最大熵模型
最大熵模型
最大熵原理:
学习概率模型时,在所有的可能概率模型(分布)中,熵最大的模型是最好的模型。通常根据约束条件来确定概率模型的集合,所以也可理解为:在满足约束条件的模型集合中选取熵最大的模型。
假设离散随机变量 X 的概率分布是 P(X) ,则其熵是:
H(P)=−∑xP(x)logP(x)
熵满足不等式: 0<=H(P)<=log|X|
其中 |X| 是 X 的取值个数,当且仅当 X 的分布是均匀分布时候右边等号成立,也就是说 X 服从均匀分布时候,熵最大。
简单的理解是:最大熵原理是要选择的概率模型在满足已知事实的情况下,那些不确定的部分,被认为是”等可能的”。
最大熵模型的定义
假设分类模型是一个条件概率分布![]() 表示输出,分别表示输入集合和输出集合。这个模型可以理解为:对于给定的输入 X ,以条件概率 P(Y|X) 输出 Y
表示输出,分别表示输入集合和输出集合。这个模型可以理解为:对于给定的输入 X ,以条件概率 P(Y|X) 输出 Y
给定训练数据集:
学习的目的是根据最大熵原理选出最好的分类模型,使各类数据尽可能的分开。
首先考虑模型满足的条件。给定训练集,可以确定联合分布 P(X,Y) 的经验分布和边缘分布 P(X) 的经验分布,分布以 P^(X,Y)和P^(X) 表示。

其中, v(X=x,Y=y) 表示训练数据中样本 (x,y) 出现的频数, v(X=x) 表示训练数据中输入 x 出现的频数, N 表示训练样本的容量.
定义特征函数 f(x,y) 描述输入 x 和输出 y 之间的某一个事实,其定义是
特征函数 f(x,y) 关于经验分布 P^(X,Y) 的期望值,用 EP^(f) 表示: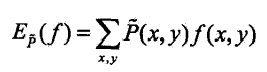
特征函数 f(x,y) 关于模型 P(Y|X) 与经验分布 P^(X) 的期望值,用 EP(f) 表示:
如果模型能够很好的获取训练数据中的信息,即: P(y|x) 能够很好的表示 P^(x,y) ,可以假设上面的两个期望是相等的,即:
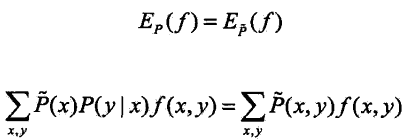
上式可作为模型学习的约束条件。如果有n分特征函数 fi(x,y),i=1,2,...,n ,那么就有n个约束条件。
最大熵模型
假设满足所有约束条件的模型集合是:
![]()
定义在条件概率分布 P(Y|X) 上的条件熵为:

则,模型集合 C 中的条件熵 H(P) 最大的模型称为最大熵模型,上面的对数是自然对数。
最大熵模型的学习
最大熵模型的学习过程是求解最大熵模型的过程,最大熵模型的学习可以形式化为满足约束条件下的最优化问题
根据上式,对于给定的训练数据集![]() 以及特征函数 fi(x,y),i=1,2,3,...n ,最大熵模型的学习等价约束最优问题:
以及特征函数 fi(x,y),i=1,2,3,...n ,最大熵模型的学习等价约束最优问题:
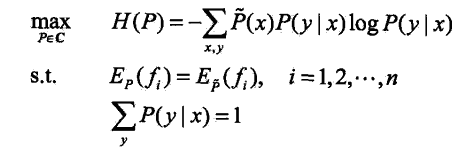
求解最大化问题可以转化为求解最小化问题:
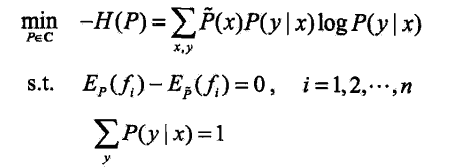
推导过程
根据拉格朗日乘子法可以将有约束问题的最优问题转化为无约束最优问题
由于拉格朗日函数 L(P,w) 是 P 的凸函数,原始问题的解,与对偶问题的解等价,就可以通过求对偶问题来求解原问题。
先求对偶问题内部的极小化问题,它是关于 w 的函数,将其记住: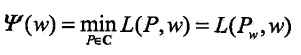
Zw(x) 称为规范化因子; fi(x,y) 是特征函数; wi 是特征的权值, Pw=Pw(y|x) 就是在参数 w 下的最大熵模型。
之后求解对偶问题外部的最大化问题:

这样,可应用最优化算法求对偶问题![]() 的极大化,得到 w∗ ,用来表示 P∗ 属于 C ,这样得到的 P∗=Pw∗=Pw∗(y|x) 就是学习到的最大熵模型。也就是说最大熵模型转化为对
的极大化,得到 w∗ ,用来表示 P∗ 属于 C ,这样得到的 P∗=Pw∗=Pw∗(y|x) 就是学习到的最大熵模型。也就是说最大熵模型转化为对![]() 的极大化问题。
的极大化问题。
终结
最大熵模型学习归结为以似然函数为目标函数的最优化问题,可通过迭代算法求解,从最优化的观点看,这时的目标函数是凸函数,存在全局最优解,可根据迭代尺度法,梯度下降法,牛顿法,拟牛顿法等求解。
在李航的统计学习方法中,还讲了对偶函数的极大化等价于最大熵模型的极大似然估计,以及求解目标函数的改进的迭代尺度法和BFGS算法,这个就不多说了,这个之前在最优化理论与算法的课程中我也学过。