elasticsearch搜索关键词详解
近期由于工作需要,详细了解了es搜索关键词的具体含意,其实质还是lucene的搜索关键词的释意。下详述之。
首先强调下term概念,当某个字段进行分词操作后,该字段对应的任意串至少会被分为多个term。
当不进行分词操作时,一个串只会被分为有且只有一个term。
(1)term query
term,为对某字段的分词处理后形成的最小的有意义串的单元,如原始串为”中国人民",那么分词后成“中国”、“人民”的话,即“中国”和“人民”都是分词处理后的term对象。如果设置的字段为“not_analyzer"即不分词,则直接将该原始串作为一个term来对待。
term query search,即是以term为单位的搜索。如对字段keyword进行分词后进行term search,结果如下图:
当搜索“中国人民”和“中国人民共”时,由上两图可见,term query搜索时,输入的串本身在搜索时是不进行分词的,是针对term单位来搜索的,只有输入串和某个term完全匹配时才会命中并显示。
(2) wildcard query
即通配搜索,它也是针对term的为单位进行的通配搜索,主要包括*和?两种匹配,前者为匹配所有,后者为匹配第一个字符。


通过该单元图1、图2的对比,说明?号匹配为1个字符;通过图1、图3对比,说明*号匹配0至多个字符。
(3)prefix query
也可称为前缀匹配,该匹配比较特殊,它对中文的匹配与term query是完全一样的,这是由中文本身的特点决定,一个字不能分成两半或多半是其根本原因(下图1、图2可证明)。其对可折散的英文作用明显,(下图3、下图4证明)

图1
图2

图3

图4
该匹配只对可拆散的单词才有明显作用,即前缀匹配。
(4)fuzzy query
即为模糊匹配,跟通配匹配不同,通配匹配只是纯字符占位意义的匹配,其深层意义不大。但该处的模糊匹配,是基于编辑距离,即Levenshtein Distance,来定义某term与输入的串的相似度的,所以其深度要略高于wildcard query。往往可以用于单词纠错、近义词查找等,如下图1、图2、图3、图4所示。
图1

图2

图3

图4
通过图1、2对比,和图3、4对比,明显英文的效果在fuzzy上更让人醒目一些,关于具体的比较计算,会在后续专门讲解。
(5)range query
主要是做一些范围查询与过滤,主要是针对一些数值型字段,对字符串型亦可,只是效率上要下降很多。所以一般在用range时,均对数值型做相关的range操作。
(6)query_string query
该查询是用的最多的,即百度所用的最通用方式。首先会对用户输入的原始串进行分词操作,然后拿分词后的term集合,去自己的索引库中进行对比与打分计算,最终,按score逆序排名做显示。
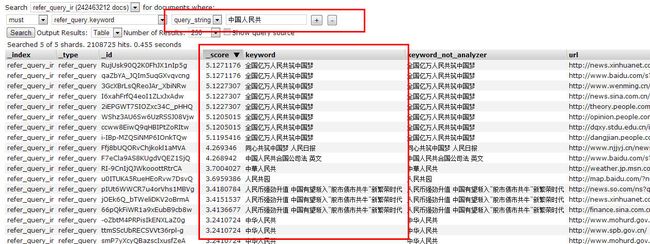
以上6种搜索匹配关键词,是最常用的,再加上各种逻辑操作,包括must、must not、should,即对应and、not、or的逻辑操作,可以组合出丰富的搜索条件。更高级的关键词及应用,会在后续跟进。
时间原因,暂止于此,欢迎加入网络爬虫、nlp群320349384进行问题指正与交流。