基于Davinci达芬奇系列DM6446的AVS-P2基准框架编码器系统框架优化设计
本节详细介绍了基于Davinci达芬奇系列DSP的AVS-P2编码器的系统框架以及从嵌入式系统的实现如何构建系统以尽可能低的复杂度来追求尽可能高的编码质量。主要包含以下部分:1)系统概述;2)编码框架设计;3)考虑L1P Cache对程序流程的设计;4)针对数据Cache的DMA设计。 这些设计主要从编码的主要模块比特流解析、变长解码、反量化和IDCT,运动补偿和环路滤波出发分析数据流,把最主要的数据传输交给DMA,并考虑解码流程来安排指令和数据的次序优化Cache性能,对计算复杂度较高的半像素和四分之一1/4像素插值以及环路滤波部分给出了框架化的优化实现。当然整个系统设计还少不了对帧内和帧间模式RDO判决和码率控制模块的优化。
关键字: Davinci DM6446 AVS-P2 插值 环路滤波 DMA cache SAD SATD SSD C64x+ 性能评估 视频编码
系统概述
本节详细介绍了编码器的设计、验证、调试思路以及系统层的编码器系统框图,然后给出我们的编码器系统的设计策略。
编码器框图设计
AVS-P2标准文档中,并没有对编码的框架做规定,而是仅仅给出码流格式和解码方法,编码器只要设计的符合码流格式,插值滤波系数等合乎标准规范,就是一个正确的编码器。图1-1是通用解码器的一个宏块的解码流程图,首先进行码流解析和语法解析,通过VLD-DeScan-IQ-IDCT得到残差数据,然后通过亮度和色度插值得到预测数据,送到 MC单元进行重建,重建后的数据进行环路滤波。依次循环,直到一帧或者一场的宏块都解码完成。

图1.1 AVS解码流程图
编码过程大致是解码的逆过程,但是如运动预测矢量的获取,帧内/帧间预测模式的抉择都不是标准规定,可以灵活设计。编码器的大致流程如图1.2所示。有两个通路,一个直行通路,把输入的YUV源数据编码输出,即根据参考YUV进行预测,有预测残差的某个函数判决图像内/图像间的预测模式,然后把该模式以及该模式下得到的预测残差进行DCT和反量化,然后经过VLC编码,输出码流;另外一个是环路,是运动预测用到的参考数据的维护,即每次模式判决完成后,需要更新参考数据,无论是图像内还是图像间编码,过程如下:把DCT-Q得到的量化残差系数进行反量化和IDCT,得到残差的重建,该部分和运动预测部分相加得到运动补偿重建,然后环路滤波的重建参考数据用于更新参考图像。
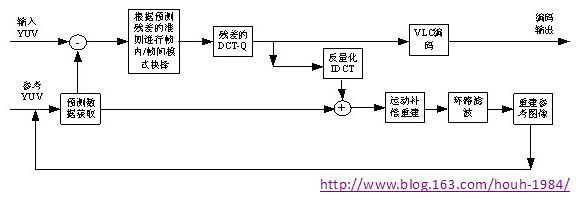
图1.2 AVS编码流程图
这样一个编码器设计的不确定的地方就是帧内、帧间模式的抉择,以及编码器设计所支持的工具集,如对帧间编码,支持几种帧间预测模式,AVS标准中对于P帧给出了5种模式(P_SKIP, P_16x16, P_16x8, P_8x16, P_8x8, P_I8x8),对帧间运动搜索的搜索窗大小、像素精度(整数像素、1/2像素、1/4像素等)的支持,对于帧内编码,支持的帧内预测模式的个数等等。这些工具集的支持带来了编码质量的提升,同时也带来了编码复杂度的提高,在嵌入式平台实现时,必须要考虑编码性能和运算复杂度的折中。
编码工具集
以下是设计编码器需要支持的工具集:
1、支持YUV420Planar和YUV422Interleave两种输入视频源格式;支持采集图像/源文件输入、编码文件/网络输出;
2、支持帧和场编码方式;支持I图像和P图像两种编码模式;
3、支持I图像的全部编码工具,支持亮度和色度的各种帧内预测模式,同时支持帧内预测模式的率失真优化编码工具(可选);
