Hadoop0.20.2在Linux X64下的分布式配置和使用
Hadoop0.20.2在Linux X64下的分布式配置和使用
2013年3月
郭运凯
目 录
介绍...2
1 集群网络环境介绍及快速部署...2
2 SSH无密码验证配置...6
2.1配置所有节点之间SSH无密码验证...6
3 JDK安装和Java环境变量配置...10
3.1 安装 JDK 1.6.10
3.2 Java环境变量配置...11
4 Hadoop集群配置...13
5 Hadoop集群启动...17
6 Hadoop使用...22
6.1 客户机与HDFS进行交互...22
6.1.1 客户机配置...22
6.1.2 列出HDFS根目录/下的文件...23
6.1.3 HDFS用户管理...23
6.1.5 复制本地数据到HDFS中...23
6.1.6 数据副本说明...23
6.1.7 hadoop-site.xml参数说明...25
6.1.8 HDFS中的路径...26
6.1.8 Hadoop相关命令...26
6.2 客户机提交作业到集群...26
6.2.1 客户机配置...26
6.2.2 一个测试例子WordCount.27
6.2.3 编写Hadoop应用程序并在集群上运行...31
6.2.4 三种模式下编译运行Hadoop应用程序...31
6.2.5 提交多个作业到集群...33
jie介绍
介绍
这是利用Vmware 9.0在一台服务器上搭建的分布式环境,操作系统CentOS 6.3 X64中配置Hadoop-0.20.2时的总结文档。 Hadoop配置建议所有配置文件中使用主机名进行配置,并且机器上应在防火墙中开启相应端口,并设置SSHD服务为开机启动,此外java环境变量可以在/etc/profile中配置。
1 集群网络环境介绍及快速部署
集群包含五个节点:1个namenode,4个datanode,节点之间局域网连接,可以相互ping通。
所有节点均是Centos 6.3 64位系统,防火墙均禁用,sshd服务均开启并设置为开机启动。
a) 首先在VMware中安装好一台Centos 6.3,创建hadoop用户。假设虚拟机的名字为NameNode
b) 关闭虚拟机,把NameNode文件夹,拷贝4份,并命名为DataNode1,..,DataNode4

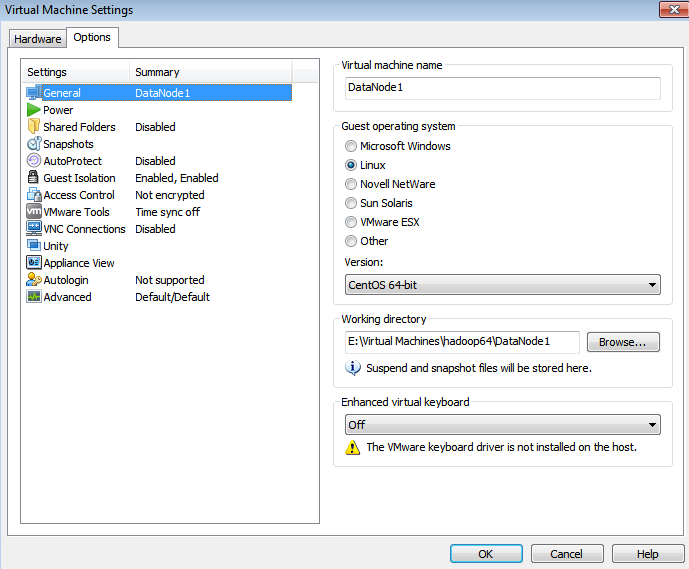
c) 用VMware打开每个DateNode,设置其虚拟机的名字
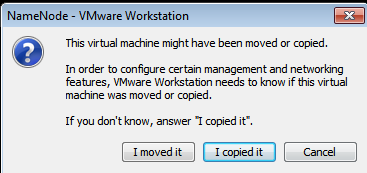
d) 打开操作系统,当弹出对话框时,选择“I copy it”
e) 打开每个虚拟机,查看ip地址
ifconfig
现将IP地址规划如下
| 10.88.106.187 |
namenode |
| 10.88.106.188 |
datanode1 |
| 10.88.106.189 |
datanode2 |
| 10.88.106.190 |
datanode3 |
| 10.88.106.191 |
datanode4 |
f) 配置NameNode
第一步,检查机器名
#hostname
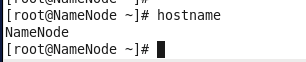
如发现不对,则修改,root用户登陆,修改命令如下
# vim /etc/sysconfig/network
|
NETWORKING=yes HOSTNAME=NameNode |
依次对每个节点进行处理,修改完之后,重启系统 #reboot
g) 修改/etc/hosts
root用户
vim /etc/sysconfig/network
(1)namenode节点上编辑/etc/hosts文件
将所有节点的名字和IP地址写入其中,写入如下内容,注意注释掉127.0.0.1行,保证内容如下:
| 10.88.106.187 namenode 10.88.106.188 datanode1 10.88.106.189 datanode2 10.88.106.190 datanode3 10.88.106.191 datanode4 # 127.0.0.1 centos63 localhost.localdomain localhost |
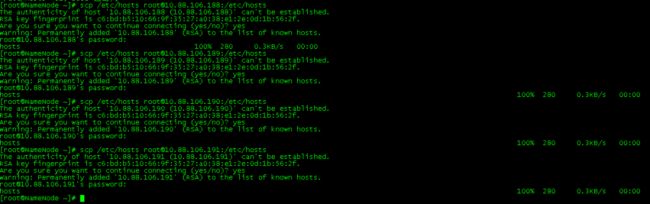
(2)将Namenode上的/etc/hosts文件复制到所有数据节点上,操作步骤如下:
root用户登录namenode;
执行命令:
scp /etc/hosts root@10.88.106.188:/etc/hosts
scp /etc/hosts [email protected]:/etc/hosts
scp /etc/hosts [email protected]:/etc/hosts
scp /etc/hosts [email protected]:/etc/hosts
h) 规划系统目录
| 完整路径 |
说明 |
| /usr/local/hadoop |
hadoop的主目录 |
| /usr/local/hadoop/tmp |
临时目录 |
| /usr/local/hadoop/hdfs/name |
namenode上存储hdfs名字空间元数据 |
| usr/local/hadoop/hdfs/data |
datanode上数据块的物理存储位置 |
| /usr/local/hadoop/mapred/local |
tasktracker上执行mapreduce程序时的本地目录 |
| /usr/local/hadoop/mapred/system |
这个是hdfs中的目录,存储执行mr程序时的共享文件 |
至于这里为什么在/usr/local下建立,解释如下
/usr 文件系统
/usr 文件系统经常很大,因为所有程序安装在这里. /usr里的所有文件一般来自Linux distribution;本地安装的程序和其他东西在/usr/local下.这样可能在升级新版系统或新distribution时无须重新安装全部程序.
/usr/local 本地安装的软件和其他文件放在这里.
小贴士:创建目录:mkdir(make directories)
功能说明:建立目录
语 法:mkdir [-p][--help][--version][-m <目录属性>][目录名称]
补充说明:mkdir可建立目录并同时设置目录的权限。
参 数:
-m<目录属性>或–mode<目录属性>建立目录时同时设置目录的权限。
-p或–parents若所要建立目录的上层目录目前尚未建立,则会一并建立上层目录。
例:mkdir test
开始建立目录:
在NameNode下,root用户
[root@NameNode ~]# mkdir -p /usr/local/hadoop/tmp
[root@NameNode ~]# mkdir -p /usr/local/hadoop/hdfs/name
[root@NameNode ~]# mkdir -p /usr/local/hadoop/hdfs/data
[root@NameNode ~]# mkdir -p /usr/local/hadoop/mapred/local
[root@NameNode ~]# mkdir -p /usr/local/hadoop/mapred/system

