集合
The preceding chapter discussed the list, Lisp's most versatile data structure.arrays (including vectors and strings), structures, and hash tables. They may not be as flexible as lists, but they can make access faster, and take up less space.
common lisp中其他数据类型基本分为两类:
整数索引的数组类型:数组(array),列表(list),元组(tuple)
将或多或少的关键字映射到值上的表类型:哈希表(hash table),关联数组(associative array),映射表(map),字典(dictionary)
1:向量
1:一块数据头以及一段保存向量元素的连续内存区域。--数组
2:抽象了实际存储,允许向量随着元素的增加和移除而增大和减小
1:定义向量,并且赋给默认值
2:make-array同样可以定义变长向量,需要指定一个填充指针fill-pointer相当于iterator,它是当为向量添加一个元素时下一个被填充位置的索引。如果:fill-pointer为为0,表示是一个空向量,如果现在有3个元素那么他的值就是4了。
3:有了填充指针以后你就可以使用vector-push 和vector-pop。
4:如果仅有填充指针的话,向量*x*只能最多保存5个元素;这个时候你还需要传递一个关键字参数:adjustable。
5:尽管经常一起使用,:fill-pointer和:adjustable是无关的,你可以生成一个不带填充指针的可调整数组,但是只能在带填充指针的向量上使用vector-push 和vector-pop。在既带填充指针又可调的数组上使用vector-push-extend.
CL-USER> (make-array 5 :initial-element nil) #(NIL NIL NIL NIL NIL) CL-USER> (make-array 5 :fill-pointer 0) #() CL-USER> (defparameter *x* (make-array 5 :fill-pointer 0)) *X* CL-USER> (vector-push 'a *x*) 0 CL-USER> (vector-push 'b *x*) 1 CL-USER> (vector-pop *x*) B CL-USER> (make-array 5 :fill-pointer 0 :adjustable t) #() CL-USER> (defparameter *x* (vector 1 2 3)) *X*:
A one-dimensional array is also called a vector. You can create and fill one in a single step by calling vector,
CL-USER> (setf vec (make-array 4 :initial-element nil )) #(NIL NIL NIL NIL) CL-USER> (vector 1 3 4) #(1 3 4)
2:多维数组
in syntax #nA, n is the number of dimensions of the array
CL-USER> (setf arr (make-array '(2 3) :initial-element nil )) #2A((NIL NIL NIL) (NIL NIL NIL)) CL-USER> (aref arr 0 0) NIL CL-USER> (setf (aref arr 0 0) 'b) B CL-USER> (aref arr 0 0) B
参数*print-array*决定了array的输出形式。
CL-USER> (setf *print-array* nil) NIL
CL-USER> arr #<(SIMPLE-ARRAY T (2 3)) {26C1CD17}>
CL-USER> (setf *print-array* t) T
CL-USER> arr #2A((B NIL NIL) (NIL NIL NIL))
3
:序列函数库In Common Lisp the type sequence includes both lists and vectors (and therefore strings). Some of the functions that we have been using on lists are actually sequence functions, including remove, length, subseq, reverse, sort, every, and some.
nth for lists
aref and svref for vectors
Svref faster function called svref for use with vectors."sv" in the name stands for "simple vector,"A simple array is one that is neither adjustable, nor displaced, nor has a fill-pointer. Arraysare simple by default.
char for strings.Common
elt that works for sequences of any kind.
LENGTH 返回一个序列的长度,接受序列作为唯一参数。如果含有填充指针那么就是填充指针的值。
ELT element的缩写,接受序列和下标整数。同时接受setf进行值的设置。
CL-USER> (defparameter *x* (vector 1 2 3)) *X* CL-USER> (length *x*) 3 CL-USER> (elt *x* 2) 3 CL-USER> (setf (elt *x* 2) 0) 0 CL-USER> *x* #(1 2 0) CL-USER> (nth 2 '(2 4 5 6)) 5 CL-USER> (elt #(1 3 4) 1) 3 CL-USER> (char "abc" 1) #\b
4:序列迭代函数
字符串的话想对于字符而言是一个集合。所以remove一个字符从string里面
这几个函数都含有关键字:test并且默认值为EQL,他可以用于判断数字或字符,但是如果是string的话,必须是同一个对象才能够成立,所以如果想实现字符串中字符一样就为真,需要重新赋值给:test.

