Java之IO操作总结
所谓IO,也就是Input与Output的缩写。在java中,IO涉及的范围比较大,这里主要讨论针对文件内容的读写
其他知识点将放置后续章节
对于文件内容的操作主要分为两大类
分别是:
- 字符流
- 字节流
其中,字符流有两个抽象类:Writer Reader
其对应子类FileWriter和FileReader可实现文件的读写操作
BufferedWriter和BufferedReader能够提供缓冲区功能,用以提高效率
同样,字节流也有两个抽象类:InputStream OutputStream
其对应子类有FileInputStream和FileOutputStream实现文件读写
BufferedInputStream和BufferedOutputStream提供缓冲区功能
概念:
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节, 操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是 音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点.
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 2. 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
转换:
在从字节流转化为字符流时,实际上就是byte[]转化为String时,
public String(byte bytes[], String charsetName)
有一个关键的参数字符集编码,通常我们都省略了,那系统就用操作系统的lang
而在字符流转化为字节流时,实际上是String转化为byte[]时,
byte[] String.getBytes(String charsetName)
也是一样的道理
参考链接
字节流与字符流的区别 - hintcnuie - ITeye技术网站
俺当初学IO的时候犯了不少迷糊,网上有些代码也无法通过编译,甚至风格都很大不同,所以新手请注意:
1.本文代码较长,不该省略的都没省略,主要是因为作为一个新手需要养成良好的代码编写习惯
2.本文在linux下编译,类似于File.pathSeparator和File.separator这种表示方法是出于跨平台性和健壮性考虑
3.代码中有些操作有多种执行方式,我采用了方式1…方式2…的表述,只需轻轻解开注释便可编译
4.代码中并没有在主方法上抛出异常,而是分别捕捉,造成代码过长,如果仅是测试,或者不想有好的编程习惯,那你就随便抛吧……
5.功能类似的地方就没有重复写注释了,如果新手看不懂下面的代码,那肯定是上面的没有理解清楚

字符流
实例1:字符流的写入
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
//创建要操作的文件路径和名称
//其中,File.separator表示系统相关的分隔符,Linux下为:/ Windows下为:\\
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
//由于IO操作会抛出异常,因此在try语句块的外部定义FileWriter的引用
FileWriter w = null;
try {
//以path为路径创建一个新的FileWriter对象
//如果需要追加数据,而不是覆盖,则使用FileWriter(path,true)构造方法
w = new FileWriter(path);
//将字符串写入到流中,\r\n表示换行想有好的
w.write("Nerxious is a good boy\r\n");
//如果想马上看到写入效果,则需要调用w.flush()方法
w.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
//如果前面发生异常,那么是无法产生w对象的
//因此要做出判断,以免发生空指针异常
if(w != null) {
try {
//关闭流资源,需要再次捕捉异常
w.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
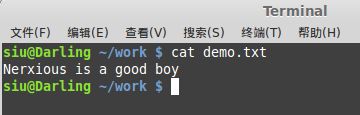
实例2:字符流的读取
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class Demo2 {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileReader r = null;
try {
r = new FileReader(path);
//方式一:读取单个字符的方式
//每读取一次,向下移动一个字符单位
int temp1 = r.read();
System.out.println((char)temp1);
int temp2 = r.read();
System.out.println((char)temp2);
//方式二:循环读取
//read()方法读到文件末尾会返回-1
/* while (true) { int temp = r.read(); if (temp == -1) { break; } System.out.print((char)temp); } */
//方式三:循环读取的简化操作
//单个字符读取,当temp不等于-1的时候打印字符
/*int temp = 0; while ((temp = r.read()) != -1) { System.out.print((char)temp); } */
//方式四:读入到字符数组
/* char[] buf = new char[1024]; int temp = r.read(buf); //将数组转化为字符串打印,后面参数的意思是 //如果字符数组未满,转化成字符串打印后尾部也许会出现其他字符 //因此,读取的字符有多少个,就转化多少为字符串 System.out.println(new String(buf,0,temp)); */
//方式五:读入到字符数组的优化
//由于有时候文件太大,无法确定需要定义的数组大小
//因此一般定义数组长度为1024,采用循环的方式读入
/* char[] buf = new char[1024]; int temp = 0; while((temp = r.read(buf)) != -1) { System.out.print(new String(buf,0,temp)); } */
} catch (IOException e) {
e.printStackTrace();
} finally {
if(r != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}实例3:文本文件的复制
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String doc = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "lrc.txt";
FileReader r = null;
FileWriter w = null;
try {
r = new FileReader(doc);
w = new FileWriter(copy);
//方式一:单个字符写入
int temp = 0;
while((temp = r.read()) != -1) {
w.write(temp);
}
//方式二:字符数组方式写入
/* char[] buf = new char[1024]; int temp = 0; while ((temp = r.read(buf)) != -1) { w.write(new String(buf,0,temp)); } */
} catch (IOException e) {
e.printStackTrace();
} finally {
//分别判断是否空指针引用,然后关闭流
if(r != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(w != null) {
try {
w.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}实例4:利用字符流的缓冲区来进行文本文件的复制
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String doc = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "lrc.txt";
FileReader r = null;
FileWriter w = null;
//创建缓冲区的引用
BufferedReader br = null;
BufferedWriter bw = null;
try {
r = new FileReader(doc);
w = new FileWriter(copy);
//创建缓冲区对象
//将需要提高效率的FileReader和FileWriter对象放入其构造函数内
//当然,也可以使用匿名对象的方式 br = new BufferedReader(new FileReader(doc));
br = new BufferedReader(r);
bw = new BufferedWriter(w);
String line = null;
//读取行,直到返回null
//readLine()方法只返回换行符之前的数据
while((line = br.readLine()) != null) {