验证一下

可以直接进入tmp目录,不用先建立上级目录
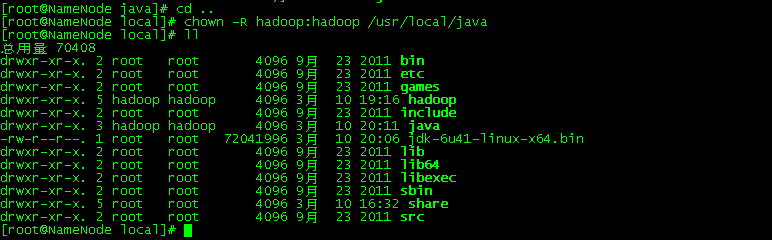
修改目录/usr/local/hadoop的拥有者(因为该目录用于安装hadoop,用户对其必须有rwx权限。)
chown -R hadoop:hadoop /usr/local/hadoop

修改前

修改后
创建完毕基础目录后,下一步就是设置SSH无密码验证,以方便hadoop对集群进行管理。
2 SSH无密码验证配置
Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解,datanode之间可能也需要使用SSH协议。假若是,则需要配置使得所有节点之间可以相互SSH无密码登陆验证。
2.1配置所有节点之间SSH无密码验证
(0)原理
节点A要实现无密码公钥认证连接到节点B上时,节点A是客户端,节点B是服务端,需要在客户端A上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到服务端B上。当客户端A通过ssh连接服务端B时,服务端B就会生成一个随机数并用客户端A的公钥对随机数进行加密,并发送给客户端A。客户端A收到加密数之后再用私钥进行解密,并将解密数回传给B,B确认解密数无误之后就允许A进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端A公钥复制到B上。
因此如果要实现所有节点之间无密码公钥认证,则需要将所有节点的公钥都复制到所有节点上。
(1)所有机器上生成密码对
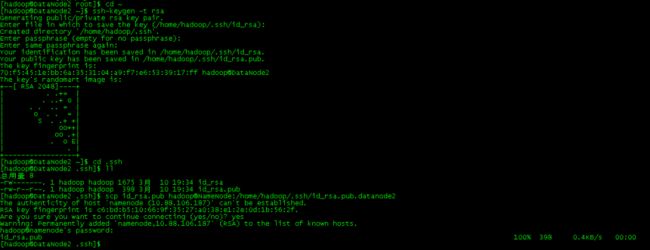
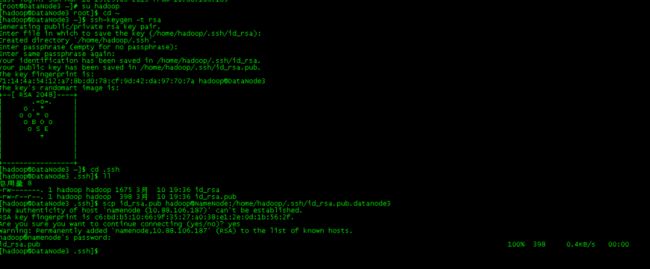
(a)所有节点用hadoop用户登陆,并执行以下命令,生成rsa密钥对:
ssh-keygen -t rsa
这将在/home/hadoop/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
# su hadoop
ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/ hadoop /.ssh/id_rsa): 默认路径
Enter passphrase (empty for no passphrase): 回车,空密码
Enter same passphrase again:
Your identification has been saved in /home/ hadoop /.ssh/id_rsa.
Your public key has been saved in /home/ hadoop /.ssh/id_rsa.pub.
这将在/home/hadoop/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
(b)将所有datanode节点的公钥id_rsa.pub传送到namenode上:
DataNode1上执行命令:
scp id_rsa.pub hadoop@NameNode:/home/hadoop/.ssh/ id_rsa.pub.datanode1
......
DataNodeN上执行命令:
scp id_rsa.pub hadoop@NameNode:/home/hadoop/.ssh/ id_rsa.pub.datanoden

