【Linux】【C/C++】多进程协同词频统计
在Linux环境下实现对指定目录下的文本文件进行单词词频的统计。由于可能会涉及到很多文件,因此为了提高统计效率,采用多进程协同合作的方式实现词频统计。
目标
- 实现多个进程之间系统并行运行,保证执行结果的正确及高效
- 进程之间任务是不同的,包含两大类进程,父进程进行任务划分及汇总,子进程负责完成划分的任务
设计思路及实现
程序实现的过程中,一共有11个进程并行执行,其中使用的是10个统计进程和一个父进程,子进程的创建数目可以根据宏定义进行修改。父进程的任务分为两个阶段:
1. 统计开始前,根据输入的路径进行遍历,获取所有的给定路径及其子目录下满足条件的文件,并将这些文件的绝对路径存储在一个任务队列中,用于向子进程分发任务。
2. 统计开始后,等待子进程,若子进程完成所有分配给它的任务并正常退出之后,父进程开始汇总相应退出子进程的统计结果,直到所有的子进程都正常退出并且所有的汇总工作都完成之后,父进程输出汇总结果,结束程序的运行。
子进程的执行过程就比较单一,仅仅是根据父进程分配给自己的文件绝对路径,去打开这些文件并读取和统计,直到所有分配的文件都统计完成之后,该子进程就完成任务正常退出。
根据上述的设计思路,可以看出,关键问题在于任务的分配和父子进程间的同步以及信息交换。
在任务分配中,以文件为基本的分配单位,且假设文件是多于统计进程的数目,那么每个统计进程至少可以分配到1个文件。实现时是通过父进程的遍历,将文件绝对路径存储在一个共享vector变量中,这样所有的子进程都可以访问这个共享向量。父进程最后通过这个共享向量实现任务的均衡划分。
父进程主要完成两个方面的任务:一个是文件的遍历,一个是子进程统计结果的汇总。父进程的执行流程图如下:

任务划分过程代码:task_load 是通过遍历得到的所有的文件数目取整加1.
那么子进程所需要处理的任务数量就是在vector中从i*task\_load 一直到end 之间的所有文件,其中end的取值是所有文件数目与(i+1)*task\_load中的较小值。
txt_files.size() < (i+1)*task_load ? txt_files.size():(i+1)*task_load
这样就可以保证vector中的所有任务都得到了处理并且不会出现交叠和越界的情况。
示例代码如下:
int task_load = txt_files.size()/PROCESS_NUM + 1;
for(i=0;i<PROCESS_NUM;i++){
//子进程执行代码片段
if(fork() == 0){
int exit_code = i;//getpid();
//每个子进程的任务量为:txt_files向量中位于 i*task_load 到 end之间的文件;
//其中end是(i+1)*task_load与txt_files.size()之间的较小值
int end = txt_files.size() < (i+1)*task_load ? txt_files.size():(i+1)*task_load;
DICT child_dict;
//char *wd;
char wd[WORD_LEN];
char buffer[BUFFER_SIZE + 1];
int r_fd;
int nread;
char get_file_path[FILE_PATH_LEN];
for(int j = i*task_load;j< end;j++){
memset(get_file_path,0,FILE_PATH_LEN);
int cpy_len = txt_files[j].length();
txt_files[j].copy(get_file_path,cpy_len,0);
//cout<<txt_files[j]<<" opened in process "<<i<<endl;
//get_file_path[]末尾补'\0'的操作可要可不要
//get_file_path[strlen(get_file_path)] = '\0';
cout<<"child "<<i<<" "<<get_file_path<<endl;
r_fd = open(get_file_path,O_RDONLY);
if(r_fd == -1 ){
printf("open file failed!\n");
exit(EXIT_FAILURE);
}
memset(buffer,0,BUFFER_SIZE);
nread = read(r_fd,buffer,BUFFER_SIZE);
if(nread < 0){
printf("read failed \n");
exit(EXIT_FAILURE);
}
//new
int index = 0;
int buf_len = strlen(buffer);
int word_len =0;
char temp_word[WORD_LEN];
bool flag = false;
while(nread > 0){
memset(wd,0,WORD_LEN);
while(index < buf_len){
if(flag){
//若出现单词分两次读取的情况
//一般单词被隔断,那么第二部分首字母一般不会是大写
//此处未对大小写进行判断
while(is_letter(buffer[index]) > 0){
if(is_letter(buffer[index]) == 1){
wd[word_len] = buffer[index];
}else
wd[word_len] = tolower(buffer[index]);
word_len++;
index++;
}
wd[word_len] = '\0';
strcat(temp_word,wd);
child_dict.add(temp_word,1);
memset(temp_word,0,WORD_LEN);
word_len = 0;
index++;
flag = false;
}
if(is_letter(buffer[index]) == 1){//小写字母
wd[word_len] = buffer[index];
index++;
word_len++;
}else if(is_letter(buffer[index]) == 2){//大写字母
wd[word_len] = tolower(buffer[index]);
index++;
word_len++;
}else{//不在字母表中
wd[word_len+1] = '\0';
if(strlen(wd) > 0){
child_dict.add(wd,1);
}
memset(wd,0,WORD_LEN);
word_len = 0;
index++;
}
}
index = 0;
memset(buffer,0,BUFFER_SIZE);
nread = read(r_fd,buffer,BUFFER_SIZE);
buf_len = strlen(buffer);
if(word_len != 0){
//buffer数据读完,但是没有到达单词尾部
//单词被分成两次读到buffer中,需要做特殊处理
flag = true;
strcat(temp_word,wd);
word_len = 0;
}
}
close(r_fd);
nread = 0;
r_fd = -1;
//wd = NULL;//old
memset(wd,0,WORD_LEN);
}
//输出子进程的词频结果
printf("child %d result: ",i);
child_dict.display();
//统计完需要完成的所有文件内容自后,将统计内容序列化到临时文件;
//文件名从全局变量temp_files向量中获取
int c_len = temp_files[i].length();
//将temp_files[i]中的内容复制到get_file_path中
//用于将子进程比那里词频写入到临时文件中
memset(get_file_path,0,FILE_PATH_LEN);
temp_files[i].copy(get_file_path,c_len,0);
int w_fd = open(get_file_path,O_CREAT|O_RDWR|O_TRUNC,0666);
if(w_fd != -1){
if(child_dict.Serialize(w_fd)){
cout<<"child:"<<i<<" serialize result to "<<get_file_path<<endl;
}else{
cout<<"child:"<<i<<" serialize result to "<<get_file_path<<" failed"<<endl;
}
close(w_fd);
}else{
//printf("open file %s failed \n",filepath);
cout<<"child:"<<i<<" create serialize file failed "<<endl;
}
//最后将退出码传递给父进程,退出码为子进程的编号
exit(exit_code);
}
}当父进程(汇总进程)遍历完给定的路径的时候,子进程在得到父进程发送的任务文件的绝对路径的时候,会进行文件的打开读取,并统计词频,多个统计子进程是同时并发执行。其执行流程如下:

其中的所有文件是指分配给当前子进程的统计文件,子进程只需要做文件打开读取,词频统计和把最终结果序列化到临时文件中。
在最后的汇总中,子进程需要将统计结果发送给父进程,以便于父进程进行结果的汇总。这里采用的是临时文件的方法:子进程每处理完一个文件,将结果存入私有的一个vector中,等到所有的任务都处理完成之后就会将这些结果写入到一个临时的.dat文件中。父进程通过这些临时文件中的内容进行结果汇总。汇总过程还是一个反序列化的过程。
代码如下:
for(i=0;i<PROCESS_NUM;i++){
char p_get_filepath[FILE_PATH_LEN];
int p_len = temp_files[i].length();
memset(p_get_filepath,0,FILE_PATH_LEN);
temp_files[i].copy(p_get_filepath,p_len,0);
int p_fd = open(p_get_filepath,O_RDONLY);
if(p_fd != -1){
child_dict[i].Deserialize(p_fd);
cout<<"parent:"<<getpid()<<" deserialize file "<<p_get_filepath<<" succeed"<<endl;
close(p_fd);
}else{
cout<<"parent:"<<getpid()<<" deserialize file "<<p_get_filepath<<" failed"<<endl;
