
大象起舞,天下太平,极客们应该知道我们的重量级人物Hadoop登场了。
提到Hadoop, 正所谓饮水思源,我们不得不提及一下Hadoop之父,其对技术界的影响,在近10年可谓重大, 他就是Doug Cutting, 其传奇人生及其大作这里不赘述了,大家可以Google/Bing一下,之后或许我们会推出一些技术大牛的介绍以及好书推荐。
值得提及的是Hadoop之所以诞生于2005-2006之际,是Doug当时受到来自
Google Lab公开发布的几篇paper启发,包括Map/Reduce(2004), Google
File System(GFS)-2003,Doug于2006年加入Yahoo, 在Yahoo的慧眼及大力推动下,山寨出身的Hadoop的运势如日中天。
老样子,Hadoop官网介绍,Hadoop是一个开源框架,适合运行在通用硬件,支持用简单程序模型分布式处理跨集群大数据集,支持从单一服务器到上千服务器的水平scale up。BTW, Hadoop的官网真是无法形容,毫无美感,文字堆砌,与后来的Docker, Spark等无法相提并论。毕竟这是一个颜值时代。
上架构图:
Hadoop 1.x架构刚开始比较简单,只有2个大的模块MapReduce和
HDFS, 其中MapReduce不单包含了分布式计算,还有集群资源管理,HDFS是Hadoop的核心分布式文件系统,提供了分布式高吞吐文件系统管理。
在后续的Hadoop 2.x版本中(目前稳定版本为2.7.x),
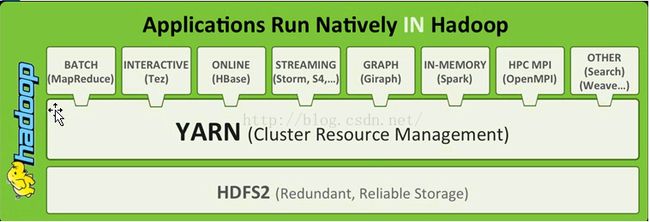
架构做了大幅改进,支持MapReduce批处理, Tez交互式,以及抽象独立的YARN负责job scheduling和集群资源管理,还有HDFS2,还有上图没有体现的
Common模块包含了一些公共功能,如安全认证以及支持其它模块基础功能。 同时,开放接口支持Online HBase, Streaming, In-Memory Spark等。
值得一提的是, 关于HDFS2,借鉴吸取了后起之秀Spark的计算模型,正所谓
“移动计算比移动数据更划算”, 之RDD之精髓。
好吧,先来介绍HDFS架构图:
HDFS毫无疑问的采用了master/slave架构, 一个HDFS集群是由一个NameNode和多个DataNodes组成。NameNode是一个中心服务器,负责管理文件系统的名字空间namespace以及客户端对文件的访问。DataNode一般是一个节点一个,负责管理它所在节点的存储。一个文件根据大小被拆分成一个或多个数据块,这些数据块存储在一组DataNode上,NameNode执行文件系统的操作,如打开,关闭,重命名等,同时也负责确定数据块到具体datanodes节点的映射。
datanode负责处理文件系统客户端的读写请求,在namenode的统一调度下进行数据的处理,如创建,删除,复制等。集群中单一的namenode结构大大简化了系统架构,namenode统一管理hdfs原数据,用户数据永远不会存放于
namenode。所有的hdfs通讯协议建立在tcp/ip之上。其中,client是向
namenode发起文件读写请求的,namenode再根据配置返回给client相应的
datanode信息。一个block默认配置会有3分备份。
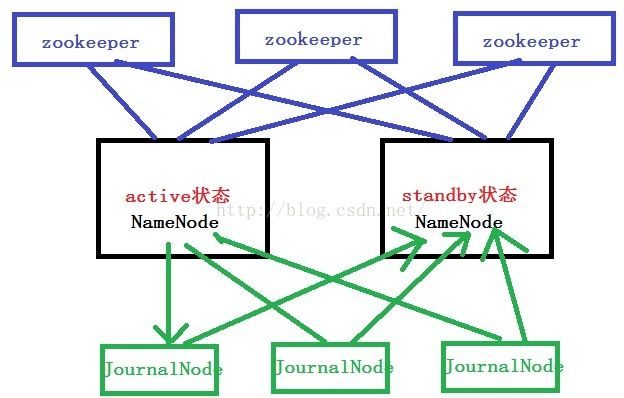
细心的读者可能会发现,namenode是万能的,高效的,中央集权的。却隐隐存在巨大的单点故障风险,如果namenode出现故障,那整个hdfs都无法运作了,即非HA.