DataNode1
DataNode2
DataNode3

DataNode4
检查一下是否都已传输过来
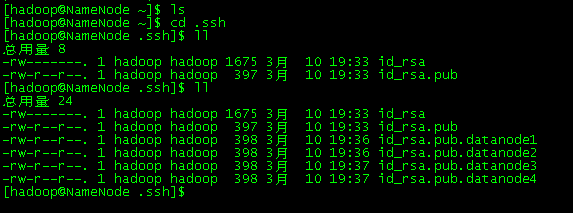
各个数据节点的公钥已经传输过来。
(c)namenode节点上综合所有公钥(包括自身)并传送到所有节点上
[hadoop@NameNode .ssh]$ cat id_rsa.pub >> authorized_keys 这是namenode自己的公钥
[hadoop@NameNode .ssh]$ cat id_rsa.pub.datanode1 >> authorized_keys
[hadoop@NameNode .ssh]$ cat id_rsa.pub.datanode2 >> authorized_keys
[hadoop@NameNode .ssh]$ cat id_rsa.pub.datanode3 >> authorized_keys
[hadoop@NameNode .ssh]$ cat id_rsa.pub.datanode4 >> authorized_keys
chmod 644 ~/.ssh/authorized_keys
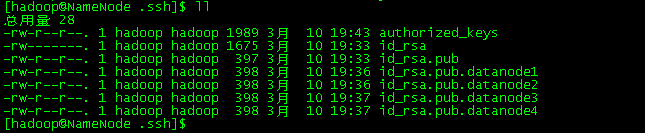
使用SSH协议将namenode的公钥信息authorized_keys复制到所有DataNode的.ssh目录下。
scp authorized_keys data节点ip地址:/home/hadoop/.ssh
scp ~/.ssh/authorized_keyshadoop@DataNode1:/home/hadoop/.ssh/authorized_keys
scp ~/.ssh/authorized_keyshadoop@DataNode2:/home/hadoop/.ssh/authorized_keys
scp ~/.ssh/authorized_keyshadoop@DataNode3:/home/hadoop/.ssh/authorized_keys
scp ~/.ssh/authorized_keyshadoop@DataNode4:/home/hadoop/.ssh/authorized_keys

从这里就可以看到,当配置好hosts之后,就可以直接以机器名来访问各个机器,不用再记忆各个机器的具体IP地址,当集群中机器很多且IP不连续时,就发挥出威力来了。
从上图可以看到,将authorized_keys分发给各个节点之后,可以直接ssh登录,不再需要密码。
这样配置过后,namenode可以无密码登录所有datanode,可以通过命令
“ssh DataNode1(2,3,4)”来验证。
配置完毕,在namenode上执行“ssh NameNode,所有数据节点”命令,因为ssh执行一次之后将不会再询问。在各个DataNode上也进行“ssh NameNode,所有数据节点”命令。
至此,所有的节点都能相互访问,下一步开始配置jdk
3 JDK安装和Java环境变量配置
3.1 安装 JDK 1.6
1.下载JDK。
选定linux环境版本,下载到的文件是:jdk-6u41-linux-x64.bin
2.创建JDK安装目录。
在Linux系统硬盘系统文件夹usr/local下创建一个文件夹Java。
命令:mkdir –P /usr/local/java
3.复制JDK安装包到系统指定文件夹。
把下载的安装文件(jdk-6u41-linux-x64.bin )拷到linux路径/usr/local/java下。
4.给安装文件赋予权限。
a).进入目录,命令:cd /usr/local/java
b).赋予权限,命令:chmod +x jdk-6u41-linux-x64.bin
(如果因权限问题执行失败,则加上su, 即su chmod u+x jdk-6u41-linux-x64.bin )
5安装JDK。
开始安装,在控制台执行命令: ./ jdk-6u41-linux-x64.bin
(如果因权限问题执行失败,则加上su , 即sud./jdk-6u41-linux-x64.bin )
文件会被安装到当前目录 /usr/local/java/jdk1.6.0_41
删除安装文件rm jdk-6u41-linux-x64.bin
安装完成后,修改/usr/local/java目录拥有着为hadoop用户,
chown -R hadoop:hadoop /usr/local/java
然后将 /usr/local/java目录需要复制到所有数据节点上。
3.2 Java环境变量配置
root用户登陆,命令行中执行命令”vim /etc/profile”,并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面Hadoop的配置还会用到)。

# set java environment
#set java environment
JAVA_HOME=/usr/local/java/jdk1.6.0_41
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH
保存并退出,执行以下命令使配置生效
chmod +x /etc/profile
source /etc/profile
配置完毕,在命令行中使用命令“java -version”可以判断是否成功。在hadoop用户下测试java –version,一样成功。
a).输入命令打印三个环境变量的值:
echo $JAVA_HOME
echo $CLASSPATH
echo $PATH
b).正确的结果如下:
[root@NameNode ~]# echo $JAVA_HOME
/usr/local/java/jdk1.6.0_41
[root@NameNode ~]# echo $CLASSPATH
.:/usr/local/java/jdk1.6.0_41/lib/dt.jar:/usr/local/java/jdk1.6.0_41/lib/tools.jar
[root@NameNode ~]# echo $PATH
/usr/local/java/jdk1.6.0_41/bin:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@NameNode ~]#

将Namenode上的/etc/profile复制到所有数据节点上。操作步骤如下:
root用户登录namenode;
执行命令:
scp /etc/profile root@(datanode1):/etc/profile
……
scp /etc/profile root@(datanoden):/etc/profile
4 Hadoop集群配置
在namenode上执行:
Hadoop用户登录。
下载hadoop-0.20.2,将其解压到/usr/local/hadoop目录下,解压后目录形式是/usr/local/hadoop/ hadoop-0.20.2。使用如下命令:
tar zxvf hadoop-0.20.2.tar.gz
(1)配置Hadoop的配置文件
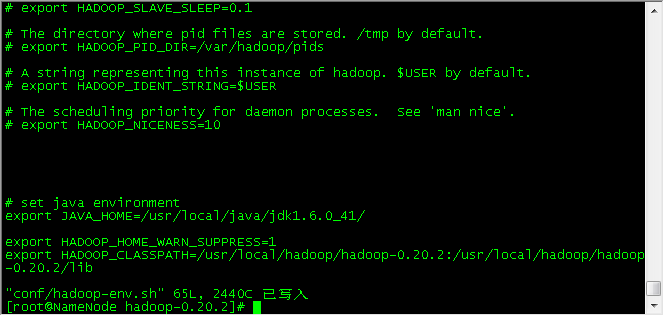
(a)配置hadoop-env.sh
$ vim /usr/local/hadoop/hadoop-0.20.2/conf/hadoop-env.sh
| # set java environment export JAVA_HOME=/usr/local/java/jdk1.6.0_41/
export HADOOP_HOME_WARN_SUPPRESS=1 export HADOOP_CLASSPATH=/usr/local/hadoop/hadoop-0.20.2:/usr/local/hadoop/hadoop-0.20.2/lib |
(b)配置/etc/profile
|
#set java enviroment export HADOOP_HOME=/usr/local/hadoop/hadoop-0.20.2 export HADOOP_HOME_WARN_SUPPRESS=1 JAVA_HOME=/usr/local/java/jdk1.6.0_41 JRE_HOME=/usr/local/java/jdk1.6.0_41/jre PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/bin/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME CLASSPATH PATH |
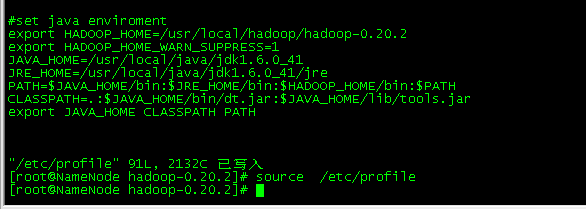
修改完,重启/etc/profile
[root@NameNode ~]# source /etc/profile
(c)配置conf/hadoop-site.xml
Hadoop-0.20.2之后的版本请分别配置core-site.xml,hdfs-site.xml和mapred-site.xml三个配置文件。
| 配置文件名(xml) |
字段名 |
字段值 |
说明 |
| core-site |
fs.default.name |
hdfs://NameNode:9000 |
|
| hadoop.tmp.dir |
/usr/local/hadoop/tmp |
临时目录 |
|
| hdfs-site |
dfs.name.dir |
/usr/local/hadoop/hdfs/name |
namenode上存储hdfs名字空间元数据 |
| dfs.data.dir |
usr/local/hadoop/hdfs/data |
datanode上数据块的物理存储位置 |
|
| dfs.replication |
3 |
副本个数,不配置默认是3,应小于datanode机器数量 |
|
| mapred-site |
mapred.job.tracker |
NameNode:9001 |
jobtracker标识:端口号,不是URI |
| mapred.local.dir |
/usr/local/hadoop/mapred/local |
tasktracker上执行mapreduce程序时的本地目录 |
|
| mapred.system.dir |
/usr/local/hadoop/mapred/system |
这个是hdfs中的目录,存储执行mr程序时的共享文件 |
| core-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.default.name</name> <value>hdfs://NameNode:9000</value> </property>
<property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration> |
|
hdfs-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> |
mapred-site.xml
|
mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>NameNode:9001</value> </property>
<property> <name>mapred.local.dir</name> </property> <property> <name>mapred.system.dir</name> </property> </configuration> |
(d)配置masters文件,加入namenode的主机名
| NameNode |
(e)配置slaves文件, 加入所有datanode的主机名
| DataNode1 DataNode2 DataNode3 DataNode4 |
(2)复制配置好的各文件到所有数据节点上。
在每个节点,首先建立文件夹
mkdir /usr/local/hadoop
然后更改文件夹的属主
chown hadoop:hadoop /usr/local/hadoop/
在NameNode
root用户下:
scp /etc/hosts DataNode1:/etc/hosts
scp /etc/profile DataNode1:/etc/profile
scp /usr/java -r DataNode1:/usr/java
……
scp /etc/hosts DataNode4:/etc/hosts
scp /etc/profile DataNode4:/etc/profile
scp /usr/local/java/* -r DataNode4:/usr/local/java
![]()
scp -r /usr/local/hadoop/* hadoop@DataNode1:/usr/local/hadoop
scp -r /usr/local/hadoop/* hadoop@DataNode2:/usr/local/hadoop
scp -r /usr/local/hadoop/* hadoop@DataNode3:/usr/local/hadoop
scp -r /usr/local/hadoop/* hadoop@DataNode4:/usr/local/hadoop
复制完之后,需要在各个datanode节点上执行
chown -R hadoop:hadoop /usr/local/java
chown -R hadoop:hadoop /usr/local/hadoop (在各个节点上看,已经属于hadoop了,这里执行一次,以防万一)
5 Hadoop集群启动
Namenode执行:
格式化namenode,格式化后在namenode生成了hdfs/name文件夹
bin/hadoop namenode –format
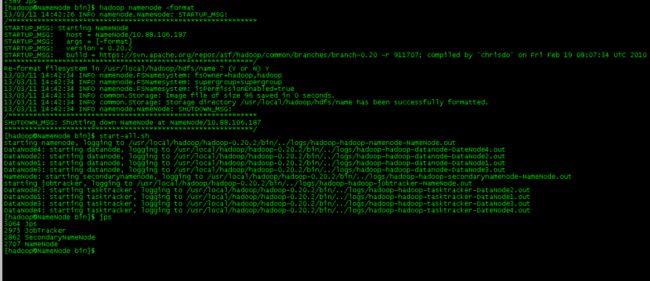
[hadoop@namenode bin]$ bin/start-all.sh
[hadoop@namenode bin]$ start-all.sh
************************************************************/
[hadoop@NameNode bin]$ start-all.sh
starting namenode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-namenode-NameNode.out
DataNode4: starting datanode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-datanode-DateNode4.out
DataNode2: starting datanode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-datanode-DataNode2.out
DataNode1: starting datanode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-datanode-DataNode1.out
DataNode3: starting datanode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-datanode-DataNode3.out
NameNode: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-secondarynamenode-NameNode.out
starting jobtracker, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-jobtracker-NameNode.out
DataNode2: starting tasktracker, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-tasktracker-DataNode2.out
DataNode1: starting tasktracker, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-tasktracker-DataNode1.out
DataNode3: starting tasktracker, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-tasktracker-DataNode3.out
DataNode4: starting tasktracker, logging to /usr/local/hadoop/hadoop-0.20.2/bin/../logs/hadoop-hadoop-tasktracker-DateNode4.out
[hadoop@namenode bin]$
启动hadoop所有进程,
bin/start-all.sh(或者先后执行start-dfs.sh和start-mapreduce.sh)。

