Oracle FlashBack 简介
简介
Flashback数据库是一种时点(PIT)数据库恢复的方式。这种不完全的恢复策略可以用于恢复由于人为错误导致逻辑损坏的数据库。在10g中引入之后,它的设计目标就是以缩减恢复时间而获得最大的可用性。这篇文章将会探索Flashback数据库,将其与传统的恢复方法相比较,并且演示一下如何配置和执行重现恢复。
传统恢复vs.重现数据库
导致停机的第一个原因就是人为错误导致的逻辑损坏,这一点已经被广泛承认。关于逻辑损坏的例子,从用户不正确的更新数据和截取表,到批处理任务错误运行2次或者打乱顺序,比比皆是。结果都是相同的——数据库损坏,并且范围广阔且难以辨认。Oracle通过了两种策略来将数据库返回到先前的某个时点上:传统恢复和重现数据库。
不完全的恢复是数据库恢复到先前某个状态的恢复。这个过程有两个步骤:重新存储数据,并向前恢复事务活动到某个你想要的时间。传统恢复和重现数据库之间的主要区别就是,传统恢复从重新存储所有的数据文件开始,然后才恢复到某个想要的恢复时间,而重现数据库则是在损坏之后通过重新存储被改变的块来向后操作。从这个角度考虑问题的话,让我们想想在一个10TB的数据库上,有1MB的数据损坏了。传统的恢复从开始重新存储10TB的应用程序数据开始,而重现数据库则是取回这1MB的应用程序数据,从而达到损坏前的那个点。现在我们分别看看每一种策略。
传统恢复
在Oracle 10g之前,将由于人为错误导致问题的数据库恢复到先前某个时点的唯一选项就是传统恢复。这个策略包括了从备份中取出并重新存储所有的数据库数据文件,然后再执行向前恢复到某个想要的时间点。媒体恢复可以基于服务器(RMAN),也可以基于用户(操作系统工具)。
下图演示了这个复杂的、成本高昂的、效率极低的多步骤恢复策略。
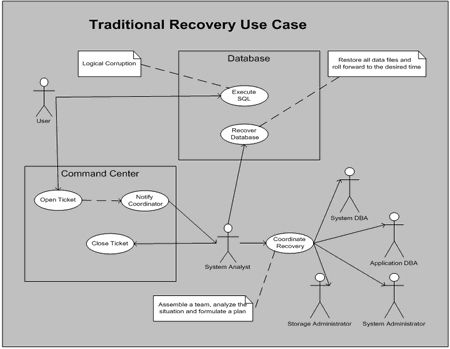
现在我们看一下用户执行了SQL并且损坏了数据库的情况。用户通知了命令中心并且报告了错误。系统分析师通过与公司不同部门的另外一些人协商管理这次事件。恢复通过从备份中重新存储所有的数据文件并且向前回滚redo日志到希望的时间点而完成。恢复时间与数据库的规模成正比,而不是需要恢复的更改的数量。这就意味着恢复时间(MTTR)实际上随着数据库的规模增长而不断增加。
重现数据库
在Oracle 10g中,一项新的重现技术特性,称为Flashback Database(重现数据库)的,作为传统恢复的替代品引入了。重现数据库可以让你快速恢复整个数据库到先前的某个时间点,而不需要从备份中重新存储数据库。在数据库中经常被描述为倒转按钮,它只是将那些被修改的数据块恢复到你希望的恢复时间之前。然后应用Redo更改记录来达到希望的恢复时间点。这个被修改的数据块就叫做重现日志。
重现数据库提供了相对于传统数据库非常明显的优势。对于分析型数据库则没有这么明显的优势。在数据仓库中,块的操作通常是以不记录日志的模式执行的。在重现数据库中,只要数据库运行的是文档日志模式,它就可以返回到块操作之前的某个状态,因为被修改的块可以通过恢复而撤销执行的操作。
注意:虽然重现数据库是集成到数据库中的,但是它在Oracle的 Express Edition (XE)中是不可用的。
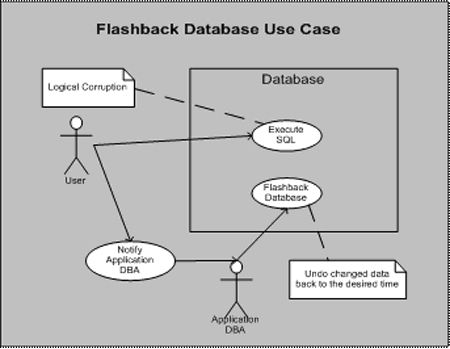
这里我们看一下用户执行了SQL并且损坏了数据库的情况。用户通知了应用程序数据库管理员,他执行了重现数据库命令,数据库自动恢复到损坏之前的某个点。重现数据库很快,使因为它只针对被修改的数据进行操作。重现的时间与犯错误的数量有关,而与数据库的规模无关。
配置重现数据库
以下的例子演示了命令行配置。这也可以用企业管理器来完成。
在我们配置重现数据库之前,我们需要照顾以下一些先决条件。
Flash Recovery Area
首先,我们需要配置一个Flash Recovery Area (FRA)。在10g中,这是个新东西,FRA只不过是一个恢复相关文件的磁盘定位。对于重现数据库,一个新的后台进程,名为Recovery Writer (RVWR),在来自SGA的数据库重现缓存的映像之前,阶段性地写入磁盘,作为FRA中的重现日志。重现日志是在FRA中由Oracle数据库自动管理的。
重现日志的成本是以空间和性能来衡量的。空间是数据库写密度的一个因素。一个24小时运行的,以5%的数据块写入作为重现日志的方式必然会导致磁盘整体空间的5%的增长。因为块是以规律的间隔写入的,而不是事务的一部分,所以对性能的影响是可以忽略不计的。
要配置FRA,你需要设置如下的初始化参数:
alter system set db_recovery_file_dest= 'C:/oracle/product/10.2.0/flash_recovery_area' scope=both; alter system set db_recovery_file_dest_size = 10G scope=both; |
存档
接下来,我们需要配置存档。再一次,我们需要使用FRA作为我们的文档日志目的地。与传统恢复类似,重现数据库需要存档以向前恢复提交的事务,在重现日志重新存储了希望时间之前的时点之后。
要最小化配置存档,执行如下的命令,按照顺序:
SQL> startup mount ORACLE instance started. . . . Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 2 Next log sequence to archive 4 Current log sequence 4 |
重现数据库
配置了这些先决条件之后,我们准备好配置重现数据库了。
首先,我们需要设置重现保持目标。这个初始化参数,以分钟来计算,代表我们可以把数据库返回到多长时间之前。它的值决定了FRA中重现日志的数量和时间段。下面我们的例子将其设置为24小时。要理解这个保持时间段并不是保证是非常重要的。如果FRA需要空间,重现日志将会自动删除目标保持时间点之前的记录。稍后我们会看到,我们保证重现日志的方式在FRA中进行维护。有了保持时间段设置,重现数据库可以激活。
SQL> startup mount; ORACLE instance started. . . . Database mounted. SQL> alter system set db_flashback_retention_target = 1440 scope=both; System altered. SQL> alter database flashback on; Database altered. SQL> alter database open; Database altered. SQL> select flashback_on from v$database; FLASHBACK_ON ------------------ YES |
重现数据库示例
下面的例子用于演示,它想要描述单个表之外的损坏。
45. 监控FRA 46. select name,space_limit,space_used, space_reclaimable from v$recovery_file_dest; 47. 48. NAME SPACE_LIMIT SPACE_USED SPACE_RECLAIMABLE 49. -------------------------------------------- 50. C:/oracle/product/10.2.0/flash_recovery_area 2147483648 166646272 0 51. 52. 53. select * from v$flash_recovery_area_usage; 54. 55. FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES 56. ------------ ------------------ ------------------------- --------------- 57. CONTROLFILE 0 0 0 58. ONLINELOG 0 0 0 59. ARCHIVELOG 7.38 0 29 60. BACKUPPIECE 0 0 0 61. IMAGECOPY 0 0 0 62. FLASHBACKLOG .38 0 1 63. 在表的映像之前显示 64. select c1, ora_rowscn from my_table; 65. 66. C1 ORA_ROWSCN 67. ---------- ---------- 68. 1 1320954 69. 判断数据库的时间点 |
在10gR1中,你有两种选择来捕捉你的数据库的PIT:时间戳和系统修改号码(SCN)。这个信息是作为重现操作的一部分要求的。 捕捉到提交的SCN或者稍后的非常重要,而不是数据管理语言操作。Oracle提供了一种比较笨拙的方式来捕捉提交的SCN,通过userenv('commitscn')函数。我们的示例在发生损坏的数据管理语言操作之前捕捉到了这个信息。
select current_scn from v$database;
CURRENT_SCN
-----------
1321065
or
select to_char(sysdate,'YYYY-MM-DD:HH24:MI:SS')
"Recover Time" from v$database;
Recover Time
-------------------
2006-09-23:20:13:48 |
在10gR2中,Oracle通过重新存储点简化了这个过程。一个重新存储点就是一个用户定义的与数据库PIT相关连的名字,可以在时间戳或者SCN中使用。可以认为重新存储点是一个redo历史的参考标记。重新存储点保留在控制文件中,直到重新存储点被删除或者重现日志被删除。第二个例子保证了重现数据库对于恢复是可用的。
create restore point my_restore_point; Operation 206 succeeded. |
或者创建重新存储点my_restrore_point来保证重现数据库;
注意:重新存储点并不会保证所有的事务都在那个时间点上提交。它不应该与DB2的关系型数据库管理系统中的静默点混淆了。
模拟数据库损坏
