Apache顶级项目介绍7 - HBase
今天我们来继续介绍Apache顶级项目大数据三巨头之一的HBase。恰逢今天(5.24)是HBase Con2016旧金山盛会,比较应景,而且还有朋友@Luke Han去演讲Kylin。
1. 官网简介:
老样子,HBase官网的介绍, "HBase is the Hadoop database, a distributed, scalable, big data store.",所以HBase = Hadoop Database,并且提供了分布式可扩展的数据存储。(HBase的官网直接差评,像API文档,唯一亮点是有部分中文文档)
我们之前的系列提到过,HBase是源自2006年OSDI的Google论文BigTable,
Chad Walters和Jim受其启发于2007年即实现了HBase. 类似Google BigTable使用GFS作为文件存储系统,HBase利用Hadoop的HDFS作为其文件系统;Google用MapReduce来处理bigtable中的海量数据,HBase用Hadoopd的MapReduce来处理;同样Google使用Chubby作为协同服务,HBase采用Zookeeper。大家是不是感慨山寨的威力啊?就差Made in China?
2. HBase功能及作用
HBase有什么功能作用呢?同样我们回顾一下当年Google为什么会研发BigTable吧。Google当年面临一个大的挑战,如何能实时搜索互联网内容?它的方案是需要把互联网内容缓存,并基于海量的缓存上提供快速实时查询。所以有了:
-
GFS : 解决分布式,可扩展的文件存储系统。
-
BigTable: 分布式存储,管理PB级别结构化数据并提供实时查询。
-
MapReduce: 处理分布式计算。
好吧官网给出如下建议,HBase作为大型分布式数据库,更像是一个Data Store多于Data Base。却少很多RDBMS重要特性如列类型,触发器,高级查询语言,高级事务等。请确信有足够数据,如达上亿或者上千亿行以上数据,或者上百万列;如果只有几百万行则RDBMS更加。
另外HBase是一个面向列的数据库。大概解释一些列式数据库吧。
行式数据库把一行中所有数据串在一起存储;Row-based storages stores a table in a sequence of rows. 列式则把一列数据串在一起存储,如我们熟悉的Sybase IQ;
上图:
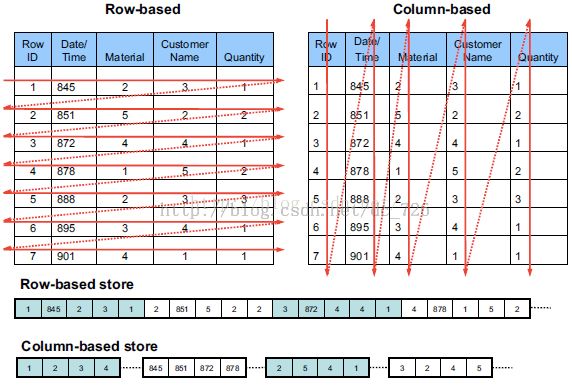
这样查询中选择的列就自动索引了;如果查询部分字段会大大减少读取数据量,并且可以做到高压缩算法( 5- 20 倍)存储列,对于null的列并不占用存储空间,所以表可以设计的非常稀疏。 当然有利有弊,其弊端带来是insert/update较麻烦。
3. HBase数据结构
HBase介于Map Entry(Key/Value)与DB Row, 更类似Memcache。我们由微观到宏观慢慢讲解。
HBase最底层数据结构是一个四维数据模型包含如下图结构:
ROWKEY: 行键,主键;行键是保证速度的核心。下面会重点介绍。
Column Family: 列族,数据在行中按照列族来组织,每行列族必须相同,但行之间相同列族不需要要有相同列修饰符。如:prod:name, prod:type都是prod列族。
列修饰符:定义在列族中的真实列,称之为列修饰符,如prod:name;
版本:每列都有可配置版本数量,默认3.
在HBase访问数据行主要通过1. ROWKEY 2. ROWKEY Range 3. Full Scan.