可以通过以下启动日志看出,首先启动namenode,然后启动datanode1,datanode4, datanode2,datanode3,然后启动secondarynamenode。再启动jobtracker,然后启动tasktracker2, tasktracker1,tasktracker4最后启动tasktracker3。
namenode上用java自带的小工具jps查看进程
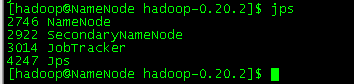
每个datanode上查看进程

在这里需要对每个NameNode进行检查,当发现用JPS命令而没有发现DataNode时,需要对集群进行重新格式化。
在namenode上查看集群状态
bin/ hadoop dfsadmin -report

Hadoop查看工作情况:http:// namenode ip地址:50030
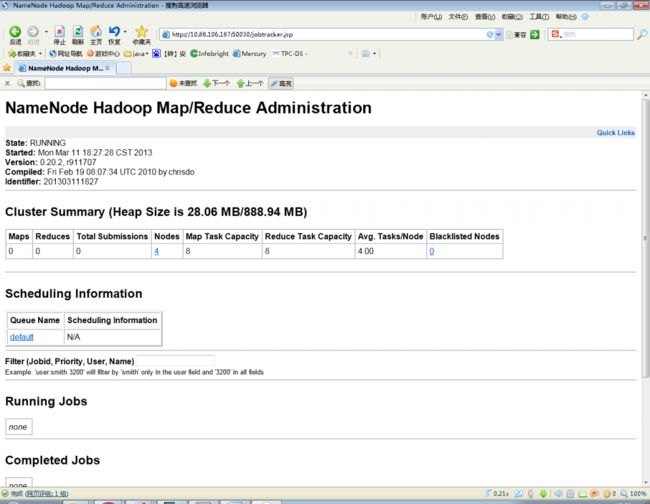
Hadoop 的web 方式查看:http://namenode ip地址:50070

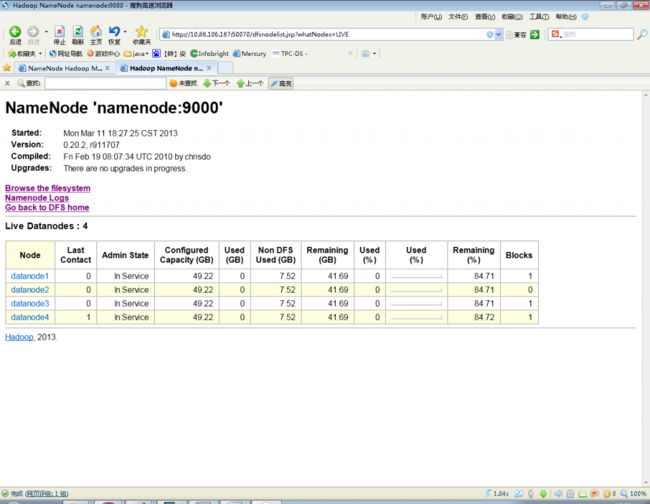
6 Hadoop使用
Hadoop有两个重要的模块:MapReduce和HDFS,HDFS是一个分布式文件系统,用于存储数据,MapReduce是一个编程框架,Hadoop中运行的程序均是MapReduce作业,一个作业分为若干个Map任务和Reduce任务。
6.1 客户机与HDFS进行交互
6.1.1 客户机配置
可以查看HDFS中的数据,向HDFS中写入数据。
(1)选择一台机器,该机器可以是Hadoop集群中的节点,也可以是集群之外的机器。下面说明在集群之外的客户机上如何操作与HDFS交互,集群之内的节点省去配置过程。
(2)集群之外的机器请保证和Hadoop集群是网络连通的,直接将NameNode的hadoop文件夹scp过去即可
(3)按照以上步骤配置完成后,即可在客户机的命令行中执行命令,查看HDFS文件系统。
6.1.2 列出HDFS根目录/下的文件
[hadoop@namenode bin]$ bin/hadoop dfs -ls /

第一列是目录权限,第二列的hadoop是目录拥有者,第三列是组名,第4列是目录大小(单位是B),第5列是目录的绝对路径。这里表示/目录下有三个目录。这里的用户hadoop是安装hadoop的用户,是超级用户,相当于Linux操作系统的root用户,组supergroup相当于root用户组。
6.1.3 HDFS用户管理
创建HDFS用户需要使用hadoop用户登录客户机器,并且执行hadoop相关命令。由于Hadoop默认当前HDFS中的用户就是当前登录客户机的用户,所以当前HDFS用户即为Hadoop超级用户hadoop。
Hadoop似乎没有提供创建用户的命令,但要在HDFS中创建用户和用户组可以这样做。
(i)Hadoop超级用户hadoop在hdfs中创建目录/user/root,
即 hadoop dfs -mkdir /user/root
(ii)更改/user/root目录所属用户和组,
即bin/hadoop dfs -chown -R root:root /user/root,命令执行完毕Hadoop将默认创建有用户root,用户组root。
注意:若此处没有指定组,则默认将root用户分配到supergroup组, bin/hadoop dfs -chown -R root /user/root
(ii)这样就相当于在hdfs中创建了用户root,组root。并且当前客户机的root用户对hdfs中的/user/root目录进行rwx。
6.1.5 复制本地数据到HDFS中
[hadoop@namenode bin]# bin/hadoop dfs –copyFromLocal /local/x /user/root/
执行以上命令即能将本地数据上传到HDFS中,上传的文件将会被分块,并且数据块将物理存储在集群数据节点的hadoop-site.xml文件中的dfs.data.dir参数指定的目录下,用户可以登录数据节点查看相应数据块。
HDFS中一个文件对应若干数据块,如果文件小于块大小(默认64M),则将会存储到一个块中,块大小即文件大小。若文件很大,则分为多个块存储。
6.1.6 数据副本说明
Hadoop-site.xml文件中的dfs.replication参数指定了数据块的副本数量。一个文件被分为若干数据块,其所有数据块副本的名字和元数据都是一样的,例如下图显示了上传一个目录(包含两个小文件)到HDFS后数据节点中数据块情况:
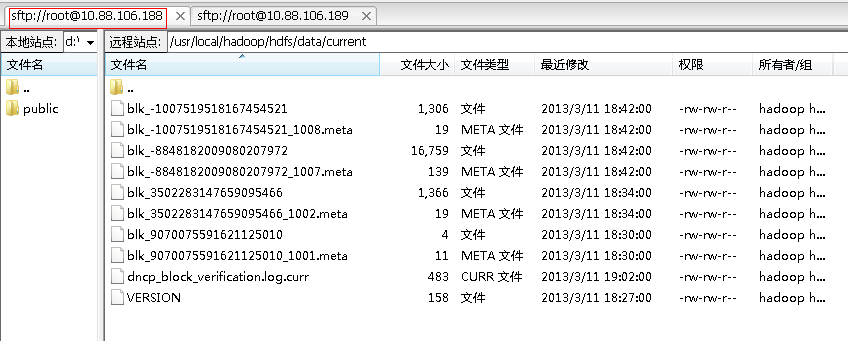
图 节点一上的副本

图 节点二上的副本
6.1.7 hadoop-site.xml参数说明
(1) hadoop.tmp.dir
该参数默认值是“/tmp/hadoop-{当前登录用户名}”。
它是本地路径,当第一次启动Hadoop集群进程时在namenode节点的本地创建该目录,其作用是存储相关临时文件。
(2)mapred.system.dir
该参数默认值是${hadoop.tmp.dir}/mapred/system,它所表示的目录是hdfs中的路径,是相对于dfs.default.name的路径,即它在hdfs中的绝对路径是{$dfs.default.name}/{$mapred.system.dir}。
该参数指定的目录的作用是当作业运行时,存储作业相关文件,供tasktracker节点共享。
一般hdfs系统中/目录下可以看到该参数指定的目录,如
[hadoop@namenode bin]$ hadoop dfs -lsr /