4、P图像编码:支持一个参考图像,支持P图像的宏块编码的全部模式(可选);支持自适应动态整数运动补偿和分数运动补偿,其中分数运动补偿支持1/2像素运动补偿的全部模式和1/4像素运动补偿的全部模式,其中运动补偿部分完全符合标准规定的滤波器系数和相应算法;
5、支持I图像和P图像的环路滤波算法(亮度和色度),完全实现了符合标准规定的滤波器系数和相应算法;
6、支持图像级和宏块级(可选)恒定码率控制(CBR),码率控制基于率失真优化;
- 支持实时的对编码码率、帧率、图像尺寸、I帧间隔等参数的修改;其中图像的宽和高为16的倍数。
编码器的系统验证和调试
DM6446是DaVinci系列的旗舰产品,该处理器有两个内核,一个是ARM内核,一个是C64x+内核,对于双核系统,算法开发验证分成算法的功能验证、server的集成以及ARM应用程序开发几个步骤,验证和调试方法就会有所不同,首先可以利用Emulator进行算法正确性的验证,用simulator进行性能优化仿真,在优化进行一定程度后需要在Linux环境下进行算法的封装,首先是编译成*.a64P的lib,然后server端加入链接信息,集成一个*.x64P的包,在加上ARM端的前后数据处理调用该算法包进行双核测试,功能正确后可以加入DMA传输部分的代码,进行测试。当然DMA传输部分必须在系统框架设计时整理好。
AVS编码器系统框架设计
本部分主要是细化上面的编码器框架,根据嵌入式系统的处理能力设计编码器的参数。
1)模式选择准则
模式选择是以预测残差的某个函数为准则选择模式。下面首先介绍常用的代价函数,包括SAD(累加绝对差)、SATD(累加变换绝对差)、SSD(累加均方绝对差)、rd代价(率失真代价)等。SAD是当前块和参考块的差的绝对值的累加和;SATD是当前块和参考块的差,经过一定的变换之后的绝对值的累加和;SSD是当前块和参考块的差的平方的累加和;rd代价是当前块和使用参考块作为预测的率失真函数,如下式(1-1)所示。
![]() (1-1)
(1-1)
2)帧内模式选择
帧内模式选择在I图像以及P图像的I_8x8块的帧内预测模式中都要使用。AVS标准支持5种亮度预测模式和4种色度预测模式,分别如下表1.1和表1.2所示。每种名称表明了该帧内预测模式的方向,如图1.3所示。

图1.3 8x8亮度块帧内预测模式
帧内预测模式的选取,对于I帧,由于编码复杂度较低,可以采用rd_cost作为判决准则,而对于P帧的I_8x8模式的帧内预测模式的判决,则优先选择sad、或者ssd,同时每种预测模式的编码比特数是不同的,这个在计算每种模式的代价函数时也是需要考虑的,实际采用了![]() 作为代价函数。
作为代价函数。
表1.1 8x8亮度块帧内预测模式
| IntraLumaPredMode |
名称 |
| 0 |
Intra_8x8_Vertical |
| 1 |
Intra_8x8_Horizontal |
| 2 |
Intra_8x8_DC |
| 3 |
Intra_8x8_Down_Left |
| 4 |
Intra_8x8_Down_Right |
表1.2 8x8色度块帧内预测模式
| IntraChromaPredMode |
名称 |
| 0 |
Intra_Chroma_DC |
| 1 |
Intra_Chroma_Horizontal |
| 2 |
Intra_Chroma_Vertical |
| 3 |
Intra_Chroma_Plane |
3)帧间模式选择
