Java开源分词系统IKAnalyzer学习(三) 流程
为了学习的方便,我用如下代码跑一遍业务流程:
源代码:
String t = "一件红色西装"; System.out.println(t); IKSegmentation ikSeg = new IKSegmentation(new StringReader(t) ,true); try { Lexeme l = null; while( (l = ikSeg.next()) != null){ System.out.println(l); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); }
运行过程:
1. 进入IK分词器的构造函数
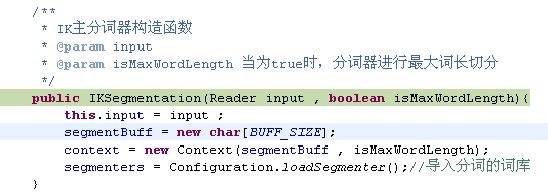
2. 初始化Context

3.segmenters = Configuration.loadSegmenter();
包含两个内容,一是加载词库,二是添加三个分词子系统
3.1 加载词库
Dictionary.getInstance();
3.2 添加三个子分词系统:
public static List<ISegmenter> loadSegmenter(){ //初始化词典单例 Dictionary.getInstance(); List<ISegmenter> segmenters = new ArrayList<ISegmenter>(4); //处理数量词的子分词器 segmenters.add(new QuantifierSegmenter()); //处理字母的子分词器 segmenters.add(new LetterSegmenter()); //处理中文词的子分词器 segmenters.add(new CJKSegmenter()); return segmenters; }
4. 词库加载
5. 子分词器的接口
public interface ISegmenter { /** * 从分析器读取下一个可能分解的词元对象 * @param segmentBuff 文本缓冲 * @param context 分词算法上下文 */ void nextLexeme(char[] segmentBuff , Context context); /** * 重置子分析器状态 */ void reset(); }
5.1 中文分词系统
public class CJKSegmenter implements ISegmenter { /* * 已完成处理的位置 */ private int doneIndex; /* * Hit对列,记录匹配中的Hit对象 */ private List<Hit> hitList; public CJKSegmenter(){ doneIndex = -1; hitList = new ArrayList<Hit>(); } /* (non-Javadoc) * @see org.wltea.analyzer.seg.ISegmenter#nextLexeme(org.wltea.analyzer.Context) */ public void nextLexeme(char[] segmentBuff , Context context) { //读取当前位置的char char input = segmentBuff[context.getCursor()]; if(CharacterHelper.isCJKCharacter(input)){//是(CJK)字符,则进行处理 if(hitList.size() > 0){ //处理词段队列 Hit[] tmpArray = hitList.toArray(new Hit[hitList.size()]); for(Hit hit : tmpArray){ hit = Dictionary.matchInMainDictWithHit(segmentBuff, context.getCursor() , hit); if(hit.isMatch()){//匹配成词 //判断是否有不可识别的词段 if(hit.getBegin() > doneIndex + 1){ //输出并处理从doneIndex+1 到 seg.start - 1之间的未知词段 processUnknown(segmentBuff , context , doneIndex + 1 , hit.getBegin()- 1); } //输出当前的词 Lexeme newLexeme = new Lexeme(context.getBuffOffset() , hit.getBegin() , context.getCursor() - hit.getBegin() + 1 , Lexeme.TYPE_CJK_NORMAL); context.addLexeme(newLexeme); //更新goneIndex,标识已处理 if(doneIndex < context.getCursor()){ doneIndex = context.getCursor(); } if(hit.isPrefix()){//同时也是前缀 }else{ //后面不再可能有匹配了 //移出当前的hit hitList.remove(hit); } }else if(hit.isPrefix()){//前缀,未匹配成词 }else if(hit.isUnmatch()){//不匹配 //移出当前的hit hitList.remove(hit); } } } //处理以input为开始的一个新hit Hit hit = Dictionary.matchInMainDict(segmentBuff, context.getCursor() , 1); if(hit.isMatch()){//匹配成词 //判断是否有不可识别的词段 if(context.getCursor() > doneIndex + 1){ //输出并处理从doneIndex+1 到 context.getCursor()- 1之间的未知 processUnknown(segmentBuff , context , doneIndex + 1 , context.getCursor()- 1); } //输出当前的词 