其他参数参见hadoop-default.xml中的说明。
6.1.8 HDFS中的路径
首先请查阅资料,把握URI的概念。在HDFS中,例如下面这些形式均是URI(注意不是URL,URI概念比URL更广)。例如file:///,hdfs://x/y/z,/x/y/z,z。
HDFS路径应该可以分为三种:绝对URI路径,即
hdfs://namenode:端口/xxxx/xxxx
这种形式;HDFS绝对路径 ,例如/user或者///user,注意使用/或者///表示根目录,而不能使用//;HDFS相对路径,例如x,此路径往往是相对于当前用户主目录/user/用户名而言,例如x对应的HDFS绝对路径是/user/hadoop/x。
6.1.8 Hadoop相关命令
Hadoop提供一系列的命令,在bin中,例如bin/hadoop fs –x;bin/hadoop namenode –x等等。其中有些命令只能在namenode上执行。
bin下还有一些控制脚本,例如start-all.sh、start-mapred.sh、start-dfs.sh等等。数据节点上运行start-all.sh将会只启动本节点上的进程,如datanode、tasktracker。
6.2 客户机提交作业到集群
6.2.1 客户机配置
可以在客户机上向Hadoop集群提交作业。
(1)选择一台机器,该机器可以是Hadoop集群中的节点,也可以是集群之外的机器。下面说明在集群之外的客户机上如何向hadoop提交作业,集群之内的节点省去配置过程。
(2)集群之外的机器请保证和Hadoop集群是网络连通的,并且安装了Hadoop(解压安装包即可)并在conf/hadoop-site.xml中做了相关配置,至少配置如下:
core-site.xml
| <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.default.name</name> <value>hdfs://NameNode:9000</value> </property> </configuration> |
mapred-site.xml
| <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.job.tracker</name> <value>NameNode:9001</value> </property> </configuration>
|
(3)按照以上步骤配置完成后,即可在客户机的命令行中执行命令,向hadoop提交作业。
6.2.2 一个测试例子WordCount
计算输入文本中词语数量的程序WordCount在Hadoop主目录下的java程序包hadoop-0.20.2-examples.jar中,执行步骤如下:
(1)上传数据到HDFS中
[hadoop@NameNode hadoop-0.20.2]$ hadoop fs -copyFromLocal /usr/local/hadoop/hadoop-0.20.2/README.txt input

[hadoop@NameNode hadoop-0.20.2]$ hadoop dfs -ls input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 1366 2013-03-11 18:34 /user/hadoop/input
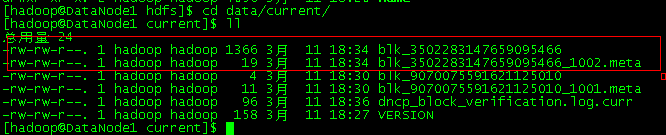
Datanode1下的数据

DataNode2下的数据

DataNode3下没有数据

DataNode4下的数据
在这个集群中,定义数据的副本为3,集群中有4个节点,数据分别在DataNode1、DataNode2、DataNode4 这三处存放。
(2)执行命令,提交作业
[hadoop@namenode hadoop-0.20.2]$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output

|
[hadoop@NameNode hadoop-0.20.2]$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output 13/03/11 18:42:42 INFO input.FileInputFormat: Total input paths to process : 1 13/03/11 18:42:42 INFO mapred.JobClient: Running job: job_201303111827_0001 13/03/11 18:42:43 INFO mapred.JobClient: map 0% reduce 0% 13/03/11 18:42:52 INFO mapred.JobClient: map 100% reduce 0% 13/03/11 18:43:04 INFO mapred.JobClient: map 100% reduce 100% 13/03/11 18:43:06 INFO mapred.JobClient: Job complete: job_201303111827_0001 13/03/11 18:43:06 INFO mapred.JobClient: Counters: 17 13/03/11 18:43:06 INFO mapred.JobClient: Job Counters 13/03/11 18:43:06 INFO mapred.JobClient: Launched reduce tasks=1 13/03/11 18:43:06 INFO mapred.JobClient: Launched map tasks=1 13/03/11 18:43:06 INFO mapred.JobClient: Data-local map tasks=1 13/03/11 18:43:06 INFO mapred.JobClient: FileSystemCounters 13/03/11 18:43:06 INFO mapred.JobClient: FILE_BYTES_READ=1836 13/03/11 18:43:06 INFO mapred.JobClient: HDFS_BYTES_READ=1366 13/03/11 18:43:06 INFO mapred.JobClient: FILE_BYTES_WRITTEN=3704 13/03/11 18:43:06 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=1306 13/03/11 18:43:06 INFO mapred.JobClient: Map-Reduce Framework 13/03/11 18:43:06 INFO mapred.JobClient: Reduce input groups=131 13/03/11 18:43:06 INFO mapred.JobClient: Combine output records=131 13/03/11 18:43:06 INFO mapred.JobClient: Map input records=31 13/03/11 18:43:06 INFO mapred.JobClient: Reduce shuffle bytes=1836 13/03/11 18:43:06 INFO mapred.JobClient: Reduce output records=131 13/03/11 18:43:06 INFO mapred.JobClient: Spilled Records=262 13/03/11 18:43:06 INFO mapred.JobClient: Map output bytes=2055 13/03/11 18:43:06 INFO mapred.JobClient: Combine input records=179 13/03/11 18:43:06 INFO mapred.JobClient: Map output records=179 13/03/11 18:43:06 INFO mapred.JobClient: Reduce input records=131 [hadoop@NameNode hadoop-0.20.2]$ |
命令执行完毕,在页面http://namenodeip:50030/中能够看到作业执行情况。


