Hadoop2.2.0伪分布式搭建简述
简述了自己搭建Hadoop伪分布式的过程,方便以后查看参考。
环境:Vmware10+RedHat6.3+hadoop2.2.0+JDK1.7
Hadoop模式:
本地模式:只能其一个reduce和一个map,用于调试
伪分布式模式:通过一台机器模拟分布式,在学习时使用。验证逻辑是否正确
集群模式:工作的模式,有几百上千台机器。
linux环境配
关闭防火墙
若是对外网提供的服务是绝对不能关闭防火墙的。而Hadoop一般是公司内部使用,有多台节点,且之间需要通信,此时若防火前将通信的端口屏蔽则无法访问,故为了省事选择关闭防火墙。
修改IP:我指定Ip为:192.168.8.88
为了避免每次启动机器IP会随机变化的请框
设置hostname,这里我命名为hadoop01
为每台机器设置一个名字,若出现问题可以方便定位到机器在哪,且
主机名与ip在ETC/hosts下进行映射。
安装jdk
安装Hadoop,并测试
设置ssh自动登录,
ssh即 安全的shell
详细步骤:
步骤一: 修改虚拟机配置;
1、配置虚拟机IP

如上图,点击虚拟网络编辑器,配置host模式(这里使用主机模式)或桥接式
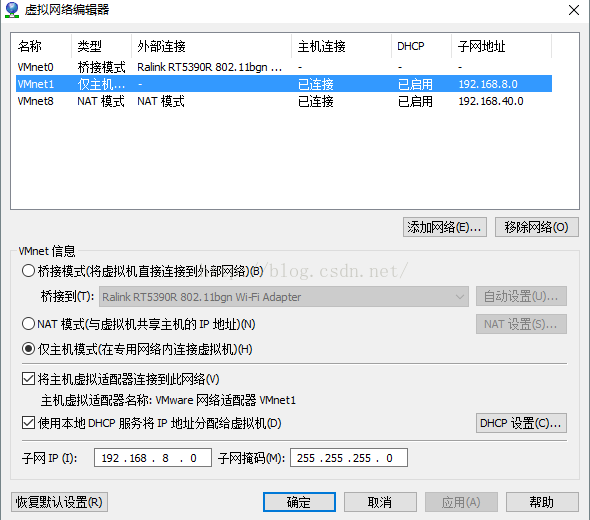
其中可以看到,host模式对应的网卡为VMnet1,配置其网段为192.168.8.0,之后进入到windows系统中更改Vmnet1的ip为固定的192.168.8.100
,接下来配置虚拟机中linux的Ip:192.168.8.88,网关:192.168.8.1,如果要上网则必须配置DNS:8.8.8.8或8.8.4.4
此外如果为方便操作,最好在虚拟机上安装VMtools,详细安装步骤CSDN上很多。这里不再赘述。
2、修改主机名: vim /etc/sysconfig/network
3、防火墙设置:service iptables,提示对防火墙操作的指令,因为防火墙也是服务且服务名为iptables
依次输入以下指令:
service iptables status:查看防火墙状态,确认当前节点防火墙是否关闭。
service iptables stop :关闭防火墙,但使用该方法关闭防火墙后,当再次重启机器后防火墙仍会启动。
因此要永久关闭防火墙,指令如下:
chkconfig iptables --list :查看几种模式下防火墙默认的开机启动状态:
如下图:

此外可以使用vim /etc/inittab查看linux默认启动方式;默认为为5即默认启动进入图形界面图形界面。关于其他模式这里不再赘述。
chkconfig iptables off ,将所有模式下的防火墙默认是否启动全部设为不自动启动。
reboot
:重启机器
重启之后验证主机名和Ip是否已经修改。(使用ifconfig命令查看Ip)
注:在进行如上配置后,有时重启机器后防火墙仍会自动开启,所以为保险起见,我一般在启动机器后都会,先执行 service iptables stop 关闭防火墙。
步骤二:安装JDK
必须使用1.6以上的,最好不用最新的,详细的Hadoop不同版本对应的JDK版本官方网站首页就有详细说明。
1、
mkdir /usr/java 创建目录
/usr/java 将下载的jdk解压到该目录下,以方便日后的管理。
2、
vim /etc/profile 文件中添加如下内容:
export JAVA_HOME=jdk安装目录(我的是:/usr/java/jdk1.7.0_79
)
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:$CLASSPATH
export PATH=$PATH:$JAVA_HOME/bin
注linux中环境变量间分割符为冒号“:”保存退出之后运行:
3、source /etc/profile 使配置文件生效,
步骤三:安装Hadoop
1、
mkdir /Hadoop在根目录下创建一个/Hadoop目录,,命令:
tar -zxvf hadoop-2.2.0.tar.gz -C /Hadoop 将下载的hadoop包解压到该目录下
解压之后的目录结构如下:
bin:存放一些可以执行的脚本,常用的有hadoop,yarn,hdfs等include:存放头文件,类似于c的标准库sbin:存放一些启动和关闭相关的脚本start-yarn.sh和stop-yarn.sh等etc:存放Hadoop的配置文件,share:Hadoop相关的jar包。
2、配置Hadoop,修改几个配置文件:
1) vim hadoop-env.sh 在文件中设置JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.7.0_79
2)修改core-site.xml文件
<configuration>
<property>
用来指定nameNode的地址
<name>fs.defaultFS</name>
<value>hdfs://192.168.8.88:9000</value>
</property>
<property>
用来指定Hadoop运行时产生的文件的存放路径
<name>hadoop.tmp.dir</name>
<value>/Hadoop/hadoop-2.2.0/tmp</value>
</property>
</configuration>
3)hdfs-site.xml文件
<configuration>
<property>
用来指定hdfs保存数据副本的数量,包含其本身,因为这里是伪分布式,故设置为1.在真正的多机的分布式中默认保存三份
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4)mapred-site.xml原本没有此文件只有mapred-site.xml.temple文件 ,故可将原有的文件mapred-site.xml.temple更名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml添加内容如下:<configuration><property> 告诉Hadoop以后mapreduce(MR)运行在yarn上<name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
5)yarn-site.xml
<configuration><property> 告诉Hadoop以后NodeManager获取数据的方式为shuffle方式<name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property> 指定yarn中ResourceManager的地址<name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property></configuration>
6)将Hadoop添加到环境变量:/etc/profile。方便以后的对hadoop指令的使用
vim /etc/profile
添加内容:
export HADOOP_HOME=/Hadoop/hadoop-2.2.0export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新配置:
source /etc/profile
步骤四:初始化HDFS(格式化文件系统)
1】以前一直在用:
hadoop namenode -format 现在已经不用了
现在常使用:
hdfs namenode -format
看到下面这句说明格式化成功
在Hadoop目录下会出现一个tmp目录:
2】启动HDFS和yarn
运行
sbin/start-all.sh 因为当前只是一台机器上安装的伪分布式,所以一次性启动所有服务,包括HDFS和yarn,输入几次“yes”和root密码启动成功之后,
关闭时使用
sbin/stop-all.sh
注意:在hadoop2.x中推荐先调用
start-dfs.sh后调用
start-yarn.sh ,来启动任务
3】输入:
jps查看显示当前Hadoop进程信息:如果显示如下则表示之前的额配置成功了:
注jps是java的命令(使用which jps查看jps脚本所在目录 )
上面指令执行后若Hadoop正常开启,会显示一下进程
NameNode:HDFS中负责管理DataNodes的,HDFS部门中的老大
DataNode:HDFS中负责数据存储的节点,HDFS部门中的小弟。
SecondaryNameNode:相当于nameNode的助理,帮助NameNode完成数据同步工作
ResourceManager:资源管理器,YARN部门中的老大。
NodeManager:YARN部门中的小弟,确切的说是小组长,他手下还有干活的小弟
4】当然,也可以使用使用浏览器登陆验证:注:我安装Hadoop的linux的为;192.168.8.88,主机名为hadoop01。故根据自身情况修改
http://192.168.8.88:50070(hdfs管理界面)
http://192.168.8.88:8088(Mr管理界面)
注:登陆http://192.168.8.88:50070后可以看到

点击live Node进入当前活动节点的界面:

但是点击
Browse the filesystem后无法正常显示,且地址栏内容显示为:
http://hadoop01:50075/browseDirectory.jsp?namenodeInfoPort=50070&dir=/&nnaddr=192.168.8.88:9000
即主机是以主机名的方式
hadoop01显示而非IP地址,因此需要修改windows系统中的C:/windows/system32/drivers/etc/hosts文件将主机名
hadoop01配置到文件中 此时刷新网页显示如下:
空的目录,说明当前里面什么都没有。
第五步:验证HDFS;
上传文件:Hadoop fs -put linux文件系统上文件 Hadoop的HDFS文件系统上,将
/root/test.txt传到hdfs://hadoop01:9000/HDFSTest文件夹下:
hadoop fs -put /root/test.txt hdfs://hadoop01:9000/HDFSTest
运行成功后刷新浏览器页面显示:

当然上传到HDFS上的文件也是可以通过浏览器下载的
通过命名行下载:hadoop fs -get hdfs://hadoop01:9000/HDFSTest /home/HDFSTest
第六步:测试MapReduce和YARN
在Hadoop安装目录中的share目录下,存放有jar包,找到mapreduce的jar包,其中有许多测试案例,使用jar包中提供的
wordcount方法,需要传入一个文件,将结果输出到某个文件中。
hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount /in.txt /out,txt
/in.txt:HDFS上的输入的将被测试的文件
/out.txt:HDFS上的存放输出结果的文件
in.txt文件中内容参考如下:
hello tomhello jokhello jonyhello tom
经过计算,会统计每个单词出现的次数,并将结果保存在out.txt中
第七步:SSH免登录
如上,之前开启hadoop时多次输入yes和root密码很麻烦,而且这仅仅只是一台机器,若为成百上千台机器时,那将会是一个巨大的工作量。下面我们来设置,SSh免密码登陆,1】情况一: 使用ssh登陆本身系统时要求输入密码。例如:ssh hadoop01 。hadoop01为当前机器的名字,当然也可直接使用Ip地址情况二:当前虚拟机节点(192.168.8.88 )向192,168.8.99的机器发送一个命令,使192,168.8.99机器在根目录下创建一个文件ssh 192.168.8.99 mkdir /test ,此时会让输入8.99的密码。至此可以看出来为了安全当使用ssh协议连接其他机器时,必须输入对方系统的密码,即使是使用ssh连接自己本身也需要密码。2】对于情况一,即实现自身节点的SSH免登陆配置1) cd ~/.ssh :进入到~目录下有一个.ssh的目录: 其中只有一个known_hosts文件2) ssh-keygen -t rsa 生成秘钥,四个回车,之后会在~/.ssh目录下会生成两个文件 一个公钥(id_rsa.pub),一个私钥(id_rsa),其中为一堆字符串。要实现登陆本系统不需要输入密码需要将公钥传给自己系统已认证的钥匙中(即放到authorized_keys 中 ),实现免登陆自己。cp id_rsa.pub ~/.ssh/authorized_keys 此时~/.ssh目录下会生成authorized_keys文件,ssh hadoop01 ;现在再次使用ssh登陆本身系统将不用输密码:且此时在使用 sbin/start-all.sh 启动hadoop将不再要求输入密码,可以直接启动。3)对于情况二:实现对其他节点的SSH免登陆;只需将当前节点上的公钥的内容拷贝到想免登陆的机器上
ssh-copy-id hadoop02 (将我当前的公钥发送给hadoop02,因为我想免登陆到hadoop02)
例如:192.168.8.88免密码登陆到192.168.8.99 ,将192.168.8.88的公钥拷给192.168.8.99,注意这里是谁将自身公钥拷给谁。此时在192.168.8.88上运行如下指令:ssh-copy-id 192.168.8.99 ,192.168.8.88将自己的公钥给对方(192.168.8.99), 第一次发送时需要输入对方的密码,之后就可以免登陆到对方(192.168.8.99)系统。总结:
1)现在自己机器上生成一个公钥和一个私钥,ssh-keygen -t rsa2)将自己的公钥发送给想要登陆的机器,ssh-copy-id 目标节点的Ip或主机名原理如下图:
