Python源码学习九,dfa state的初始化
in graminit.c定义了一些struct, 是理解和实现DFA的关键
static dfa dfas[81] = {
{256, //d_type
"single_input", //char *d_name
0, //d_initial
3, //d_nstates
states_0, //state *d_state
"\004\050\060\200\000\000\000\240\340\223\160\220\045\200\020\000\000\206\120\076\204" //bitset d_first =>char* d_first
},
.....
}
typedef struct {
int d_type; /* Non-terminal this represents */
char *d_name; /* For printing */
int d_initial; /* Initial state */
int d_nstates;
state *d_state; /* Array of states */
bitset d_first;
} dfa;
typedef struct {
int s_narcs;
arc *s_arc; /* Array of arcs */
/* Optional accelerators */
int s_lower; /* Lowest label index */
int s_upper; /* Highest label index */
int *s_accel; /* Accelerator */
int s_accept; /* Nonzero for accepting state */
} state;
static state states_0[3] = {
{3, arcs_0_0},
{1, arcs_0_1},
{1, arcs_0_2},
};
static arc arcs_0_0[3] = {
{2, 1},
{3, 1},
{4, 2},
};
/* An arc from one state to another */
typedef struct {
short a_lbl; /* Label of this arc */
short a_arrow; /* State where this arc goes to */
} arc;
/* A grammar*/
typedef struct {
int g_ndfas;
dfa *g_dfa; /* Array of DFAs */
labellist g_ll;
int g_start; /* Start symbol of the grammar */
int g_accel; /* Set if accelerators present */
} grammar;
/* A list of labels */
typedef struct {
int ll_nlabels;
label *ll_label;
} labellist;
static label labels[168] = {
{0, "EMPTY"},
...
{49, 0},
{1, "del"},
{326, 0},
{1, "pass"},
{277, 0},
{278, 0},
{279, 0},
{281, 0},
{280, 0},
{1, "break"},
{1, "continue"},
{1, "return"},
{1, "raise"},
{1, "from"},
{283, 0},
{284, 0},
{1, "import"},
....
}
/* A label of an arc */
typedef struct {
int lb_type;
char *lb_str;
} label;
//Parser的核心数据结构
grammar _PyParser_Grammar = {
81, /*int g_ndfas;*/
dfas, /*dfa *g_dfa*/
{168, labels}, /*labellist => (ll_nlabels, label *ll_label) */定义在前面
256 /*int g_start*/
};
python启动的时候
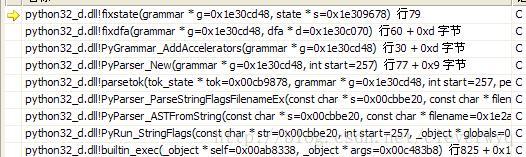
对grammar对象里面的每个dfa object的每个state对象的
int *s_accel; /* Accelerator */ 数组赋值
对第一个dfa object,其定义为
{ 256,
"single_input",
0,
3,
states_0,
"\004\050\060\200\000\000\000\240\340\223\160\220\045\200\020\000\000\206\120\076\204"
}
它有三个state
static state states_0[3] = {
{3, arcs_0_0}, //3 arc
{1, arcs_0_1},
{1, arcs_0_2},
};
static arc arcs_0_0[3] = {
{2, 1}, //{a_lbl, a_arrow} , #a_lbl is Label of this arc, #a_arrow is State where this arc goes to
{3, 1},
{4, 2},
};
static arc arcs_0_1[1] = {
{0, 1},
};
static arc arcs_0_2[1] = {
{2, 1},
};
取第一个state的第一个arc {2,1}的 a_lbl (2 in this case),
得到static label labels[168] 中第a_lbl(2)个label 对象 { 4 /*int lb_type*/, 0/*char *lb_str*/}
lb_type 是 4
和 #define NT_OFFSET 256 比较, 小于 NT_OFFSET, 并且不为0
则 accel[2] = arc->arrow , 也就是 accel[2] = 1
接着
去第二个arc {3,1} , 然后取label 对象labels[3], 即 {269, 0}
而269>= NT_OFFSET,
所以调 dfa *d1 = PyGrammar_FindDFA(g, 269);
该函数是从static dfa dfas[81] 找到第 269 - NT_OFFSET 个 dfa object(No 13 in this case),即
{269, "simple_stmt", 0, 4, states_13,
"\000\040\040\200\000\000\000\240\340\223\160\000\000\200\020\000\000\206\120\076\200"},
/*comments :从这点也可以看出为什么dfas 从256开始编号,依次递增*/
然后对
"\000\040\040\200\000\000\000\240\340\223\160\000\000\200\020\000\000\206\120\076\200"},进行testbit测试,作用见前一篇博客
这里首先得到ibit是13,
于是 accel[13] = arc->a_arrow | (1 << 7) |
((269 - NT_OFFSET) << 8)
= 1101,10000001
/*comments: 从16进制角度看, 逗号前面得代表下标, 后面的代表 arrow */
继续testbit测试,
接着得到ibit是21, accel[21] = 1101,10000001
ibit 31, 61,63,69, 70,71....
测试完毕后
取第三个arc
(此处作者略去1000字)
最后
while (nl > 0 && accel[nl-1] == -1)
nl--;
for (k = 0; k < nl && accel[k] == -1;)
k++;
找出first and last 不为-1 的下标 k, nl
最后得到该state的
s->s_lower = k;
s->s_upper = nl;
for (i = 0; k < nl; i++, k++)
s->s_accel[i] = accel[k];
把accel[] 集中付给0开始的 s->s_accel
终于处理完了一个state....