帧间模式判决需要判决当前宏块是采用P_SKIP, P_16x16, P_16x8, P_8x16, P_8x8, P_I8x8中的哪一种,对于I_8x8还需要判决是采用哪种预测模式,其判决方式参考前面帧内预测模式选择。帧间模式的判决也采用![]() 作为代价函数,实际更好的可以采用SATD作为判决准则,把残差进行hadmard变换,然后取绝对值,比较该数值进行模式判决,后来的测试结果表明,由于小模式对系统性能的影响有限,在0.4dB之内,对大分辨率的视频,影响更小,所以考虑只使用P_SKIP, P_16x16和P_I8x8三种模式。
作为代价函数,实际更好的可以采用SATD作为判决准则,把残差进行hadmard变换,然后取绝对值,比较该数值进行模式判决,后来的测试结果表明,由于小模式对系统性能的影响有限,在0.4dB之内,对大分辨率的视频,影响更小,所以考虑只使用P_SKIP, P_16x16和P_I8x8三种模式。
帧间模式判决的过程如下:首先进行P_SKIP模式的代价函数计算,即进行P_SKIP的mv预测,在SKIP可用的情况下(预测的mv不超过图像的扩展边界),进行插值,得到SKIP模式下的重建,根据该重建和原始宏块数据计算代价函数,为了提前判决SKIP模式(SKIP模式的计算复杂度最低,每个宏块2500周期内),需要对SKIP模式下的6个块数据的残差进行量化,如果6个块的残差量化都是为零,则不需要进行后面的复杂度较高的P_16x16以及P——I8x8的计算了,为了更好的进行SKIP判决,SKIP块的预量化过程是和码率相关的,当码率较高时,该部分量化比较松,即允许更大的SKIP方式的失真,同时SKIP模式的量化非零块数信息也加入到SKIP方式的代价函数内(![]() 形式的代价函数),这样尽可能的避免出现量化非零块的SKIP模式。
形式的代价函数),这样尽可能的避免出现量化非零块的SKIP模式。

图1.4 帧间预测模式判决
若SKIP方式的残差较大,出现了某一个或者某几个块量化为非零的数据,则进行P_16x16的判决,即首先整数ME,然后插值进行分数ME搜索,注意此时的整数ME和分数ME都是只针对亮度数据,即只使用亮度数据的代价函数进行ME判决,搜索了最佳1/4像素点后,对色度的数据进行插值,然后是亮度和色度数据的rd_cost的计算,计算其残差和量化比特的代价函数,和计算色度的代价函数,亮度和色度的代价之和构成了P_16x16的代价,如果此代价小于SKIP方式的代价,则更新当前块的模式。
对于P_I8x8的判决条件,则更为复杂,分两个部分:1)SKIP的预量化非零块的个数大于1并且SKIP模式的代价大于P_16X16模式的某个倍数(如0.8)并且,2)(P块的量化非零块个数大于某一个码率相关的值(如bpp=0.1时1、0.2时2等)并且P_16X16模式的代价大于SKIP模式的某个倍数(如0.8) ),或者此时最佳模式判决为SKIP并且SKIP模式的代价大于P_16X16模式的某个倍数(如0.8),此时进入P_I8x8的模式判决,进行帧内预测和残差量化,计算rd_cost,然后比较得出最佳模式。经过上面的处理,得到最佳模式之后,还需要进行调整,即如果此时最佳模式仍然是P_SKIP并且SKIP模式的预量化非零块的个数大于1,则判决P_16x16以及P_I8x8中代价小的那种模式为最终模式。图1.4是整个帧间模式判决的流程图。
4.参考窗大小的选取和参考数据调度
由于插值模板完全在片外,所以在片内有一个宏块所使用的插值数据的参考窗。该参考窗大小决定了插值数据调度的复杂度,同时也决定了整数ME的最大搜索范围,考虑到插值需要使用扩展的3x3的区域(即如果进行16x16块的插值,实际需要21*21行的数据),所以整数ME的最大搜索范围为![]() 。
。