}
//词频汇总到向量sum_dict中
for(int j=0;j<child_dict[i].wordbook.size();j++){
//cout<<"child :"<<child_dict[i].wordbook[j].word<<" --> "<<child_dict[i].wordbook[j].count<<endl;
Words w(child_dict[i].wordbook[j].word,child_dict[i].wordbook[j].count);
//sum_dict.add(child_dict[i].wordbook[j].word,child_dict[i].wordbook[j].count);
sum_dict.add(w.word,w.count);
}
}最后,汇总完成之后,将结果输出,同时将子进程创建的临时.dat文件删除。
完整的词频统计代码如下:
/** * 词频统计代码: * 1.通过目录遍历函数将给定目录下的所有 .txt文件的绝对路径压入vector中 * 2.新建一个单词类,该类包含一个字符指针char*,一个int型词频,一个序列化到文件和反序列化到对象的方法 * 3.对得到的这个vector进行PROCESS_NUM等量划分,fork出PROCESS_NUM个子进程完成vector中文件的词频统计工作,将得到的词频队形序列化到特定文件名的文件 * 4.子进程结束后由父进程将PROCESS_NUM中序列化的对象反序列化出来进行汇总,并删除临时文件 * 5.将最终结果打印到屏幕或者写入到文件 */
#include<unistd.h>
#include<stdlib.h>
#include<stdio.h>
#include<fcntl.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<sys/stat.h>
#include<string.h>
#include<limits.h>
#include<string>
#include<vector>
#include<iostream>
#include<dirent.h>
#include<string>
#include<time.h>
#define FILE_PATH_LEN 1024 //路径的最大长度
#define PROCESS_NUM 10 //处理进程的数目
#define BUFFER_SIZE 4096 //缓冲区的大小
#define WORD_LEN 40//单词的长度,固定以简化序列化和反序列化
using namespace std;
//全局变量 ‘/’ 用于scandir()中构造文件绝对路径
char slash = '/';
//用于在scandir()中存储查找到的txt文件绝对路径;用于之后的子进程任务划分
vector<string> txt_files; //文件路径向量
//PROCESS_NUM个子进程创建对应其编号的10个临时文件,用于序列化统计结果供父进程汇总
vector<string> temp_files;
//char SEPERATOR[] = {' ',',','.',';','?','!','@','<','>','/',';','#','%','&','(',')','{','}','[',']'};
//char ALPHABET[] = {'a','b','c','d','e','f','g','h','i','j','k',
// 'l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
//字母表,简化程序,只有出现在字母表中的连续字母串才会被认为是一个单词,忽略了简写的单词和以‘-’连接的单词
char ALPHA[] = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
/* * 判断当前字符是否在字母表中;字母表可变 * * 若字符在当前字母表中,返回其位置 * 0-25代表小写字母 ,统一返回1 * 26-51代表大写字母:统一返回2 * * 不是字母表中字符返回-1 * */
int is_letter(char c){
int len = strlen(ALPHA);
int i = 0;
for(i=0;i<len;i++){
if(c == ALPHA[i]){
if(i < 26)
return 1;
else if(i< 52)
return 2;
}
}
return -1;
}
/* * 初始化临时文件名,将临时文件的绝对路径名保存在temp_files向量中 * 文件名的形式是:绝对路径/i.dat * * 后缀为dat,可变 * 临时文件在父进程完成汇总之后删除 * */
void init_tempfiles(){
int i=0;
string s;
char put_file_path[FILE_PATH_LEN];
//同样是getcwd()在scandir中获取的就是绝对路径,
//但是在init_tempfiles获取的确是上级目录的绝对路径
//getcwd(put_file_path,sizeof(put_file_path));
//cout<<put_file_path<<endl;
char c = '0';
char temp[FILE_PATH_LEN];
for(i=0;i<PROCESS_NUM;i++){
memset(put_file_path,0,FILE_PATH_LEN);
memset(temp,0,FILE_PATH_LEN);
getcwd(put_file_path,FILE_PATH_LEN);
strcat(put_file_path,&slash);
temp[0] = c;
strcat(temp,".dat");
//若想要创建将临时文件放在一个不存在的目录中,还需要能够将这个目录创建出来
//strcat(put_file_path,"temp_files/");
strcat(put_file_path,temp);
string s(put_file_path);
temp_files.push_back(s);
c++;
cout<<s<<endl;
}
if(temp_files.size() == PROCESS_NUM){
printf("init temp_files succeed\n");
}else{
printf("init temp_files failed\n");
}
}
/* * 单词类,实现单个单词和相应的词频 * 序列化函数以及反序列化函数用于将对象序列化到文件和反序列化到对象 */
class Words{
public:
int count;
char word[WORD_LEN];
public:
Words(char *w,int c){
count = c;
strcpy(word,w);
}
Words(){
count = 0;
word[0] = '\0';
}
~Words(){}
public:
bool Serialize(int fd){
if(fd == -1)
return false;
if(write(fd,&count,sizeof(count)) == -1){
return false;
}
if(write(fd,&word,WORD_LEN) == -1){
return false;
}
return true;
}
bool Deserialize(int fd){
if(fd == -1)
return false;
int nread;
nread = read(fd,&count,sizeof(count));
if(nread <= 0)
return false;
nread = read(fd,&word,WORD_LEN);
if(nread <= 0)
return false;
return true;
}
void Print(){
cout<<count<<" --> "<<word<<endl;
}
};
/* * 词典类:以单词对象为成员变量声明一个vector存储当前统计到的单词 * add()函数用于将当前读取到的单词添加到词典当中,第一个参数是单词内容,第二个是出现频率 * display()函数用于打印当前词典内容 * Serialize()调用vector中成员的序列化函数,将wordbook序列化到文件 * Deserialize()调用vector中成员的反序列化函数,将文件中的内容反序列化对象 */
class DICT{
public:
vector<Words> wordbook;
public:
bool add(char *w,int rate){
vector<Words>::iterator itr = wordbook.begin();
while(itr != wordbook.end()){
//两个字符数组相等则strcmp()返回为 0
if(strcmp((*itr).word, w) == 0){
(*itr).count += rate;
return true;
}
itr++;
}
//由于最后汇总的时候需要使用add函数,而汇总的过程中,rate并不总是1
//所以构造对象的时候还是需要使用rate而不是1
Words temp_w(w,rate);
wordbook.push_back(temp_w);
return true;
}
void display(){
vector<Words>::iterator itr = wordbook.begin();
while(itr != wordbook.end()){
(*itr).Print();
itr++;
}
}
/* * 序列化函数还需要进行修改,因为不存在返回为false的情形 * */
bool Serialize(int fd){
for(int i=0;i<wordbook.size();i++){
wordbook[i].Serialize(fd);
}
return true;
}
bool Deserialize(int fd){
while(1){
Words *p_w = new Words();
if(p_w->Deserialize(fd))
wordbook.push_back(*p_w);
else
break;
delete p_w;
}
return true;
}
};
/* * istxt()用于判断当前文件是否是需要进行词频统计的txt文件 */
bool istxt(char *filename,int len){
if(filename[len -1] == 't' && filename[len-2] == 'x' && filename[len-3] == 't')
return true;
else
return false;
}
/* * 判断当前字符是否是分隔符 * */
/* * 扫描给定目录下的txt文件,将扫描结果存储在全局变量vector<string> txt_files中 */
void scandir(char *dir){
DIR *dp;
struct dirent *entry;
struct stat statbuf;
if((dp = opendir(dir)) == NULL){
printf("can't open directory: %s\n",dir);
return;
}
chdir(dir);
while((entry = readdir(dp)) != NULL){
lstat(entry->d_name,&statbuf);
// is a dir
if(S_ISDIR(statbuf.st_mode)){
//if cur dir or parent dir
if((strcmp(".",entry->d_name) == 0) || (strcmp("..",entry->d_name)) == 0){
continue;
}else{
// recurse
scandir(entry->d_name);
}
}else{
// not dir,find a file ; if a .txt
//int len = strlen(entry->d_name);
if(istxt(entry->d_name,/*len*/strlen(entry->d_name))){
char put_file_path[FILE_PATH_LEN];
getcwd(put_file_path,sizeof(put_file_path));
strcat(put_file_path,&slash);
strcat(put_file_path,entry->d_name);
string s(put_file_path);
txt_files.push_back(s);
put_file_path[0] = '\0';
}
}
}
chdir("..");
closedir(dp);
}
int main(int argc , char* argv[]){
int i = 0;
time_t start,end;
float time_len;
start = time(NULL);
//char *topdir = ".";
char topdir[FILE_PATH_LEN] ;
strcpy(topdir,".");
//从标准输入得到扫描路径,默认扫描路径为当前路径
if(argc >= 2){
strcpy(topdir,argv[1]);
//topdir = argv[1];
}else{
cout<<"argument input error"<<endl;
return 0;
}
//开始扫描
scandir(topdir);
for(i=0;i<txt_files.size();i++)
cout<<txt_files[i]<<endl;
//初始化子进程的临时文件名
init_tempfiles();
int task_load = txt_files.size()/PROCESS_NUM + 1;
for(i=0;i<PROCESS_NUM;i++){
//子进程执行代码片段
if(fork() == 0){
int exit_code = i;//getpid();
//每个子进程的任务量为:txt_files向量中位于 i*task_load 到 end之间的文件;
//其中end是(i+1)*task_load与txt_files.size()之间的较小值
int end = txt_files.size() < (i+1)*task_load ? txt_files.size():(i+1)*task_load;
DICT child_dict;
//char *wd;
char wd[WORD_LEN];
char buffer[BUFFER_SIZE + 1];
int r_fd;
int nread;
char get_file_path[FILE_PATH_LEN];
for(int j = i*task_load;j< end;j++){
//子进程开始对各自的任务进行词频统计
//取出文件绝对路径
memset(get_file_path,0,FILE_PATH_LEN);
int cpy_len = txt_files[j].length();
txt_files[j].copy(get_file_path,cpy_len,0);
//cout<<txt_files[j]<<" opened in process "<<i<<endl;
//get_file_path[]末尾补'\0'的操作可要可不要
//get_file_path[strlen(get_file_path)] = '\0';
cout<<"child "<<i<<" "<<get_file_path<<endl;
r_fd = open(get_file_path,O_RDONLY);
if(r_fd == -1 ){
printf("open file failed!\n");
exit(EXIT_FAILURE);
}
memset(buffer,0,BUFFER_SIZE);
nread = read(r_fd,buffer,BUFFER_SIZE);
if(nread < 0){
printf("read failed \n");
exit(EXIT_FAILURE);
}
//new
int index = 0;
int buf_len = strlen(buffer);
int word_len =0;
char temp_word[WORD_LEN];
bool flag = false;
while(nread > 0){
memset(wd,0,WORD_LEN);
while(index < buf_len){
if(flag){
//若出现单词分两次读取的情况
//一般单词被隔断,那么第二部分首字母一般不会是大写
//此处未对大小写进行判断
while(is_letter(buffer[index]) > 0){
if(is_letter(buffer[index]) == 1){
wd[word_len] = buffer[index];
}else
wd[word_len] = tolower(buffer[index]);
word_len++;
index++;
}
wd[word_len] = '\0';
strcat(temp_word,wd);
child_dict.add(temp_word,1);
memset(temp_word,0,WORD_LEN);
word_len = 0;
index++;
flag = false;
}
if(is_letter(buffer[index]) == 1){//小写字母
wd[word_len] = buffer[index];
index++;
word_len++;
}else if(is_letter(buffer[index]) == 2){//大写字母
wd[word_len] = tolower(buffer[index]);
index++;
word_len++;
}else{//不在字母表中
wd[word_len+1] = '\0';
if(strlen(wd) > 0){
child_dict.add(wd,1);
}
memset(wd,0,WORD_LEN);
word_len = 0;
index++;
}
}
index = 0;
memset(buffer,0,BUFFER_SIZE);
nread = read(r_fd,buffer,BUFFER_SIZE);
buf_len = strlen(buffer);
if(word_len != 0){
//buffer数据读完,但是没有到达单词尾部
//单词被分成两次读到buffer中,需要做特殊处理
flag = true;
strcat(temp_word,wd);
word_len = 0;
}
}
/* while(nread > 0){ wd = strtok(buffer," "); while(wd != NULL){ child_dict.add(wd,1); wd = strtok(NULL," "); } memset(buffer,0,BUFFER_SIZE); nread = read(r_fd,buffer,BUFFER_SIZE); } */
close(r_fd);
nread = 0;
r_fd = -1;
//wd = NULL;//old
memset(wd,0,WORD_LEN);
}
//输出子进程的词频结果
printf("child %d result: ",i);
child_dict.display();
//统计完需要完成的所有文件内容自后,将统计内容序列化到临时文件;
//文件名从全局变量temp_files向量中获取
int c_len = temp_files[i].length();
//将temp_files[i]中的内容复制到get_file_path中
//用于将子进程比那里词频写入到临时文件中
memset(get_file_path,0,FILE_PATH_LEN);
temp_files[i].copy(get_file_path,c_len,0);
int w_fd = open(get_file_path,O_CREAT|O_RDWR|O_TRUNC,0666);
if(w_fd != -1){
if(child_dict.Serialize(w_fd)){
cout<<"child:"<<i<<" serialize result to "<<get_file_path<<endl;
}else{
cout<<"child:"<<i<<" serialize result to "<<get_file_path<<" failed"<<endl;
}
close(w_fd);
}else{
//printf("open file %s failed \n",filepath);
cout<<"child:"<<i<<" create serialize file failed "<<endl;
}
//最后将退出码传递给父进程,退出码为子进程的编号
exit(exit_code);
}
}
//父进程执行代码片段
for(i=0;i<PROCESS_NUM;i++){
int stat_val;
pid_t child_pid = wait(&stat_val);
printf("child %d exit \n",WEXITSTATUS(stat_val));
}