(3)程序输出
程序将统计input目录下的所有文本文件中词语的数量,并将结果输出到hdfs的output目录下的part-00000文件中。这里的output目录是程序生成的目录,程序运行前不可存在。执行以下命令可以查看结果。
[hadoop@namenode hadoop-0.20.2]$ hadoop fs -ls output
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2013-03-09 23:35 /user/hadoop/output/_logs
-rw-r--r-- 3 hadoop supergroup 127741 2013-03-09 23:35 /user/hadoop/output/part-r-00000
6.2.3 编写Hadoop应用程序并在集群上运行
这里介绍一个向HDFS中写入数据的例子(注意不是MR程序)来说明编写Hadoop应用程序并放到集群上运行的步骤。
(1)客户端编写应用程序并编译运行,进行测试。
编写程序一般需要引入hadoop相关jar包或者直接使用hadoop整个程序包,相关代码见附录。
(2)打包应用程序
在eclipse中打包成jar文件存储到相应目录下,例如/hadoop/ jarseclipse/dfsOperator.jar。
(3)上传数据到HDFS
bin/hadoop fs –copyFromLocal local dst
本实例中不需要上传数据,一般的程序都涉及输入数据。
(4)执行应用程序
bin/hadoop jar x.jar jar包中主类名 [输入参数] [输出参数]
这里使用的命令是:
bin/hadoop jar ~/jarseclipse/dfsOperator.jar DFSOperator
6.2.4 三种模式下编译运行Hadoop应用程序
集群是完全分布式环境,Hadoop的MR程序将以作业的形式提交到集群中运行。我们在客户端编写Hadoop应用程序时一般是在伪分布式模式或单击模式下进行编译,然后将编译无误的程序打成包提交到Hadoop集群中,当然我们仍可直接让程序在Hadoop集群中编译。
(1)让Hadoop应用程序在直接在集群中编译
将hadoop整个包导入eclipse中,配置core-site.xml和mapred-site.xml文件如下:
| core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://NameNode:9000</value> </property> </configuration>
mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value> NameNode:9001</value> </property> </configuration> |
编写应用程序,编译运行,此时程序将直接在Hadoop集群中运行。此种方法在开发中不建议使用,以防止破坏集群环境。
(2)单机模式下编译Hadoop应用程序
将hadoop整个包导入eclipse中, hadoop-site.xml文件不做任何配置,保留默认的空配置。
单机模式下运行Hadoop应用程序时,程序使用的是本地文件系统。
(3)伪分布式模式下编译Hadoop应用程序
在单机上配置Hadoop伪分布式模式,配置文件hadoop-site.xml如下:
| core-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> hdfs-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> |
使用bin/start-all.sh启动伪分布式集群。
将hadoop整个包导入eclipse中,并将hadoop-site.xml文件配置为以上一样的内容。(或者直接将上面的hadoop目录导入eclipse中)。
编写应用程序并运行,此时程序将在伪分布式模式下运行,使用的是HDFS。
6.2.5 提交多个作业到集群
提交一个后,可以继续提交,这样集群中将有多个作业,Hadoop有一个作业队列,可以在以下网址中查看。
http://10.88.106.187:50030/jobqueue_details.jsp?queueName=default

涉及多个作业时,Hadoop将对作业进行调度,默认调度方式是基于优先级的FIFO方式。
更改作业优先级命令
作业优先级有五种:VERY_HIGH HIGH NORMAL LOW VERY_LOW
例如:
bin/hadoop job -set-priority job_201005210042_0074 VERY_HIGH
附录:Hadoop安装常见错误
1 INFOhdfs.DFSClient: Exception in createBlockOutputStreamjava.net.NoRouteToHostException: No route to host
错误原因: 没有关闭防火墙
2. be replicated to 0 nodes, instead of 1
原因:多次格式化namenode,造成namenode节点的namespaceID和datanode节点的namespaceID不一致。
处理方法1:所有的datanode删掉,重新建
处理方法2: 登上datanode,把位于{dfs.data.dir}/current/VERSION中的namespaceID改为最新的版本即可
[hadoop@namenode current]$ cat VERSION
#Fri Dec 14 09:37:22 CST 2012
namespaceID=525507667
storageID=DS-120876865-10.4.124.236-50010-1354772633249
cTime=0
storageType=DATA_NODE
layoutVersion=-32
[hadoop@DataNode1 current]$ cat VERSION
#Mon Mar 11 18:27:58 CST 2013
namespaceID=1736724608
storageID=DS-203565513-10.88.106.188-50010-1362997678871
cTime=0
storageType=DATA_NODE
layoutVersion=-18
两个namespaceID不一致,把DataNode节点的namespaceID修改为NameNode的值。
3.用JPS命令,没有发现NameNode或DataNode
处理措施:
处理措施1:将NameNode和DataNode下的tmp和hdfs/name清空,重新执行格式化。
处理措施2:将NameNode下的tmp和hdfs/name清空。将DataNode下hadoop文件夹删除,重建。
然后用scp命令将 /usr/local/hadoop文件夹复制到各个DataNode下的/usr/local/hadoop
scp -r/usr/local/hadoop/* hadoop@DataNode1:/usr/local/hadoop
…
scp -r/usr/local/hadoop/* hadoop@DataNode4:/usr/local/hadoop