//使用BufferWriter对象的写入方法
bw.write(line);
//写完文件内容之后换行
//newLine()方法依据平台而定
//windows下的换行是\r\n
//Linux下则是\n
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//此处不再需要捕捉FileReader和FileWriter对象的异常
//关闭缓冲区就是关闭缓冲区中的流对象
if(br != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bw != null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}字节流
实例5:字节流的写入
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileOutputStream o = null;
try {
o = new FileOutputStream(path);
String str = "Nerxious is a good boy\r\n";
byte[] buf = str.getBytes();
//也可以直接使用o.write("String".getBytes());
//因为字符串就是一个对象,能直接调用方法
o.write(buf);
} catch (IOException e) {
e.printStackTrace();
} finally {
if(o != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}实例6:字节流的读取
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileInputStream i = null;
try {
i = new FileInputStream(path);
//方式一:单个字符读取
//需要注意的是,此处我用英文文本测试效果良好
//但中文就悲剧了,不过下面两个方法效果良好
int ch = 0;
while((ch=i.read()) != -1){
System.out.print((char)ch);
}
//方式二:数组循环读取
/* byte[] buf = new byte[1024]; int len = 0; while((len = i.read(buf)) != -1) { System.out.println(new String(buf,0,len)); } */
//方式三:标准大小的数组读取
/* //定一个一个刚好大小的数组 //available()方法返回文件的字节数 //但是,如果文件过大,内存溢出,那就悲剧了 //所以,亲们要慎用!!!上面那个方法就不错 byte[] buf = new byte[i.available()]; i.read(buf); //因为数组大小刚好,所以转换为字符串时无需在构造函数中设置起始点 System.out.println(new String(buf)); */
} catch (IOException e) {
e.printStackTrace();
} finally {
if(i != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
实例7:二进制文件的复制
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String bin = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "一个人生活.mp3";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "一个人生活.mp3";
FileInputStream i = null;
FileOutputStream o = null;
try {
i = new FileInputStream(bin);
o = new FileOutputStream(copy);
//循环的方式读入写出文件,从而完成复制
byte[] buf = new byte[1024];
int temp = 0;
while((temp = i.read(buf)) != -1) {
o.write(buf, 0, temp);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(i != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(o != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
实例8:利用字节流的缓冲区进行二进制文件的复制
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String bin = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "一个人生活.mp3";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "一个人生活.mp3";
FileInputStream i = null;
FileOutputStream o = null;
BufferedInputStream bi = null;
BufferedOutputStream bo = null;
try {
i = new FileInputStream(bin);
o = new FileOutputStream(copy);
bi = new BufferedInputStream(i);
bo = new BufferedOutputStream(o);
byte[] buf = new byte[1024];
int temp = 0;
while((temp = bi.read(buf)) != -1) {
bo.write(buf,0,temp);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(bi != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bo != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
初学者在学会使用字符流和字节流之后未免会产生疑问:什么时候该使用字符流,什么时候又该使用字节流呢?
其实仔细想想就应该知道,所谓字符流,肯定是用于操作类似文本文件或者带有字符文件的场合比较多
而字节流则是操作那些无法直接获取文本信息的二进制文件,比如图片,mp3,视频文件等
说白了在硬盘上都是以字节存储的,只不过字符流在操作文本上面更方便一点而已
此外,为什么要利用缓冲区呢?
我们知道,像迅雷等下载软件都有个缓存的功能,硬盘本身也有缓冲区
试想一下,如果一有数据,不论大小就开始读写,势必会给硬盘造成很大负担,它会感觉很不爽
人不也一样,一顿饭不让你一次吃完,每分钟喂一勺,你怎么想?
因此,采用缓冲区能够在读写大文件的时候有效提高效率
最后解决的一个问题是字节流和字符流的转化,使用的是InputStreamReader和OutputStreamWriter,它们本身属于的是reader和writer字符流,我们之所以会用到这些转化流是因为系统有时候只给我们提供了字节流,为了方便操作,要用到字符流。比如说System.in标准输入流就是字节流。你想从那里得到用户在键盘上的输入,只能是以转换流将它转换为Reader以方便自己的程序读取输入。再比如说Socket里的getInputStream()很明显只给你提供字节流,你要想读取字符,就得给他套个InputStreamReader()用来读取。
package com.zaojiahua.iodemo;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class Test {
public static void main(String[] args) throws IOException {
//字节流和字符流的相互转化
FileInputStream fileInputStream = new FileInputStream("input.txt");
//inputSreamReader本来就是reader对象,创建的时候需要传入一个InputStream对象,将字节流转化为字符流
BufferedReader reader = new BufferedReader(new InputStreamReader(fileInputStream));
//将字符流转化为字节流
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream("output.txt"));
BufferedWriter writer = new BufferedWriter(outputStreamWriter);
//实现拷贝文件的操作
String buf;
while((buf = reader.readLine()) != null)
{
writer.write(buf);
writer.newLine();
System.out.println(buf);
}
//关闭流
reader.close();
writer.close();
}
}参考链接
java中的IO操作总结(一) - Nerxious - 博客园
java中的IO操作|皂荚花
Java之美[从菜鸟到高手演变]之Java中的IO - 智慧演绎,无处不在 - 博客频道 - CSDN.NET