Ubuntu下安装配置Hadoop
Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
在这里介绍用虚拟机搭建伪分布式。
需要的软件有:
1.VMware10
2.ubuntu-14.04.4镜像
3.hadoop-2.2.0
(链接:http://pan.baidu.com/s/1nvH3JgX 密码:2dj2 需要的软件我都放在云盘中,有需要的自行下载)
注:搭建伪分布式需要装3个虚拟系统,建议电脑内存8G或以上,如果电脑内存小于8G可以装Ubuntu server版。
装虚拟机的过程我就不说了,VMware 10 装Ubuntu一键安装即可,下面详细叙述Hadoop的安装和配置过程。
1.三台机器开启root登陆。
安装好三台Ubuntu虚拟机后,默认是不开启root登陆的,需要手动开启,修改50-ubuntu.conf文件即可,命令如下:
![]()
添加内容如下:

配置好了之后,开启root账号命令如下(设置新密码):
sudo passwd root
然后即可root登陆,后面都将在root用户下完成。
2.设置三台Ubuntu机器的主机名和hosts文件。
设置主机名hostname如下命令:
vim /etc/hostname
三台主机hostname分别设置为master,slaver1,slaver2。
然后设置hosts文件,命令如下:
vim /etc/hosts
主机名和IP地址对应如下。
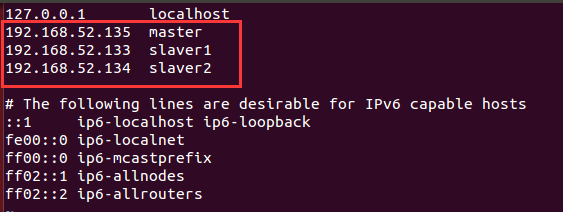
注:如果不知道自己的IP地址,用如下的命令查询:
重启即可生效。
3.三台机器安装openjdk-7-jdk
安装命令如下:
apt-get install openjdk-7-jdk
安装完成后我们需要配置jdk环境,先查找jdk安装目录,命令如下:
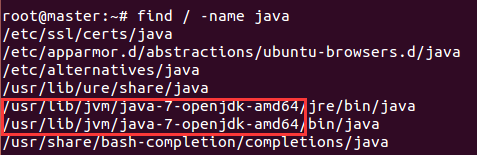
配置环境变量,命令如下:
vim /etc/environment
修改内容如下:

在/etc/profile文件末尾添加java用户环境变量如下:
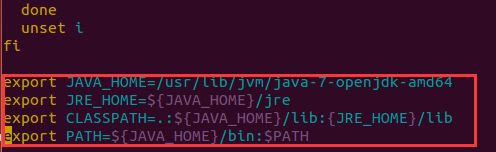
完成后jdk就配置完成,验证有没有配置成功的命令如下:
4.安装ssh并配置免密码登陆
安装ssh命令如下:
apt-get install ssh
apt-get install openssh-client
apt-get install openssh-server
安装成功后,需要更改sshd_config文件
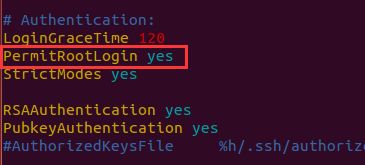
生成密钥并配置SSH免密码登录本机
三台机器都使用下面的命令,按4次回车即可完成。
ssh-keygen -t dsa
生成密钥和公钥在/root/.ssh/下
![]()
在master主机下先使用以下命令讲公钥写入授权文件authorized_keys:
然后将授权文件authorized_keys文件传给slaver1主机,命令如下
scp authorized_keys slaver1:~/.ssh
然后将slaver1的公钥也id_dsa.pub文件写入到传过去的授权文件authorized_keys文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后将slaver1的authorized_keys文件传给slaver2,同样的方法将slaver2的id_dsa.pub文件写入到authorized_keys文件中。
最后将slaver2的authorized_keys(含有三个主机公钥的授权文件)用scp分别再传回给master和slaver1。
此时打开authorized_keys文件,你将看到三个主机的公钥:
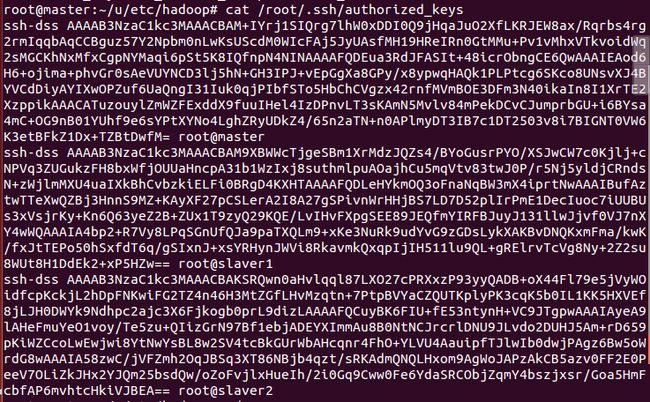
此时ssh免密登陆已经完成了。最后为了防止防火墙禁止一些端口号,三台机器应使用
关闭防火墙命令:ufw disable。然后重启生效。
验证免密登陆是否生效只需用一下命令:
ssh slaver1
ssh slaver2
5.Hadoop的安装与配置
将下载的hadoop-2.2.0解压至/root下,并更改名字为u
![]()
![]()
先配置master的Hadoop,配置好了之后直接复制给slaver1和slaver2主机就行了。
需要修改的配置文件有如下的七个:
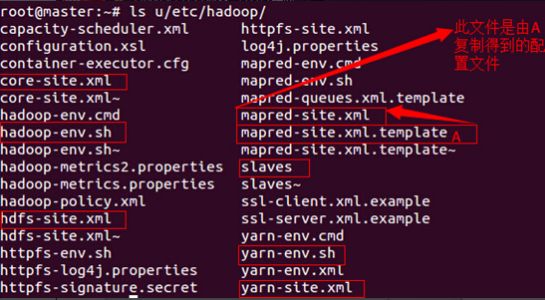
配置文件1:hadoop-env.sh
修改JAVA_HOME值如下图:
![]()
配置文件2:yarn-env.sh
修改JAVA_HOME值如下图:
![]()
配置文件3:slaves(保存所有slave节点)写入以下内容:
![]()
配置文件4:core-site.xml
添加配置内容如下图:
配置文件5:hdfs-site.xml

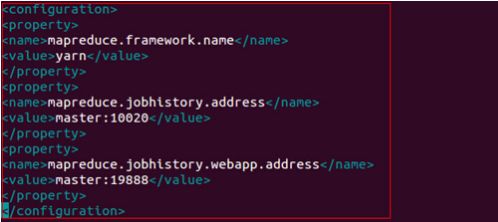
配置文件6:mapred-site.xml
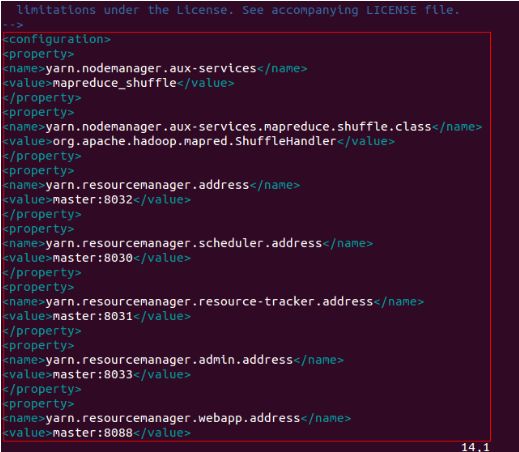
配置文件7:yarn-site.xml
接下来就是把Hadoop复制给slaver1和slaver2,用如下命令:
scp -r /root/u slaver1:/root/
scp -r /root/u slaver2:/root/
为了方便使用Hadoop和hdfs的相关命令,还需要配置环境变量,命令如下
vim /etc/environment

添加完后执行生效命令:source /etc/environment
下面要做的就是启动验证,建议在验证前,把以上三台机器重启,使其相关配置生效。
6.启动验证
在master节点上进行格式化namenode:
命令:hadoop namenode -format
在master节点上进行启动hdfs:
start-all.sh
使用Jps命令master有如下进程,说明ok
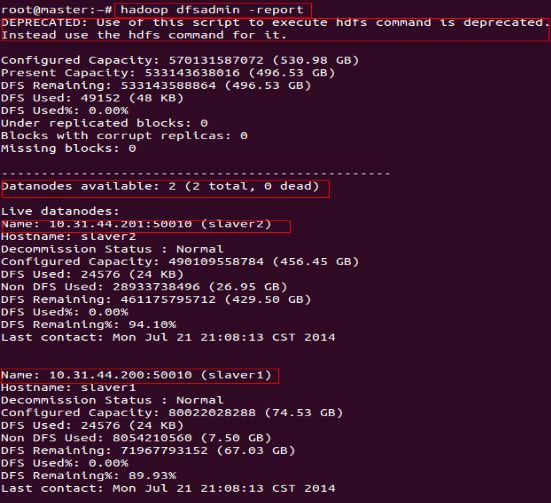
查看集群状态,命令:hadoop dfsadmin -report
查看分布式文件系统:http://master:50070
查看MapReduce:http://master:8088
使用以上命令,当你看到如下图所示的效果图时,恭喜你完成了Hadoop完全分布式的安装设置。
集群的关闭在master节点上执行命令如下:
stop-all.sh