举个例子吧:
ROWKEY是HBase设计的关键核心,记得有位阿里大牛在讲解中提到了部分阿里设计行键秘籍。行键最大长度64k,保存为字节数组。存储时数据按照rowkey字典排序存储,所以设计key要把经常一起读取的行存储放到一起,如域名反向。官网特地提到一点,在Tom While书籍The Definitive Guide中描述,一个集群中,一个导入数据进程没有反应,client都在等一个region节点,过一会后变成下一个region... 其本质原因是使用了单调递增或者时序key就会造成此问题。使用了顺序的key会讲本没有顺序的数据变得有序,从而导致把负载压到一台机器,所以要尽量避免时间戳或者1,2,3等这样的key。换言之,行键要有足够差异性使之分布。如果需要按照时间顺序导入hbase,可以参考OpenTSDB有独特解决方案。值得注意的是,行键不可以改变,只有删除重新插入。
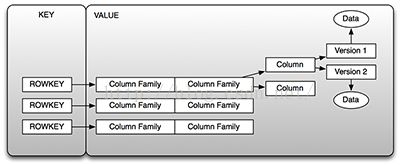
Cell: {rowkey, column(family, lable), version}唯一确定一个单元。
HBase在行上水平划分成n个Region, 每个表开始只有一个region,随着数据的膨胀自动分裂为两个,多个,不同region分布在不同Server上,但同一个不会拆分到多个server。Region按照列族分为Store存储单元。每个store包含了内存中的memstore和持久化HFile, 用来保存一个column family.
HFile又细分为以下几个部分:
data block保存数据, meta保存用户定义kv对,可压缩;其他为一些元信息或者索引;其中Trailer是定长的,保存每一段的偏移量,保存了每个段的起始位置,所以检索某个key不需要扫描全部hfile,而只需找到key所在block。
实际上图是老版本v1的状况,由于其性能占用内存较多,后续推出了v2,v3
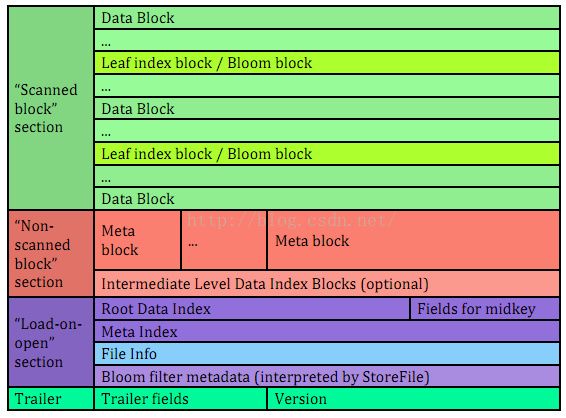
v2/v3具体格式,为了加速查询,不要读取整个hfile,引入了多层的类B+树索引;每个block都有自己的leaf-index;
4. 系统架构
好吧,我们来点宏观的大局观吧,俯看一下整个HBase的整体架构:
注:这里有参考大作 “An In-Depth Look At The HBase Architecture”.
HBase毫无意外的采用了Master/Slave架构搭建集群,包括了HMaster, HReginServer, ZooKeeper等。
Client: 可以看出,客户端有两种方式交互访问。其一通过zk访问HMaster主要进行一些DDL操作;其二通过zk获取root表位置,再通过HBase的RPC机制与HRegionServer直接通信进行数据读写操作。(通过zk从HMaster获取元数据,找到对应rowkey所在HRegionServer/HRegion)
HMaster: 作为核心管理HReginServer, 提供负载均衡。管理分配HRegion, 实现DDL操作, 管理table元数据以及权限ACL。HBase可以启动多个HMaster, 通过zk的election机制保证有且只有一个HMaster运行,从而解决单点问题。
HRegionServer: 存放管理HRegion(1000+), HFile; 读写HDFS, 管理table;与client交互读写数据。如上所述。
Zookeeper: 主要用于集群协调;综上其实也可以看出zk存储了重要的元数据如root表地址;存储了HMaster地址;存储了HRegionServer状态;并实现
HMaster主从节点failover,如下图:
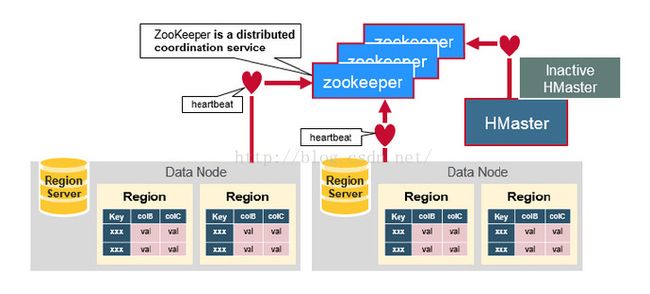
zk一般由奇数,如3台机器组成;内部使用paxos算法;
HRegion: 如上文所述,随着数据的膨胀,HBase使用rowkey将table切分成多个HRegion, 每个HRegion纪录了startKey, endKey;
5. 数据操作
启动单机模式HBase:

启动伪式模式HBase: 先启动Hadoop, 再启动HBase

CRUD => Get, Put, Scan & Delete.
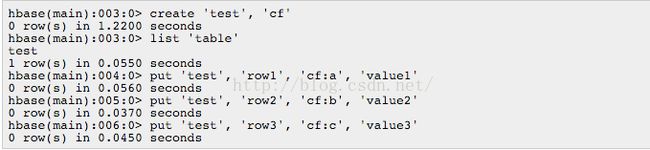


Get: 返回特定行的属性。
Put: 向表增加新行(key不存在),否则如果key存在则更新行, 注意要保持row,column和version完全一致才会覆盖一个cell。htable支持batch
Scan : 多行特定属性迭代Delete:删除一行。
JOIN: JOIN ? 开玩笑,HBase当然不支持join。
Create Schema: shema必须先创建,设计schema可以参考OpenTSDB.
分布式模式配置:
HBase配置与hadoop生态圈完全兼容,/conf下面主要配置文件包含 hbase-site.xml; regionservers; hbase-env.sh
hbase-site.xml
主要配置zk集群,端口,数据保存路径;以及设置是否为分布式模式。
6. 业界使用
互联网搜索Google:
通常互联网或者当年google是这么实用hbase的:
1> 爬虫持续不断抓去全球页面,这些页面存储到BigTable -> HBase中
2> 进行mapreduce计算,生成索引,为搜索预处理。
信息交换Facebook:
Facebook实际上是HBase幕后很大的推手,极大的推动了hbase的发展,并积极贡献开源代码。甚至有人经常认为hbase是facebook贡献的。
Facebook所有用户的读写信息/消息都保存在hbase里,可想而知要支持这种处理当然需要高吞吐,海量大表,自动分库了。hbase在2012年就达到每天交换十亿条数据,750亿次操作。尖峰时刻,每秒150万次操作。每月增加250tb数据。
阿里淘宝应用:
淘宝是国内较早使用hbase的公司。主要包括索引,交易同步,全网监控,日志,历史数据。知道为什么你在淘宝实时查询,或者查询你的订单飞快?都有hbase的功劳啊。阿里甚至较早的参与了hbase的版本开发,如replicaiton方案,并借鉴了很多facebook的宝贵经验少走了很多弯路。
上一张几周前3万英尺上玩HBase的照片吧:

好了,我们到此告一段落,同样入门级别,抛砖引玉。
最后恰逢HBase Conf2016旧金山盛会。
其中很多Speaker来自Google, Yahoo, Facebook, Cloudera, Airbnb, 国内则有阿里,小米,Kyligence.
公众号:技术极客TechBooster