Spark standalone下的运行过程
Spark的Cluster Manager可以有以下几种部署方式:
1. standalone
2. Mesos
3. YARN
4. EC2
5. Local
其中standalone方式是spark自带的部署方式,下面我们分别对没有HA的standalone模式和带有HA的standalone模式中application的提交与具体的运行流程进行一个比较详尽的分析。
没有HA的standalone运行模式
在cluster中,两种角色被定义分别是master和worker;slaver worker可以有一个或者多个,可以和master在同一主机也可有自己的机器,当然了这些worker都处于active状态。
Driver Application可以运行在Cluster之内,也可以在cluster之外运行,先从简单的讲起即Driver Application独立于Cluster。那么这样的整体框架如下图所示,由driver,master和多个slave worker来共同组成整个的运行环境。
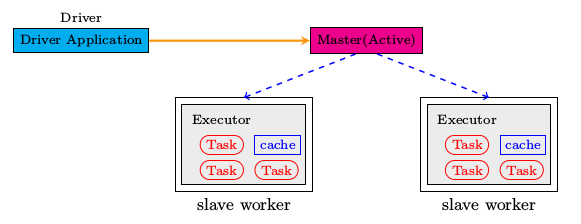
执行顺序
步骤1 运行master
$SPARK_HOME/sbin/start_master.sh在start_master.sh中最关键的一句就是
"$sbin"/spark-daemon.sh start org.apache.spark.deploy.master.Master 1 --ip $SPARK_MASTER_IP --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT检测Master的jvm进程
root 23438 1 67 22:57 pts/0 00:00:05 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip localhost --port 7077 --webui-port 8080Master的日志在$SPARK_HOME/logs目录下
步骤2 运行worker,可以启动多个
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077worker运行时,需要注册到指定的master url,这里就是spark://localhost:7077.
Master侧收到RegisterWorker通知,其处理代码如下
case RegisterWorker(id, workerHost, workerPort, cores, memory, workerUiPort, publicAddress) =>
{
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else if (idToWorker.contains(id)) {
sender ! RegisterWorkerFailed("Duplicate worker ID")
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
sender, workerUiPort, publicAddress)
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
sender ! RegisteredWorker(masterUrl, masterWebUiUrl)
schedule()
} else {
val workerAddress = worker.actor.path.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
sender ! RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress)
}
}
}步骤3 运行Spark-shell
MASTER=spark://localhost:7077 $SPARK_HOME/bin/spark-shellspark-shell属于application,有关appliation的运行日志存储在$SPARK_HOME/works目录下
spark-shell作为application,向Master中注册application通过RegisterApplication,具体处理代码如下。
case RegisterApplication(description) => {
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, sender)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
sender ! RegisteredApplication(app.id, masterUrl)
schedule()
}
}每当有新的application注册到master,master都要调度schedule函数将application发送到相应的worker,在对应的worker启动相应的ExecutorBackend. 具体代码请参考Master.scala中的schedule函数,代码就不再列出。
步骤4 结果检测
/opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip localhost --port 7077 --webui-port 8080
root 23752 23745 21 23:00 pts/0 00:00:25 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.repl.Main
root 23986 23938 25 23:02 pts/2 00:00:03 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.worker.Worker spark://localhost:7077
root 24047 23986 34 23:02 pts/2 00:00:04 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Xms512M -Xmx512M org.apache.spark.executor.CoarseGrainedExecutorBackend akka.tcp://spark@localhost:40053/user/CoarseGrainedScheduler 0 localhost 4 akka.tcp://sparkWorker@localhost:53568/user/Worker app-20140511230059-0000从运行的进程之间的关系可以看出,worker和master之间的连接建立完毕之后,如果有新的driver application连接上master,master会要求worker启动相应的ExecutorBackend进程。此后若有什么Task需要运行,则会运行在这些Executor之上。可以从以下的日志信息得出此结论,当然看源码亦可。
14/05/11 23:02:36 INFO Worker: Asked to launch executor app-20140511230059-0000/0 for Spark shell
14/05/11 23:02:36 INFO ExecutorRunner: Launch command: "/opt/java/bin/java" "-cp" ":/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar" "-Xms512M" "-Xmx512M" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "akka.tcp://spark@localhost:40053/user/CoarseGrainedScheduler" "0" "localhost" "4" "akka.tcp://sparkWorker@localhost:53568/user/Worker" "app-20140511230059-0000"worker中启动exectuor的相关源码见worker中的receive函数,相关代码如下
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
val manager = new ExecutorRunner(appId, execId, appDesc, cores_, memory_,
self, workerId, host,
appDesc.sparkHome.map(userSparkHome => new File(userSparkHome)).getOrElse(sparkHome),
workDir, akkaUrl, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
masterLock.synchronized {
master ! ExecutorStateChanged(appId, execId, manager.state, None, None)
}
} catch {
case e: Exception => {
logError("Failed to launch exector %s/%d for %s".format(appId, execId, appDesc.name))
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
masterLock.synchronized {
master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED, None, None)
}
}
}
}关于standalone的部署,需要详细研究的源码文件如下所列。
deploy/master/Master.scala
deploy/worker/worker.scala
executor/CoarseGrainedExecutorBackend.scala查看进程之间的父子关系,请用”pstree”
使用下图来小结单Master的部署情况。