//wait结束之后开始进行汇总;
DICT sum_dict;
DICT child_dict[PROCESS_NUM];
for(i=0;i<PROCESS_NUM;i++){
char p_get_filepath[FILE_PATH_LEN];
int p_len = temp_files[i].length();
memset(p_get_filepath,0,FILE_PATH_LEN);
temp_files[i].copy(p_get_filepath,p_len,0);
int p_fd = open(p_get_filepath,O_RDONLY);
if(p_fd != -1){
child_dict[i].Deserialize(p_fd);
cout<<"parent:"<<getpid()<<" deserialize file "<<p_get_filepath<<" succeed"<<endl;
close(p_fd);
}else{
cout<<"parent:"<<getpid()<<" deserialize file "<<p_get_filepath<<" failed"<<endl;
}
//词频汇总到向量sum_dict中
for(int j=0;j<child_dict[i].wordbook.size();j++){
//cout<<"child :"<<child_dict[i].wordbook[j].word<<" --> "<<child_dict[i].wordbook[j].count<<endl;
Words w(child_dict[i].wordbook[j].word,child_dict[i].wordbook[j].count);
//sum_dict.add(child_dict[i].wordbook[j].word,child_dict[i].wordbook[j].count);
sum_dict.add(w.word,w.count);
}
}
cout<<"parent: the reault is :"<<endl;
sum_dict.display();
//使用system("rm filename")将程序创建的临时文件删除
char command[FILE_PATH_LEN];
char file_path[FILE_PATH_LEN];
for(i=0;i<temp_files.size();i++){
memset(command,0,FILE_PATH_LEN);
memset(file_path,0,FILE_PATH_LEN);
temp_files[i].copy(file_path,FILE_PATH_LEN,0);
strcat(command,"rm ");
strcat(command,file_path);
system(command);
}
end = time(NULL);
time_len = end - start;
printf("run %f seconds \n",time_len);
printf(" %d finished task\n",getpid());
exit(EXIT_SUCCESS);
}结果验证
测试的时候分为两个方面的测试,一个是对已知的较小的任务数量进行并发统计,对比输出结果与预期结果,另一个是对系统的目录进行统计,检验程序是否可以实现高效的并行处理多个任务。
测试一:
对当前目录下使用代码自动生成的一个单词文本文件进行测试,其中输出包括:
- 遍历得到的所有.txt文件的绝对路径
- 子程序序列化结果的临时文件*.dat文件的绝对路径,以及序列化结果到文件的状态
- 子进程对应处理的任务,以及处理完成之后的输出
- 子进程处理完成之后退出状态
- 父进程反序列化子进程创建的.dat临时文件获取结果并汇总的状态,以及最后的汇总结果的输出
- 统计词频所花费的总时间
当前统计的目录是 /root/APUE/homework/task2 目录和子目录下的所有.txt文件的单词数目,.txt文件包含有空的文件和固定单词数目的文件如simple.txt hello.txt分别包含了10000个simple单词和900个hello单词。最后的汇总结果与事先生成的文件中单词个数相同,运行时间小于1秒。
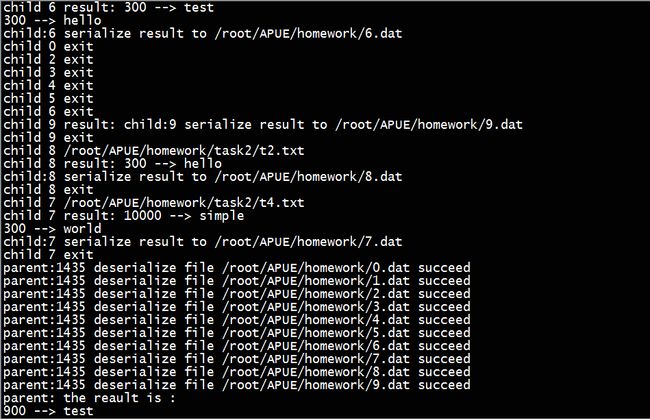
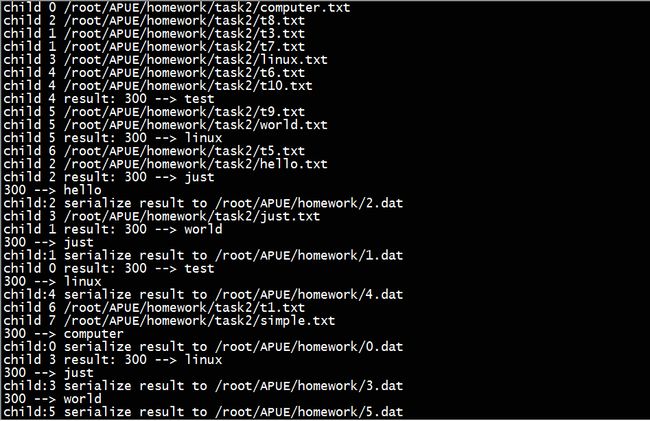
测试二:对系统的/root 目录进行测试部分结果截图为:
箭头的左边表示的是单词出现的次数,右边表示的是单词内容,这里截取的是部分汇总的结果,子进程的输出未截取。最终对/root的汇总时间是2秒。最后输出的是父进程(汇总进程)的pid。
在时间复杂度上:
父子进程最后的结果发送使用的是临时文件的方式,这涉及到磁盘的读写,显然会大大降低程序运行的速度,同时也会占用磁盘存储空间。一种更好的父子进程大数据量通信的方法时使用管道,或者更加高效的方法是使用共享内存(但是使用共享内存需要自己控制进程读写,比较复杂,优点就在于其可共用的内存空间可以比管道大很多),传输最后的统计结果,这样所有的操作在内存中进行,时间效率就会快很多。
在空间复杂度上:
在任务的划分的过程中使用了全局的共享向量vector,这就造成了所有的子进程会拥有这样的一份副本,如果进行统计的子进程数目过多,那么这种共享全局变量的形式的空间效率就会极低。