Oracle 聚簇因子(Clustering factor)
聚簇因子是 Oracle 统计信息中在CBO优化器模式下用于计算cost的参数之一,决定了当前的SQL语句是否走索引,还是全表扫描以及是否作为嵌套连接外部表等。如此这般,那到底什么是聚簇因子,那些情况下会影响到聚簇因子,以及如何提高聚簇因子?本文将对此展开描述。
1、堆表的存储方式
Oralce 数据库系统中最普通,最为常用的即为堆表。
堆表的数据存储方式为无序存储,也就是任意的DML操作都可能使得当前数据块存在可用的空闲空间。
处于节省空间的考虑,块上的可用空闲空间会被新插入的行填充,而不是按顺序填充到最后被使用的块上。
上述的操作方式导致了数据的无序性的产生。
当创建索引时,会根据指定的列按顺序来填充到索引块,缺省的情况下为升序。
新建或重建索引时,索引列上的顺序是有序的,而表上的顺序是无序的,也就是存在了差异,即表现为聚簇因子。
2、什么是聚簇因子(clustering factor/CF)
聚簇因子是基于表上索引列上的一个值,每一个索引都有一个聚簇因子。
用于描述索引块上与表块上存储数据在顺序上的相似程度,也就说表上的数据行的存储顺序与索引列上顺序是否一致。
在全索引扫描中,CF的值基本上等同于物理I/O或块访问数,如果相同的块被连续读,则Oracle认为只需要1次物理I/O。
好的CF值接近于表上的块数,而差的CF值则接近于表上的行数。
聚簇因子在索引创建时就会通过表上存存在的行以及索引块计算获得。
3、Oracle 如何计算聚簇因子
执行或预估一次全索引扫描。
检查索引块上每一个rowid的值,查看是否前一个rowid的值与后一个指向了相同的数据块,如果指向了不相同的数据块则CF的值增加1。
当索引块上的每一个rowid被检查完毕,即得到最终的CF值。
4、聚簇因子图示
a、良好的索引与聚簇因子的情形

b、良好的索引、差的聚簇因子的情形

c、差的索引、差的聚簇因子的情形
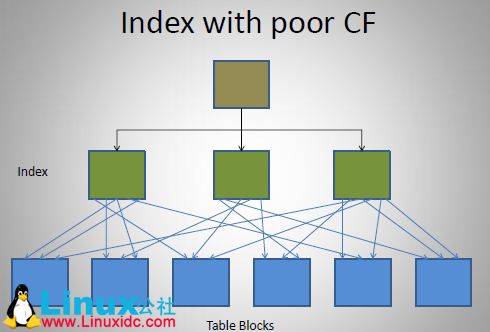
5、影响聚簇因子的情形
当插入到表的数据与索引的顺序相同时,可以提高聚簇因子(接近表上的块数)。
因此,任意影响该顺序的情形都将导致索引列上的聚簇因子变差。
如列的顺序,反向索引,空闲列表或空闲列表组。
6、提高聚簇因子
堆表的数据存储是无序存储,因此需要使无序变为有序。下面是提高聚簇因子的办法。
a、对于表上的多个索引以及组合索引的情形,索引的创建应考虑按应该按照经常频繁读取的大范围数据的读取顺序来创建索引。
b、定期重构表(针对堆表),也就是使得表与索引上的数据顺序更接近。注意,是重构表,而不是重建索引。
重建索引并不能显剧提高CF的值,因为索引列通常是有序的,无序的是原始表上的数据。
提取原始表上的ddl来创建一个临时表,将原始表的数据按索引访问顺序填充到临时表,删除原始表,重命名临时表到原表。
c、使用聚簇表来代替堆表。
7、实战聚簇因子随索引结构变化的情形
a、演示环境
scott@SYBO2SZ> select * from v$version where rownum<2;
BANNER
----------------------------------------------------------------
Oracle Database 10g Release 10.2.0.3.0 - 64bit Production
b、列顺序对CF的影响
--列顺序指索引列值顺序与表中的列值的顺序,一致,则CF良好,不一致,CF较差。
scott@SYBO2SZ> create table t as select * from dba_objects order by object_name;
scott@SYBO2SZ> create index i_obj_name on t(object_name); -->基于object_name列创建索引
scott@SYBO2SZ> create index i_obj_id on t(object_id); -->基于object_id列创建索引
cott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','T',cascade=>true);
PL/SQL procedure successfully completed.