在cluster中运行Driver Application
上一节之所以写到类的动态加载与反射都是为了谈这一节的内容奠定基础。
将Driver application部署到Cluster中,启动的时序大体如下图所示。

首先启动Master,然后启动Worker,使用”deploy.Client”将Driver Application提交到Cluster中
./bin/spark-class org.apache.spark.deploy.Client launch
[client-options] \
\
[application-options]- Master在收到RegisterDriver的请求之后,会发送LaunchDriver给worker,要求worker启动一个Driver的jvm process
- Driver Application在新生成的JVM进程中运行开始时会注册到master中,发送RegisterApplication给Master
- Master发送LaunchExecutor给Worker,要求Worker启动执行ExecutorBackend的JVM Process
- 一当ExecutorBackend启动完毕,Driver Application就可以将任务提交到ExecutorBackend上面执行,即LaunchTask指令
提交侧的代码,详见deploy/Client.scala
driverArgs.cmd match {
case "launch" =>
// TODO: We could add an env variable here and intercept it in `sc.addJar` that would
// truncate filesystem paths similar to what YARN does. For now, we just require
// people call `addJar` assuming the jar is in the same directory.
val env = Map[String, String]()
System.getenv().foreach{case (k, v) => env(k) = v}
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
val classPathConf = "spark.driver.extraClassPath"
val classPathEntries = sys.props.get(classPathConf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathConf = "spark.driver.extraLibraryPath"
val libraryPathEntries = sys.props.get(libraryPathConf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val javaOptionsConf = "spark.driver.extraJavaOptions"
val javaOpts = sys.props.get(javaOptionsConf)
val command = new Command(mainClass, Seq("{{WORKER_URL}}", driverArgs.mainClass) ++
driverArgs.driverOptions, env, classPathEntries, libraryPathEntries, javaOpts)
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command)
masterActor ! RequestSubmitDriver(driverDescription)接收侧
从Deploy.client发送出来的消息被谁接收呢?答案比较明显,那就是Master。 Master.scala中的receive函数有专门针对RequestSubmitDriver的处理,具体代码如下
case RequestSubmitDriver(description) => {
if (state != RecoveryState.ALIVE) {
val msg = s"Can only accept driver submissions in ALIVE state. Current state: $state."
sender ! SubmitDriverResponse(false, None, msg)
} else {
logInfo("Driver submitted " + description.command.mainClass)
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
schedule()
// TODO: It might be good to instead have the submission client poll the master to determine
// the current status of the driver. For now it's simply "fire and forget".
sender ! SubmitDriverResponse(true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}")
}
}SparkEnv
SparkEnv对于整个Spark的任务来说非常关键,不同的role在创建SparkEnv时传入的参数是不相同的,如Driver和Executor则存在重要区别。
在Executor.scala中,创建SparkEnv的代码如下所示
private val env = {
if (!isLocal) {
val _env = SparkEnv.create(conf, executorId, slaveHostname, 0,
isDriver = false, isLocal = false)
SparkEnv.set(_env)
_env.metricsSystem.registerSource(executorSource)
_env
} else {
SparkEnv.get
}
}Driver Application则会创建SparkContext,在SparkContext创建过程中,比较重要的一步就是生成SparkEnv,其代码如下
private[spark] val env = SparkEnv.create(
conf,
"",
conf.get("spark.driver.host"),
conf.get("spark.driver.port").toInt,
isDriver = true,
isLocal = isLocal,
listenerBus = listenerBus)
SparkEnv.set(env)Standalone模式下HA的实现
Spark在standalone模式下利用zookeeper来实现了HA机制,这里所说的HA是专门针对Master节点的,因为上面所有的分析可以看出Master是整个cluster中唯一可能出现单点失效的节点。
采用zookeeper之后,整个cluster的组成如下图所示。

为了使用zookeeper,Master在启动的时候需要指定如下的参数,修改conf/spark-env.sh, SPARK_DAEMON_JAVA_OPTS中添加如下选项。
| System property | Meaning |
|---|---|
| spark.deploy.recoveryMode | Set to ZOOKEEPER to enable standby Master recovery mode (default: NONE). |
| spark.deploy.zookeeper.url | The ZooKeeper cluster url (e.g., 192.168.1.100:2181,192.168.1.101:2181). |
| spark.deploy.zookeeper.dir | The directory in ZooKeeper to store recovery state (default: /spark). |
实现HA的原理
zookeeper提供了一个Leader Election机制,利用这个机制,可以实现HA功能,具体请参考zookeeper recipes
在Spark中没有直接使用zookeeper的api,而是使用了curator,curator对zookeeper做了相应的封装,在使用上更为友好。
小结
步步演进讲到在standalone模式下,如何利用zookeeper来实现ha。从中可以看出standalone master一个最主要的任务就是resource management和job scheduling,看到这两个主要功能的时候,您也许会想到这不就是YARN要解决的问题。对了,从本质上来说standalone是yarn的一个简化版本。
本系列下篇内容就要仔细讲讲spark部署到YARN上的实现细节。
参考资料
Spark Standalone Mode http://spark.apache.org/docs/latest/spark-standalone.html
Cluster Mode Overview http://spark.apache.org/docs/latest/cluster-overview.html