从仿真的性能来看,使用48*48的搜索窗能较好的兼顾算法复杂度和编码性能。此时的搜索范围为13,使用旋转菱形搜索方法,可以采用(6,4,2,1)的搜索间距。另外就是参考窗的中心问题,可以采用零零点为参考窗中心,也可以采用mvp对应的整数像素点作为参考窗中心。仿真性能表明使用以mvp为中心的的参考窗,编码性能较好。
表1.3. 参考窗中心和搜索范围性能测试
| 序列 |
mvp(6,3,1) |
mvp(4,2,1) |
Zero(6,3,1) |
Zero(4,2,1) |
mvp(6,4,2,1) |
| foreman |
34.75 |
34.81 |
34.28 |
34.17 |
34.82 |
| footbal |
29.67 |
29.66 |
29.46 |
29.42 |
|
| bus |
28.33 |
27.68 |
28.10 |
27.88 |
28.39 |
| paris |
33.27 |
33.22 |
33.14 |
33.14 |
|
| mobile |
25.93 |
25.96 |
25.93 |
25.92 |
|
| tempete |
29.22 |
29.23 |
29.22 |
29.24 |
|
| news |
40.71 |
40.71 |
40.65 |
40.73 |
|
| mix300x7 |
31.67 |
31.61 |
31.53 |
31.49 |
31.71 |
| substation |
39.33 |
39.33 |
39.34 |
39.33 |
|
| trans_d1 |
40.00 |
39.92 |
39.81 |
39.75 |
程序流程设计
该部分主要考虑L1P的效率问题,由于DM6446的DSP片内的L1p只有32KB,同时还需要考虑到cache占用情况,所以,如果把代码分成32KB的一部分,然后该部分每次都比较频繁的得到调用,则L1P cache的miss会尽可能的小。此时就需要对代码进行归置,让其进入cache后,执行尽可能多的时间,然后再刷出去。即把原来按照宏块进行的解码操作划分成按照宏块行进行。需要解决的就是代码宏块行划分的问题。
宏块行划分主要是让一个宏块行的代码一次频繁执行,提高L1P的命中率。需要注意的是,由于宏块行划分,可能原来只需要保存一个宏块的数据,现在需要保存一个宏块行的数据造成需要的L1D空间增大,即在进行宏块行划分时,必须要考虑L1D和L1P间的平衡。

图1.5 编码宏块行划分
把源和参考数据的获取一直到量化部分以及反量化重建部分的代码都放到一个宏块行内实现,而环路滤波和VLC编码则放到第二个宏块行实现,此时需要增加的是保存需要VLC编码的非零码字的宏块行数据,该部分一部分放在L1d,一部分放在片外,因为实际上该部分码字很少,即残差经过DCT和量化后的非零系数非常少。另外这种按照宏块行划分功能的方法还适用于多片系统,即通过不同的宏块行功能块在不同的片内进行而有效利用多核的资源。
DMA传输设计
DMA主要是为了释放DSP核的负担,做一些存储器间的数据搬移。考虑到L1D的效率问题,由于片内的L1D只有80KB,同时还需要考虑到cache占用情况,所以要考虑用DMA来代替DSP进行数据搬移,减少L1D的stall的同时提高cache的效率(因为DMA的使用,原来需要刷新cache的片外数据操作不用进行cache更新了)。因为原始数据和插值调度数据的频率和数据量较大,需要使用DMA来优化它,减少L1D的stall。为了DMA传输的方便,选择了双缓冲的结构,即片内的原始数据有两个缓冲区,片内的待插值的参考窗数据也是两个缓冲区,一个用于DMA传输,另一个用于计算。
原始编码数据的双缓冲比较简单,即首先初始化DMA的类型,传输大小等参数,加载一个宏块数据,然后在该宏块数据进行编码的同时用DMA加载下一个宏块的编码数据。