70. 模拟数据库损坏 71. insert into my_table values (2); 72. 73. 1 row created. 74. 75. commit; 76. 77. 提交完成 78. 判断数据库是否由于人为错误导致逻辑损坏。 79. select c1, ora_rowscn from my_table; 80. 81. C1 ORA_ROWSCN 82. ---------- ---------- 83. 1 1320954 84. 2 1321231 |
注意:在默认情况下,Oracle在时钟级别上检索SCN。当然,时钟当中的所有行都有一样的SCN。激活行级别的SCN检索,可以在CREATE TABLE命令中使用ROWDEPENDENCIES关键字。
检验重现数据库是可能的。 判断你可以重现的最早的时间。
SELECT OLDEST_FLASHBACK_SCN
,to_char(OLDEST_FLASHBACK_TIME,'YYYY-MM-DD:HH24:MI:SS')
"OLDEST_FLASHBACK_TIME"
FROM V$FLASHBACK_DATABASE_LOG;
OLDEST_FLASHBACK_SCN OLDEST_FLASHBACK_TI
-------------------- -------------------
1319629 2006-09-23:19:51:56 |
判断你是否有重新存储点。
select name, scn, time from v$restore_point; NAME SCN TIME ---------------- ---------- ---------------------------- MY_RESTORE_POINT 1321136 23-SEP-06 08.16.24.000000000 PM |
这里是一些你感兴趣的视图。
重现数据库
你可以在SQL*Plus 或者 RMAN中执行重现数据库。重现数据库可以是基于修改和重新存储点的时间。RMAN提供了额外的基于选项的日志顺序。
使用先前创建的重新存储点来重现数据库。
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. . . . Database mounted. SQL> flashback database to restore point my_restore_point; Flashback complete. |
在警告日志中检查重现数据库消息
. . . Sat Sep 23 20:38:11 2006 flashback database to restore point my_restore_point Sat Sep 23 20:38:12 2006 Flashback Restore Start Flashback Restore Complete Flashback Media Recovery Start parallel recovery started with 2 processes Sat Sep 23 20:38:14 2006 Recovery of Online Redo Log: Thread 1 Group 2 Seq 33 Reading mem 0 Mem# 0 errs 0: C:/ORACLE/PRODUCT/10.2.0/ORADATA/ORCL/REDO02.LOG Sat Sep 23 20:38:16 2006 Incomplete Recovery applied until change 1321137 Flashback Media Recovery Complete Completed: flashback database to restore point my_restore_point |
验证你的数据库恢复到你想要的状态如果你不满意,你可以再次重现,把数据库向前恢复,直到或者执行了完全恢复:recover database.注意:重现数据库可以通过RESETLOGS执行。
SQL> alter database open read only;
Database altered.
SQL> select c1, ora_rowscn from my_table;
C1 ORA_ROWSCN
---------- ----------
1 1321002 |
为一般用途打开数据库
对我们的恢复满意了之后,为了一般用途打开数据库。
SQL> shutdown; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount; ORACLE instance started. . . . Database mounted. SQL> alter database open resetlogs; Database altered. |
结论
重现数据库将会成为我最喜欢的Oracle10g特性之一。无论你是否纠正了用户的错误,只是看看先前的数据库状态,或者在衰退测试之后回到测试环境中,这个特性都是减少恢复时间的最好策略。我们看到这项技术很容易使用,比传统的恢复更快,并且最好的是,它是免费的!我希望你也会认为重现数据库是可用性体系结构中的一项主要组件。