scott@SYBO2SZ> @idx_stat
Enter value for input_table_name: T
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------- ---------- ---------- ------------- ------------- ---------- ----------------- ---------- ----------
1 I_OBJ_NAME 241 29476 1 1 675 20130418 17:00:42 695 48931
1 I_OBJ_ID 108 48931 1 1 24887 20130418 17:06:10 695 48931
--从上面的查询可以看出,索引I_OBJ_NAME的聚簇因子小于表上的块数,一个良好的CF值,因为object_name列是有序插入的。
--而索引I_OBJ_ID上的CF接近于表上行数的一半,说明该索引上的CF值不是很理想,因为object_id在插入到table时是无序的。
--从上可知,一个表只能有一种有序的方式来组织数据。因此对于多出一个索引的表,且顺序按照非插入时的顺序时,则其他索引上的聚簇因子很难获得理想的值。
c、组合索引对CF的影响
--对于组合索引,列的顺序影响聚簇因子的大小
--我们创建如下组合索引
scott@SYBO2SZ> create index i_obj_name_id on t (object_name, object_id);
scott@SYBO2SZ> create index i_obj_id_name on t (object_id, object_name);
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','T',cascade=>true)
PL/SQL procedure successfully completed.
scott@SYBO2SZ> @idx_stat
Enter value for input_table_name: T
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ---------------- ---------- ---------- ------------- ------------- ---------- ----------------- ---------- ----------
1 I_OBJ_NAME 241 29476 1 1 675 20130418 17:17:17 695 48931
1 I_OBJ_ID 108 48931 1 1 24887 20130418 17:17:17 695 48931
1 I_OBJ_NAME_ID 274 48931 1 1 945 20130418 17:17:17 695 48931
1 I_OBJ_ID_NAME 274 48931 1 1 24887 20130418 17:17:18 695 48931
--从上面的结果可知,
--新创建的组合索引,I_OBJ_NAME_ID(object_name, object_id),object_name是前导列,因此CF值尽管比单列是大,依然表现良好。
--而索引I_OBJ_ID_NAME(object_id, object_name),object_id作为前导列,CF值与单列索引I_OBJ_ID相同。
--上面的四个索引来看,无论是单列还是符合索引,当索引列(leaf)的顺序接近于表上行的顺序,CF表现良好。
d、反向索引对CF的影响
--反转索引主要是重新分布索引值,也就是将相连比较紧密地索引键值分散到不同或相距比较远的快上以避免竞争。
--下面基于表t来新创建表t2
scott@SYBO2SZ> create table t2 nologging as select * from t;
scott@SYBO2SZ> create index i_obj_name_reverse on t2(object_name) reverse; -->创建反向索引
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','T2',cascade=>true)
PL/SQL procedure successfully completed.
scott@SYBO2SZ> @idx_stat
Enter value for input_table_name: T2
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------------ ---------- ---------- ------------- ------------- ---------- ----------------- ---------- ----------
1 I_OBJ_NAME_REVERSE 241 29476 1 1 28104 20130418 17:22:49 695 48931
--上面创建的反向索引的CF较之前的都要大,因索引键上的值是反向的,也就是说是无序的。
--在段空间管理基于手动管理的方式下,如果使用freelist可以避免段操作上DML的竞争,但索引列上将具有较比较糟糕的聚簇因子(演示省略)
8、实战聚簇因子随DML变化的情形
a、创建演示环境
scott@SYBO2SZ> @cr_big_tb 1000000 -->创建一张百万记录的表
Table created.