上面也体现出来了为啥叫序列迭代函数,因为它会跟序列中的每个元素进行比较。
CL-USER> (count 23 '(23 33 45 33 23)) 2
CL-USER> (count "me" '("me" "he" "hello")) 0
CL-USER> (count "me" '("me" "he" "hello") :test #'string=) 1
CL-USER> (find 23 '(23 33 45 33 23)) 23
CL-USER> (find 2 '(23 33 45 33 23)) NIL
CL-USER> (find "me" '("me" "he" "hello")) NIL
CL-USER> (position 33 '(23 33 45 33 23)) 1
CL-USER> (remove 23 #(23 33 45 33 23)) #(33 45 33)
CL-USER> (remove 23 '(23 33 45 33 23)) (33 45 33)
CL-USER> (remove #\a "football") "footbll"
CL-USER> (substitute 1 23 '(23 33 45 33 23)) (1 33 45 33 1)
Many sequence functions take one or more keyword arguments from the standard set listed in this table.
:test argument can be any function of two arguments.
注意的就是 :key 因为他是一个单参数函数对象。序列可以最为一个实参传递过去,同样 list/vector 都行,所以当一个序列式列表的集合的时候,通常可以用 :key 关键字调入 first 函数。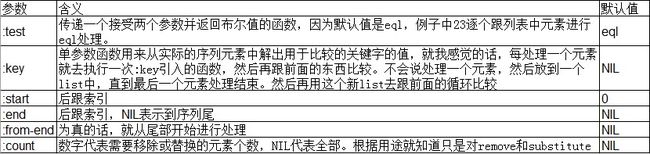
下面的例子正好佐证,它是每个元素调用一次frist-1然后判断,继而处理下一个元素。同时序列中的元素作为一个实参传递给了x。
CL-USER> (defun first-1(x)(format t "looking at ~s~%" x)(first x)) FIRST-1 CL-USER> (find 'a '((a 10)(b 20)) :key #'first-1) looking at (A 10) (A 10) CL-USER> (position 3 ' ( 1 0 7 5 ) :test #'<) 25:高阶函数
总共有两种形式变体,像上面只有一个:key引入谓词还不够,现
一组为:与基本函数名相同并追加-if。另一组是追加-if-not. 很显然其后应该跟着返回值是布尔类型的函数对象。其实无论怎么变你只要清楚他是循环进行处理并且每个元素处理时候都会最为实参传进来就行了。
CL-USER> (count-if #'evenp #(1 2 3 4))
2
CL-USER> (remove-if-not #'(lambda (x)(char= (elt x 0) #\f))
#("foo" "bar" "foom"))
#("foo" "foom")
CL-USER> (remove-if-not #'alpha-char-p
#("foo" "bar" "1baz")
:key #'(lambda (x)(elt x 0)))
#("foo" "bar")
Remove-Duplicates:仅需要序列然后去掉重复的元素。与remove相比他没有:count,因为他都没有重复的元素,你还传给他替换或者去掉的个数干啥。
CL-USER> (remove-duplicates #(1 2 3 1 2 4 5)) #(3 1 2 4 5)
6:整个序列上的操作
Copy-seq / Reverse 后跟序列
Concatenate 返回将任意数量序列连接在一起的新序列。因为序列包含3中类型,所以你得指明到底要什么类型的值。
CL-USER> *a* (1 2 3) CL-USER> (copy-seq *a*) (1 2 3) CL-USER> *a* (1 2 3) CL-USER> (reverse *a*) (3 2 1) CL-USER> *a* (1 2 3) CL-USER> (concatenate 'vector #(2 1) "string") #(2 1 #\s #\t #\r #\i #\n #\g) CL-USER> (concatenate 'list '(1 2 3) "string") (1 2 3 #\s #\t #\r #\i #\n #\g) CL-USER> (concatenate 'string "string" '(1 2) #(13 34)) ; No value CL-USER> (concatenate 'string "string" '(#\t #\r)) "stringtr"
7:排序和合并
合并:sort/stable-sort他们都是破坏性函数。
Merge 接受两个序列和一个谓词,并且按照这个谓词合并这两个序列。由下面的实例对于排序的话,都是循环式的进行比较直到顺序排好,跟我们前面的迭代函数一样,所以这3个函数也都有:key关键字,可进行一些预处理
CL-USER> (defvar *test* #("foo" "bar" "baz")) *TEST*
CL-USER> (sort #("foo" "bar" "baz" "bar") #'string<) #("bar" "bar" "baz" "foo")
CL-USER> (stable-sort #("foo" "bar" "baz" "bar") #'string<) #("bar" "bar" "baz" "foo")
CL-USER> (sort *test* #'string<) #("bar" "baz" "foo")
CL-USER> *test* #("bar" "baz" "foo")