图1.6 原始编码数据的DMA传输
对于插值数据的DMA操作则较为复杂一些,因为需要根据编码得到的信息来更新参考窗的中心点位置,即mvp对应的整数像素点,而该点必须等前一个宏块编码模式确定了才能得到,所以为了简便,采用前一个宏块之前的宏块的mv来代替前一个宏块的mv来预测得到当前宏块的mvp',以该mvp'为中心加载参考窗数据。

图1.7 参考窗数据的DMA传输
需要注意的是,宏块行划分之后对代码分布做了整理,然后加入DMA会改变代码的大小,需要合理的分配代码的位置,以减少L1P的stall。
AVS编码器模块设计
1.运动估计
本节主要讲述现在的编码器采用的运动搜索方法,分两步:整数运动估计和分数运动估计。
1.1整数运动估计
整数运动估计的中心点是预测的mvp'点,以该中心进行(6,4,2,1)的大菱形搜索。搜索过程见图2.1所示。首先搜索参考窗中心的间距为6的3*3点,找出最佳匹配点,然后以该点为中心开始搜索间距为4的3*3点,顺序搜索间距为2和1的搜索点。该方法虽然搜索点较多,共33点,但是运算规则且密集,有利于DSP这种架构实现,比那种提前退出条件很多的搜索方法效率高。

图2.1 整数运动估计
在DSP实现中,33个点的最佳点匹配需要大概1000个周期。
1.2分数运动估计
本编码器支持全精度的1/2像素搜索和1/4像素搜索。其中1/2像素搜索是搜索最佳整数点周围的8个1/2像素点,而1/4像素搜索则是搜索最佳1/2像素点和次优1/2像素点间的3个1/4像素点,仿真性能表明该方法和全部搜索1/4像素点差不多,损失很小,在0.01dB左右。其中1/4像素点的坐标由下式决定:
 (2-1)
(2-1)

图2.2 分数运动估计
1.3RDO
RDO需要的是搜索最优的模式(包括帧内和帧间),本编码器中的rd计算方法有以下两种,一种是为了提高主观质量,减少SKIP块个数的SKIP模式的修正RD,一种是其他帧内帧间需要经过DCT-Q-IQ-IDCT重建编码操作的RD计算。下面分别给出SKIP模式和其他模式的RD计算方式:
SKIP模式的RD计算方法:
![]() (2-2)
(2-2)
其中ssd为原始编码图像和SKIP模式插值的重建图像间的差值的平方和,附加的部分是由SKIP模式非零块的某个函数表示的附加编码比特数对应的代价。
其他模式的RD代价函数就是
![]() (2-3)
(2-3)
其中ssd是原始编码图像和经过预测编码得到的重建(即预测加上经过DCT-Q-IQ-IDCT后的残差)间的残差的平方和,bits是残差量化后的编码比特数。
2.插值
插值是帧间预测分数搜索使用的,对于亮度,对所有的1/2和1/4像素点都有对应的插值方法,本质是一个或者一组4抽头滤波器,通过对分数像素周边的整数像素点的滤波完成插值工作。色度分量则是一个双线性插值,也是对周边整数像素点的4抽头滤波。具体的插值过程可以参考标准。本节主要讲述为了节省代码空间,对插值函数的合并。
2.1 色度插值
色度插值由下面公式得出:
![]() (2-4)
(2-4)

图 2-3 宏块色度插值示意图
在这里,做了一个算法层的优化,就是去掉了Clip1的饱和加法运算,因为对于双线性插值而言,可以通过下面的不等式计算出插值结果的最大值:
 (2-5)
(2-5)
64*255+32的值为0x3FE0,右移6位刚好为0xFF,故在中间运算结果是16比特的时候,不必进行Clip1的饱和运算。
2.2 亮度插值

图 2-4 宏块亮度插值示意图
插值过程可以参考标准!本部分主要是把相同的插值过程合并,主要是以下几个1/4像素插值点:
1)、a点和c点以及i点和k点
