hadoop2高可用集群配置安装
上一节演示了 hadoop2集群安装和测试 其中namenode节点是单点的,一旦namenode宕机,服务将不可使用。本节使用zookeeper配置hadoop namenode的可用集群,并使用yarn对hadoop提供统一的资源管理和调度。
关于操作系统环境的配置以及hadoop、zookeeper的安装这里就不介绍,请参考如下文档:
1.linux上Zookeeper集群安装及监控
2.hadoop2集群安装和测试之环境配置
3.hadoop2集群安装和测试之软件安装配置
机器分配如下:
study-90 NameNode、DFSZKFailoverController(zkfc)、ResourceManager、QuorumPeerMain
study-91 NameNode、DFSZKFailoverController(zkfc)、ResourceManager、QuorumPeerMain
study-92 DataNode、NodeManager、JournalNode、QuorumPeerMain
study-93 DataNode、NodeManager、JournalNode、JobHistoryServer
QuorumPeerMain为zookeeper进程,JournalNode和zookeeper保持奇数点,最少不少于3个节点,由于机器配置有限这里JournalNode我只配置了2各节点。JobHistory Server这是一个独立的服务,可通过web UI展示历史作业日志,之所以将其独立出来,是为了减轻ResourceManager负担。
为了防止ssh需要密码,我们将这4台机器的的/home/hadoop/.ssh/id_rsa.pub公钥内容追加到同一个authorized_keys(文件权限644),并将其复制到所有机器的/home/hadoop/.ssh下。
一、配置hadoop
1.core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为mycluster,命名空间的逻辑名称,多个以逗号分隔 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0/temp</value>
</property>
<!-- 配置文件缓存buffer -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>study-90:2181,study-91:2181,study-92:2181</value>
</property>
</configuration>
2.hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是study-90,study-91 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>study-90,study-91</value>
</property>
<!-- study-90的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.study-90</name>
<value>study-90:9000</value>
</property>
<!-- study-90的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.study-90</name>
<value>study-90:50070</value>
</property>
<!-- study-91的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.study-91</name>
<value>study-91:9000</value>
</property>
<!-- study-91的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.study-91</name>
<value>study-91:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://study-92:8485;study-93:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop-2.6.0/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- namenode数据存储位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/dfs/namenode</value>
<final>true</final>
</property>
<!-- data数据存储位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/dfs/datanode</value>
<final>true</final>
</property>
<!-- 副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 使WebHDFS Namenodes和Datanodes(REST API)。-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 在HDFS中启用权限检查 TRUE|FALSE。 建议关闭,不然开发机器会有权限问题 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
3.mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!-- mapred存放控制文件所使用的文件夹,可配置多块硬盘,逗号分隔。-->
<property>
<name>mapred.system.dir</name>
<value>file:/home/hadoop/mapred/system</value>
<final>true</final>
</property>
<!-- mapred做本地计算所使用的文件夹,可以配置多块硬盘,逗号分隔 -->
<property>
<name>mapred.local.dir</name>
<value>file:/home/hadoop/mapred/local</value>
<final>true</final>
</property>
<!-- 通过web UI展示历史作业日志 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>study-93:10020</value>
</property>
</configuration>
4.yarn-site.xml
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>study-90</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>study-91</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>study-90:2181,study-91:2181,study-92:2181</value>
</property>
<property>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.slaves
study-92 study-93配置完成,将hadoop安装目录复制到其他机器对应的目录
scp -r hadoop-2.6.0 hadoop@study-91:/home/hadoop/hadoop-2.6.0
二、启动hadoop
1.格式化ZK创建命名空间
./bin/hdfs zkfc -formatZK