scott@SYBO2SZ> @idx_stat -->查看表与索引相关信息(CF为14489,TB_BLKS为14652)
Enter value for input_table_name: BIG_TABLE
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 2088 1000000 1 1 14489 20130422 12:27:43 14652 999712
b、模拟DML操作
--创建一个临时表来存储将要从表big_table删除的记录
scott@SYBO2SZ> create table big_table_tmp nologging as select * from big_table where id>=10000 and id<=200000;
scott@SYBO2SZ> delete from big_table nologging where id>=10000 and id<=200000; -->从表big_table删除一些记录
scott@SYBO2SZ> commit;
-->查看表与索引相关信息(从下面的查询结果可知,删除记录并不使得CF发生变化)
scott@SYBO2SZ> @idx_stat
Enter value for input_table_name: BIG_TABLE
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- -------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 2088 1000000 1 1 14489 20130422 12:27:43 14652 999712
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','BIG_TABLE',cascade=>true); -->收集统计信息
scott@SYBO2SZ> @idx_stat -->查看表与索引相关信息(在收集统计信息后,删除记录后CF为11732,TB_BLKS依然为14652)
Enter value for input_table_name: BIG_TABLE --(TB_BLKS块数未发生变化是因为空闲空间没有释放,需要shrink)
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 1692 809999 1 1 11732 20130422 12:31:45 14652 808497
-->接下来将删除的数据插入到big_table以模拟表上新增数据,分两次插入,以使得id变得无序
scott@SYBO2SZ> insert into big_table nologging select * from big_table_tmp where id>=150000 and id<=200000
2 order by object_name;
scott@SYBO2SZ> insert into big_table nologging select * from big_table_tmp where id>=10000 and id<150000
2 order by object_name;
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','BIG_TABLE',cascade=>true); -->收集统计信息
scott@SYBO2SZ> @idx_stat -->查看表与索引相关信息(此时CF的值由原来的14489增大到114256,呈数量级变化)
Enter value for input_table_name: BIG_TABLE
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 2088 1000000 1 1 114256 20130422 12:33:31 14652 998513
--下面尝试move table是否对CF有向影响
scott@SYBO2SZ> alter table big_table move;
scott@SYBO2SZ> @idx_stat -->查看表与索引相关信息(move table之后,无任何变化)
Enter value for input_table_name: BIG_TABLE
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- -------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 2088 1000000 1 1 114256 20130422 12:33:31 14652 998513
-->尝试收集统计信息后,在看CF的变化
-->下面的错误表明,move之后,索引失效
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','BIG_TABLE',cascade=>true);
BEGIN dbms_stats.gather_table_stats('SCOTT','BIG_TABLE',cascade=>true); END;
*
ERROR at line 1:
ORA-20000: index "SCOTT"."BIG_TABLE_PK" or partition of such index is in unusable state
ORA-06512: at "SYS.DBMS_STATS", line 13182
ORA-06512: at "SYS.DBMS_STATS", line 13202
ORA-06512: at line 1
scott@SYBO2SZ> alter index big_table_pk rebuild nologging; ---->重建索引
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','BIG_TABLE',cascade=>true); -->再次收集统计信息
PL/SQL procedure successfully completed.
