebug(true);
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(
"Threshold_Test", conf, builder.createTopology());
}
}
}
After building the topology, it is submitted to local cluster. Once the topology is submitted, it runs until it is explicitly killed or the cluster is shut down without requiring any modifications. This is another big advantage of Storm.
This comparatively simple example shows the ease with which it's possible to set up and use Storm once you understand the basic concepts of topology, spout, and bolt. The code is straightforward and both scalability and speed are provided by Storm. So, if you're looking to handle big data and don't want to traverse the Hadoop universe, you might well find that using Storm is a simple and elegant solution.
Shruthi Kumar works as a technology analyst and Siddharth Patankar is a software engineer with the Cloud Center of Excellence at Infosys Labs.