2.启动journalnode
在study-92、study-93上启动JournalNode进程
sbin/hadoop-daemon.sh start journalnode
3.格式化HDFS
在study-90上格式化HDFS
./bin/hdfs namenode -format mycluster
并将根据dfs.namenode.name.dir配置格式化生产的dfs目录复制到study-91对应的目录上
scp -r dfs/ study-91:/home/hadoop/hadoop-2.6.0/
4.启动hadoop节点
在study-90节点:
./sbin/start-dfs.sh
./sbin/start-yarn.sh
在study-91节点:
./sbin/yarn-daemon.sh start resourcemanager
在study-93节点:
./sbin/mr-jobhistory-daemon.sh start historyserver
可以通过jps查看启动进程:
[hadoop@study-90 sbin]$ jps 1566 QuorumPeerMain 24184 DFSZKFailoverController 24650 Jps 23921 NameNode 24286 ResourceManager三、测试
1.环境是否可用
vi ~/test/hello.txt
hello world hello tom good by good nice将文件提交到dfs中
./bin/hadoop fs -put ~/test/ /input
运行单词统计例子:
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /input /output
15/09/25 03:35:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/09/25 03:35:13 INFO input.FileInputFormat: Total input paths to process : 1
15/09/25 03:35:13 INFO mapreduce.JobSubmitter: number of splits:1
15/09/25 03:35:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1443164125300_0001
15/09/25 03:35:15 INFO impl.YarnClientImpl: Submitted application application_1443164125300_0001
15/09/25 03:35:15 INFO mapreduce.Job: The url to track the job: http://study-92:8088/proxy/application_1443164125300_0001/
15/09/25 03:35:15 INFO mapreduce.Job: Running job: job_1443164125300_0001
15/09/25 03:35:55 INFO mapreduce.Job: Job job_1443164125300_0001 running in uber mode : false
15/09/25 03:35:55 INFO mapreduce.Job: map 0% reduce 0%
15/09/25 03:37:05 INFO mapreduce.Job: map 67% reduce 0%
15/09/25 03:37:09 INFO mapreduce.Job: map 100% reduce 0%
15/09/25 03:39:45 INFO mapreduce.Job: map 100% reduce 67%
15/09/25 03:39:48 INFO mapreduce.Job: map 100% reduce 100%
15/09/25 03:40:39 INFO mapreduce.Job: Job job_1443164125300_0001 completed successfully
15/09/25 03:40:39 INFO mapreduce.Job: Counters: 48
File System Counters
FILE: Number of bytes read=71
FILE: Number of bytes written=216098
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=137
HDFS: Number of bytes written=41
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Total time spent by all maps in occupied slots (ms)=92911
Total time spent by all reduces in occupied slots (ms)=101550
Total time spent by all map tasks (ms)=92911
Total time spent by all reduce tasks (ms)=101550
Total vcore-seconds taken by all map tasks=92911
Total vcore-seconds taken by all reduce tasks=101550
Total megabyte-seconds taken by all map tasks=95140864
Total megabyte-seconds taken by all reduce tasks=103987200
Map-Reduce Framework
Map input records=4
Map output records=8
Map output bytes=72
Map output materialized bytes=71
Input split bytes=97
Combine input records=8
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=71
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1266
CPU time spent (ms)=3600
Physical memory (bytes) snapshot=267403264
Virtual memory (bytes) snapshot=1689710592
Total committed heap usage (bytes)=130592768
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=40
File Output Format Counters
Bytes Written=41
运行过程中可以通过http://study-92:8088/proxy/application_1443164125300_0001/查看job运行状态,结束后查看
/output目录文件信息结果:
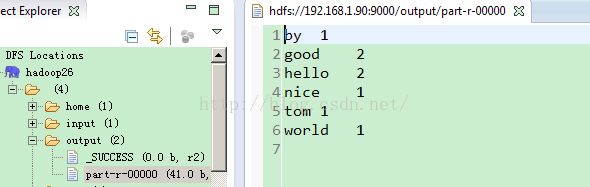
2.可用性检查
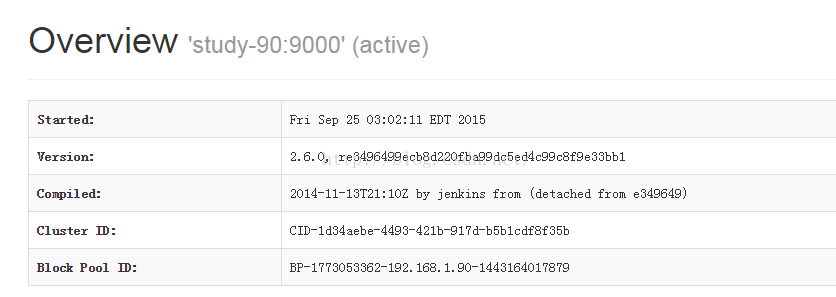
服务启动后可以通过http://192.168.1.90:50070/查看namenode状态,90为active,91为standby
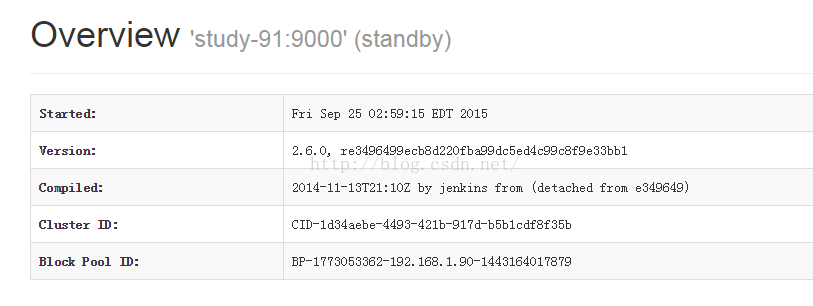
将study-90上的NameNode的进程kill掉,可以看见namenode active 切换到study-91。
参考文章:
1.Hadoop-2.4.0分布式安装手册