scott@SYBO2SZ> @idx_stat -->重建索引后,CF的值反而增大了
Enter value for input_table_name: BIG_TABLE
Enter value for owner: SCOTT
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_PK 2088 1000000 1 1 118384 20130422 12:36:31 14649 999427
c、重建big_table
-->下面通过重建big_table来缩小CF的值,新的表名为big_table_tmp
scott@SYBO2SZ> drop table big_table_tmp purge; --->删除之前的临时表
scott@SYBO2SZ> create table big_table_tmp nologging as select * from big_table order by id;
scott@SYBO2SZ> create unique index big_table_tmp_pk on big_table_tmp(id);
scott@SYBO2SZ> alter table big_table_tmp add constraint big_table_tmp_pk primary key(id) using index big_table_tmp_pk;
scott@SYBO2SZ> exec dbms_stats.gather_table_stats('SCOTT','BIG_TABLE_TMP',cascade=>true);
scott@SYBO2SZ> @idx_stat --->表big_table_tmp上的CF值(14486)小于原始的CF值(14489)
Enter value for input_table_name: big_table_tmp
Enter value for owner: scott
AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- ---------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
2 BIG_TABLE_TMP_PK 2088 1000000 1 1 14486 20130422 12:38:37 14649 995891
d、比较不同的CF对查询性能的影响
-->下面来基于表big_table与big_table_tmp来比较一下不同的CF对查询的影响
scott@SYBO2SZ> set autot trace;
scott@SYBO2SZ> select * from big_table where id between 10000 and 15000;
5001 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3747652938
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5001 | 478K| 606 (0)| 00:00:08 |
| 1 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE | 5001 | 478K| 606 (0)| 00:00:08 |
|* 2 | INDEX RANGE SCAN | BIG_TABLE_PK | 5001 | | 13 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=10000 AND "ID"<=15000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
2993 consistent gets
531 physical reads
116 redo size
287976 bytes sent via SQL*Net to client
4155 bytes received via SQL*Net from client
335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
5001 rows processed
--原始表上的查询的cost为606, consistent gets与physical reads分别为2993,531
scott@SYBO2SZ> select * from big_table_tmp where id between 10000 and 15000;
5001 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1127920103
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4982 | 476K| 86 (0)| 00:00:02 |
| 1 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE_TMP | 4982 | 476K| 86 (0)| 00:00:02 |
|* 2 | INDEX RANGE SCAN | BIG_TABLE_TMP_PK | 4982 | | 13 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=10000 AND "ID"<=15000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
750 consistent gets
76 physical reads
0 redo size
287976 bytes sent via SQL*Net to client
4155 bytes received via SQL*Net from client
335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
5001 rows processed
--新创建的表的cost 为86, consistent gets与physical reads分别为750,76. 呈数量级低低于原表的开销
-->可以将原始表big_table删除,然后将big_table_tmp重命名为big_table
--> alter table big_table_tmp rename to big_table; (不再演示)
-->注上面的create table as ..方式并不适合用于生产环境的真实操作,因为表上的一些属性会被忽略掉.
9、小结
a、任意情形下(堆表),表上数据的存储只能按照一种特定的顺序进行存储。
b、由上面的特性决定了表上的只有一个特定的索引列(单索引或组合索引)具有最佳的CF值。
c、索引的创建应考虑按应该按照经常频繁读取的大范围数据的读取顺序来创建索引,以保证得到最佳的CF值。
d、索引在被创建之时,基于该索引列上的CF值即被产生,但表上的DML操作后需要收集统计信息才可以更新CF的值。
e、基于表上频繁的DML操作,尤其是delete后再新增记录,可用空闲空间被填充,将使得CF的值呈增大趋势。
f、alter table move tabname并不会影响CF的值,该功能只是移动高水位线,且不释放空间。
g、重建索引对CF的值收效甚微,因为原始表数据存储顺序未发生根本变化。
h、CF的值是影响查询分析器对执行计划的评估与生成的因素之一(即是否走索引还是全表扫描,嵌套连接时哪个表为驱动表等)。
i、通过重建表或使用聚簇表来改进CF的值,建议使用原始表的ddl(重命名对象名)重建后将原表数据迁移到新表,重命名新表到原始表。
j、不推荐使用create table as select(CTAS),因为表上的一些特性会被忽略。具体参考: 当心 CREATE TABLE AS http://www.linuxidc.com/Linux/2013-04/83453.htm
--本篇文章转自:http://www.linuxidc.com/Linux/2013-04/83452.htm