Hadoop 2.x后引入了HDFS2, 包含了2个namenode(目前支持2个),一个处于active状态,一个处于standby状态。当active出现问题时就自动切换,如何自动切换就借用了我们上一篇提到的zookeeper了,集群中的两个
namenode都在zookeeper中注册,zk负责监测namenode状态以及自动切换。说白了就是又引入一层来管理,计算机以及程序里的抽象与问题解决大多是引入新的一层或者角色来做到的。
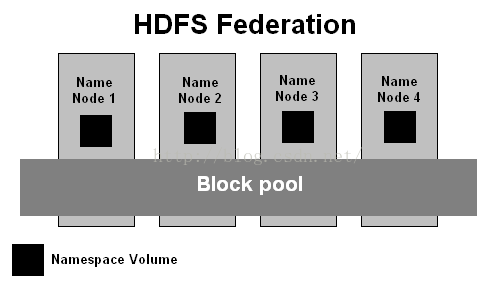
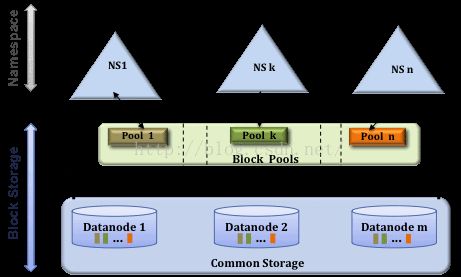
另外读者可能也会注意到的是namenode是核心节点,维护着整个hdfs的元数据信息,但其容量是有限的,当namenode所在服务器内存无法装载后,整个hdfs集群就受制于他,这可无法支撑sale up成千上完的集群大数据。其解决办法为引入了hdfs Federation,即有多个hdfs集群。一个总集群中,可以虚拟出多个单独小集群,各个小集群间数据可以实时共享。
上图:
好了,hdfs到此,我们继续介绍第二个核心模块mapreduce。下图以著名的
wordcount为例,介绍m/r整体结构:
mr编程框架原理,利用一个输入的key-value对集合来产生一个输出的
key-value对集合。mr库通过map(映射)和reduce(化简)两个函数来实现,说到底其核心思想也就是我们大学学的数据结构中的分而治之算法吧。用户自定义的map函数接受一个输入key-value对,然后产生一个中间的key-value对的集合,mr把所有具有相同key值的value结合在一起,然后传递给reduce函数,reduce接受合并这些value值,形成一个较小的value 集合,reduce函数具备了在集群上大规模分布式数据处理的能力。与传统的分布式计算设计相比,mapreduce封装了并行处理,容错处理,本地化计算,负载均衡等细节。
上图中,reduce又包含了3个主要阶段,shuffle,sort和reduce。这里有必要提及一下shuffle:
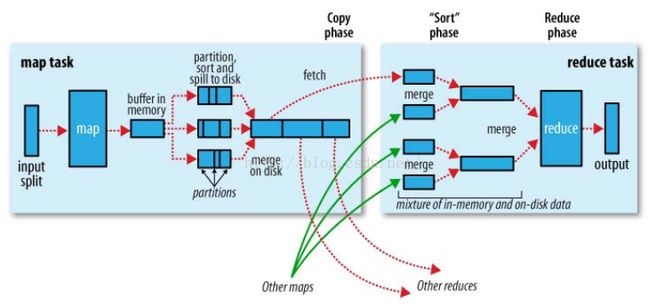
shuffle操作就是针对多个map任务的输出按照不同的分区partition通过网络复制到不同的reduce任务节点上,这整个过程叫做shuffle。
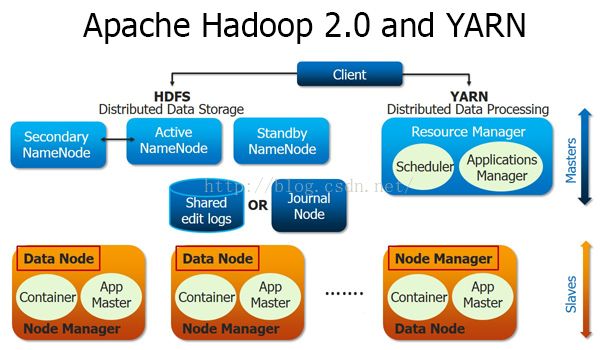
继续介绍第三大核心YRAN:
整体架构中的yran
继续抽象:
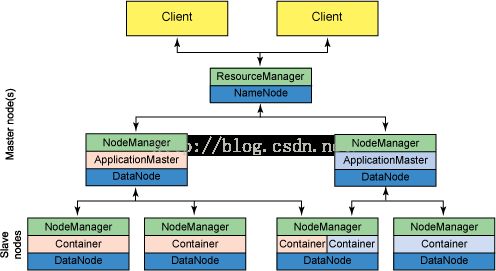
YARN的内部细节架构:
YARN分层结构的本质是ResourceManager。它控制整个集群并管理应用程序向基础计算资源分配。ResourceManager将各个资源部份(计算,内存,带宽等)安排给基础nodemanager(YARN的每节点代理)。ResourceManger还与ApplicationMaster一起分配资源,与NodeManager一起监控基础应用。在上下文,承担了以前的TaskTracker的一些角色,ResourceManager承担了
JobTracker的角色。Hadoop 1.x架构受到了JobTracker的高度约束,
jobtracker负责整个集群的资源管理与作业调度,新的Hadoop 2.x打破了这种模型,ResourceManager管理资源,ApplicationMaster负责作业。YARN还允许使用Message Passing Interface通信模型,执行不同编程模型,包括图形,迭代式,机器学习等计算。
好了,上代码吧,没时间写了,官网word count:

“简单”明了,无需多数,作者简单加了引号,注意这段经典代码后来被Spark用来作为案例,几句就搞定了。
最后,我们来看一下Hadoop的生态系统:
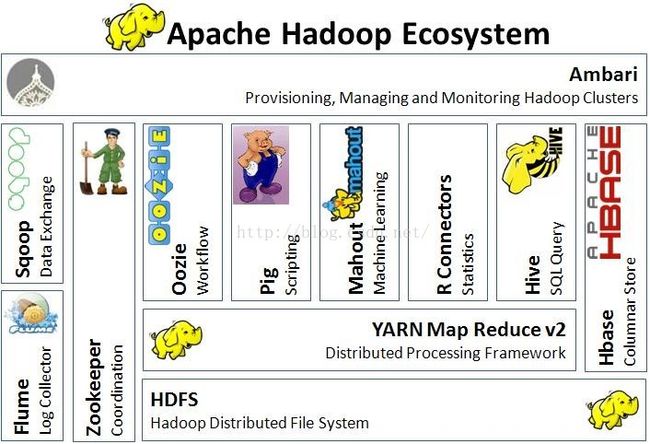
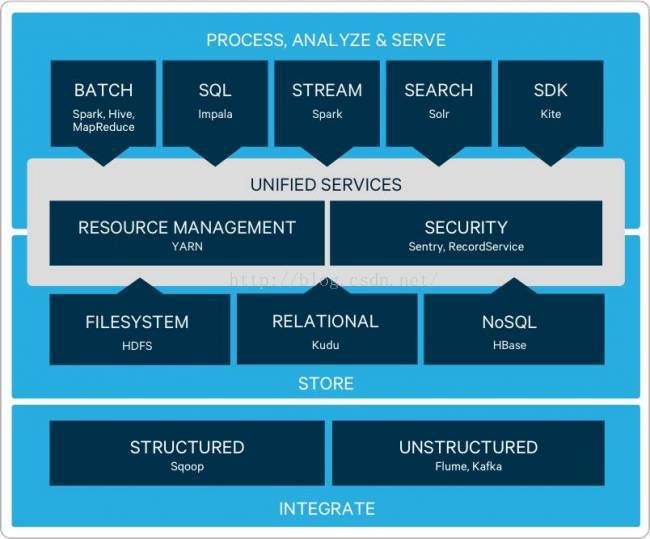
Hadoop v2.x生态系统如日中天,百家争鸣。这里仅仅抛个引子。
好了,本文仅作为Hadoop的项目介绍就到此了,相信群里有很多Hadoop大牛技术专家,各位不灵赐教。
@erixhao
公众号: 技术极客TechBooster