水平方向的插值相差1/2像素,只是插值系数和插值点做个判断即可。通过一个输入参数来选择插值系数和插值点就能合并上述的插值点的操作,具体可以参考代码;
2)、d点和n点以及f点和q点
垂直方向相差1/2像素,也是设定不同的插值系数和插值整数点即可;
3)、e点、g点、p点和r点
这4个点是1/2像素点j和其周边的整数像素点的平均,所以只需要一个参数选择整数点就能合并这4个点的插值。
3.滤波
滤波操作过程可以参考标准,需要注意的是,本编码器中的参考帧只有一个,宏块模式只有SKIP、P_16x16、以及P_I8x8几种,所以根据边界强度的定义,每个宏块的边界强度只有水平方向的两个和垂直方向的两个,这样可以减少边界强度的求解以及对边界强度的判决来调用滤波函数。另外就是本编码器的RC算法是基于帧的,即一帧数据的量化常数QP是固定,所以不需要对qp的判断求解。
4.码率控制
本编码器中的码率控制选择![]() 阈算法,即假设量化编码的比特数和量化系数中的非零系数的个数是正比关系,
阈算法,即假设量化编码的比特数和量化系数中的非零系数的个数是正比关系,![]() 表示一个序列内的量化为0的系数的个数,那么编码的比特数可以用下式表示:
表示一个序列内的量化为0的系数的个数,那么编码的比特数可以用下式表示:
![]() (2-6)
(2-6)
其中参数![]() 是序列相关的一个参数,可以统计得出。这样在码率设定的情况下,可以得出需要量化为0的系数的比例。对于AVS而言,其非线性量化方式需要给出一个量化参数QP和量化为0时的DCT系数间的关系,该关系可以固化为表格形式。然后统计出dct系数的直方图分布,就能根据量化为0的dct系数的比例得出需要的最小qp值,即实现了qp变化来控制码率。
是序列相关的一个参数,可以统计得出。这样在码率设定的情况下,可以得出需要量化为0的系数的比例。对于AVS而言,其非线性量化方式需要给出一个量化参数QP和量化为0时的DCT系数间的关系,该关系可以固化为表格形式。然后统计出dct系数的直方图分布,就能根据量化为0的dct系数的比例得出需要的最小qp值,即实现了qp变化来控制码率。
除了根据式(2-6)得到qp值之外,还需要对qp进行限幅,即让qp在一定的范围内变化,如保证帧间的qp变化不超过2,qp的值不能超过有效范围等等。
Reference
http://www.blog.163.com/houh-1984/
http://avs.org
www.avs.org.cn/
http://baike.baidu.com/view/56322.htm
http://en.wikipedia.org/wiki/H.264/MPEG-4_AVC
http://en.wikipedia.org/wiki/Texas_Instruments_DaVinci
关键字: Davinci DM6446 AVS-P2 插值 环路滤波 DMA cache SAD SATD SSD C64x+ 性能评估 视频编码
本节详细介绍了基于Davinci达芬奇系列DSP的AVS-P2编码器的系统框架以及从嵌入式系统的实现如何构建系统以尽可能低的复杂度来追求尽可能高的编码质量。主要包含以下部分:1)系统概述;2)编码框架设计;3)考虑L1P Cache对程序流程的设计;4)针对数据Cache的DMA设计。 这些设计主要从编码的主要模块比特流解析、变长解码、反量化和IDCT,运动补偿和环路滤波出发分析数据流,把最主要的数据传输交给DMA,并考虑解码流程来安排指令和数据的次序优化Cache性能,对计算复杂度较高的半像素和四分之一1/4像素插值以及环路滤波部分给出了框架化的优化实现。当然整个系统设计还少不了对帧内和帧间模式RDO判决和码率控制模块的优化。