CL-USER> (merge 'vector #(1 3 5) #(2 4 6) #'<) #(1 2 3 4 5 6)
8:子序列操作
Subseq与elt的区别是前面是取出子串,并且可以进行与setf结合进行子串的替换,肯定有的情况就是新值太长或者太短。这个时候要按新串与老串中短的那个。
CL-USER> (subseq "football" 3 6) "tba" CL-USER> (defvar *x* "football") *X* CL-USER> (setf (subseq *x* 3 6) "xxx") "xxx" CL-USER> *x* "fooxxxll" CL-USER> (setf (subseq *x* 3 6) "abcd") "abcd" CL-USER> *x* "fooabcll" CL-USER> (setf (subseq *x* 3 6) "xx") "xx" CL-USER> *x* "fooxxcll"
search-查找子串,与查找项的函数position相比,需要接受一个序列。Position可以返回序列中某项的序列,当这个序列为string时,项的话必须为一个字符,比如下面如果项是"am"的话,若后面是string,始终都为NIL,除非让他成为一个序列中的元素,因为当进行循环匹配的时候,是拿序列中的一个单元一个单元的进行循环处理的。
CL-USER> (position "ab" '("ab" "dd" "bb") :test #'string=) 0
CL-USER> (position #\a "family") 1
CL-USER> (position "am" "family" :test #'string=) NIL
CL-USER> (position "ab" '("ab" "dd" "bb") :test #'string=) 0
CL-USER> (position "ab" '("ab" "dd" "bb") :test #'string=) 0
Mismatch 用于找出两个序列中首次分叉的位置,如果序列一样的话返回NIL。跟前面说的单独的非string=函数部分功能一样,其他标准的函数如string>,先到分叉位置,如果分叉位置的元素之间的关系仍旧符合谓词,那么就索引,这个时候就跟mismatch一样了,但是如果关系不符合就返回了NIL.支持那5种关键字。
CL-USER> (mismatch '("am" "me" "he") '("am" "he")) 0
CL-USER> (mismatch '("am" "me" "he") '("am" "he") :test #'string=) 1
CL-USER> (string< "family" "lisp") 0
CL-USER> (string< "lisp" "family") NIL
9:序列谓词
Every :每一个都为真时返回真。
Some :只要有真的就返回真
Notany :not any more. 每一个都为假返回真,与every相对。
Notevery :只要有假的就返回真。与some相对
下面的例子说明,并不是说相对的话,他们最后的结果就是相反 的呀。
CL-USER> (every #'> #(1 2 3 4) #(5 4 3 2)) NIL CL-USER> (some #'> #(1 2 3 4) #(5 4 3 2)) T CL-USER> (notany #'> #(1 2 3 4) #(5 4 3 2)) NIL CL-USER> (notevery #'> #(1 2 3 4) #(5 4 3 2)) T
下面的例子佐证了,当多个序列时它仍旧是每一次取出一个单元然后判断谓词,波浪式向前。并且进行判断的次数是按最短的那个序列中的元素而定的
CL-USER> (every #'< '(1 2 3) '(4 5 6) '(5 6)) T CL-USER> (every #'< '(1 2 3) '(4 5) '(5 6 2)) T CL-USER> (every #'< '(1 2 3) '(6 5) '(5 6 2)) NIL
10:序列映射函数
因为映射就是函数,比如我们所说的x到y,就是通过一个映射实现而推出了数学上像与原像的概念。现在是一个序列为变量x,所以说最后经过映射出来也是一个序列y.
比如上面的序列谓词就是从多个序列中都每次取出来一个单元,进行前面的谓词判断,直到结束,始终也是一个循环外加终止条件的模式。Map跟他们差不多,后面是可以接受n个实参的函数和n个序列,明显前后两个n是一样的,因为序列就是他的实参。最后Map会返回一个序列,因为序列有几种形式,所以说你就要指定你想要什么序列了。注意是一个序列。并且返回的结果的序列长度以最短的那个序列中的个数为标准。
如果你想指定返回序列放到的位置用map-into
CL-USER> (map 'list #'+ '(1 2 3) #(4 5 6)) (5 7 9) CL-USER> (map 'list #'< '(1 2 3) #(4 5 6)) (T T T) CL-USER> (defvar *a* #(6 6 7 8 9)) *A* CL-USER> (map-into *a* #'+ '(1 2 3) '(4 5)) #(5 7 7 8 9) CL-USER> (map-into 'a #'+ '(1 2 3) '(3 4)) ; No value 'a not a sequence CL-USER> (map-into a #'+ '(1 2 3) '(3 4)) a is unbound
Reduce 映射到单个序列上,先将两个参数的函数应用到序列的最初两个元素上,再将返回值和序列后续元素继续用于该函数。注意一定要是能够接受两个参数的函数,并且函数后面只能跟一个序列。字面上说reduce就是减少的意思, +在这里实现的功能就好比sum=+ a.
Reduce同样接受关键字,可以再slime环境的命令buffer中看到。
CL-USER> (reduce #'+ '(1 2 3 4)) 10 CL-USER> (reduce #'+ '(1 2 3 4) '(4 5 6)) ; No value