Lexeme newLexeme = new Lexeme(context.getBuffOffset() , context.getCursor() , 1 , Lexeme.TYPE_CJK_NORMAL); context.addLexeme(newLexeme); //更新doneIndex,标识已处理 if(doneIndex < context.getCursor()){ doneIndex = context.getCursor(); } if(hit.isPrefix()){//同时也是前缀 //向词段队列增加新的Hit hitList.add(hit); } }else if(hit.isPrefix()){//前缀,未匹配成词 //向词段队列增加新的Hit hitList.add(hit); }else if(hit.isUnmatch()){//不匹配,当前的input不是词,也不是词前缀,将其视为分割性的字符 if(doneIndex >= context.getCursor()){ //当前不匹配的字符已经被处理过了,不需要再processUnknown return; } //输出从doneIndex到当前字符(含当前字符)之间的未知词 processUnknown(segmentBuff , context , doneIndex + 1 , context.getCursor()); //更新doneIndex,标识已处理 doneIndex = context.getCursor(); } }else {//输入的不是中文(CJK)字符 if(hitList.size() > 0 && doneIndex < context.getCursor() - 1){ for(Hit hit : hitList){ //判断是否有不可识别的词段 if(doneIndex < hit.getEnd()){ //输出并处理从doneIndex+1 到 seg.end之间的未知词段 processUnknown(segmentBuff , context , doneIndex + 1 , hit.getEnd()); } } } //清空词段队列 hitList.clear(); //更新doneIndex,标识已处理 if(doneIndex < context.getCursor()){ doneIndex = context.getCursor(); } } //缓冲区结束临界处理 if(context.getCursor() == context.getAvailable() - 1){ //读取缓冲区结束的最后一个字符 if( hitList.size() > 0 //队列中还有未处理词段 && doneIndex < context.getCursor()){//最后一个字符还未被输出过 for(Hit hit : hitList){ //判断是否有不可识别的词段 if(doneIndex < hit.getEnd() ){ //输出并处理从doneIndex+1 到 seg.end之间的未知词段 processUnknown(segmentBuff , context , doneIndex + 1 , hit.getEnd()); } } } //清空词段队列 hitList.clear();; } //判断是否锁定缓冲区 if(hitList.size() == 0){ context.unlockBuffer(this); }else{ context.lockBuffer(this); } } /** * 处理未知词段 * @param segmentBuff * @param uBegin 起始位置 * @param uEnd 终止位置 */ private void processUnknown(char[] segmentBuff , Context context , int uBegin , int uEnd){ Lexeme newLexeme = null; Hit hit = Dictionary.matchInPrepDict(segmentBuff, uBegin, 1); if(hit.isUnmatch()){//不是副词或介词 if(uBegin > 0){//处理姓氏 hit = Dictionary.matchInSurnameDict(segmentBuff, uBegin - 1 , 1); if(hit.isMatch()){ //输出姓氏 newLexeme = new Lexeme(context.getBuffOffset() , uBegin - 1 , 1 , Lexeme.TYPE_CJK_SN); context.addLexeme(newLexeme); } } } //以单字输出未知词段 for(int i = uBegin ; i <= uEnd ; i++){ newLexeme = new Lexeme(context.getBuffOffset() , i , 1 , Lexeme.TYPE_CJK_UNKNOWN); context.addLexeme(newLexeme); } hit = Dictionary.matchInPrepDict(segmentBuff, uEnd, 1); if(hit.isUnmatch()){//不是副词或介词 int length = 1; while(uEnd < context.getAvailable() - length){//处理后缀词 hit = Dictionary.matchInSuffixDict(segmentBuff, uEnd + 1 , length); if(hit.isMatch()){ //输出后缀 newLexeme = new Lexeme(context.getBuffOffset() , uEnd + 1 , length , Lexeme.TYPE_CJK_SF); context.addLexeme(newLexeme); break; } if(hit.isUnmatch()){ break; } length++; } } } public void reset() { //重置已处理标识 doneIndex = -1; hitList.clear(); } }