Project Savanna:让Hadoop运行在OpenStack之上
摘自:http://www.csdn.net/article/2013-04-19/2814960-savanna-let-hadoop-run-on-openstack
摘要:Hadoop基本上已成为MapReduce实现的产业标准,并为众多机构采用;Savanna则是让用户可以在OpenStack上运行和管理Hadoop集群,而用户做的仅是给Savanna提供一些相关的配置参数。
Apache Hadoop基本上已经成为MapReduce实现的产业标准,并且被各个机构广泛采用,而Savanna项目旨在让用户可以在OpenStack上运行和管理Hadoop集群。值得一提的是,Amazon通过EMR(Elastic MapReduce)提供Hadoop服务已达数年之久。
用户需要给Savanna提供一些信息来建立集群,比如Hadoop版本、集群拓扑、节点硬件详情以及一些其它的信息。在用户提供这些参数之后,Savanna将帮助用户在几分钟之内建立起集群,同样还可以帮助用户根据需求对集群进行扩展(增加或者删除工作节点)。
方案针对以下几种用例:
- 为Dev和QA快速配置Hadoop集群
- 利用通用OpenStack IaaS云中从未使用过的计算能力
- 为专用或突发性的分析负载提供“分析即服务”(类似AWS中的EMR)。
主要特性如下:
- 作为OpenStack组件出现
- 通过REST API进行管理,用户界面作为OpenStack Dashboard的一部分。
- 支持多种Hadoop分布:
- 作为Hadoop安装引擎的可插拔系统。
- 集成了提供商特定的管理工具,比如Apache Ambari或者Cloudera Managent Console。
- Hadoop配置的预定义模板来,具备配置参数功能。
Savanna REST API和定制Horizon视频链接: YouTube视频
细节说明
Savanna产品主要于以下几个OpenStack组件进行通信:
- Horizon——提供GUI以使用所有Savanna的特性。
- Keystone——认证用户并提供安全令牌,用以与OpenStack通信,用以给用户分配特定的OpenStack权限。
- Nova——为Hadoop集群配置虚拟机。
- Glance——用于储存Hadoop虚拟机镜像,每个镜像都包含了已安装的OS和Hadoop;预安装的Hadoop应该给予我们在节点布置上的便利。
- Swift——可以作为需要进行Hadoop作业的预存储。
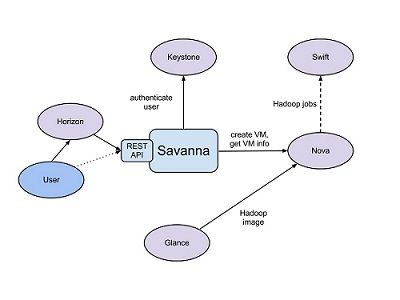
常规工作流
Savanna会根据用例给用户提供两种不同抽象等级的API和UI:集群配置和分析作为服务。
集群快速配置的工作流程包括以下选项:
- 选择Hadoop版本
- 选择包含或者不包含预安装Hadoop的基础镜像
- 对于未预安装Hadoop的基础镜像,Savanna将提供整合了供应商工具的可插拔部署引擎。
- 定义集群配置,包括集群的大小和拓扑,并且设置不同的Hadoop参数(比如heap大小)。
- 将提供可配置的模板用以简易参数配置机制。
- 集群的配置:Savanna将提供虚拟机,安装和配置Hadoop。
- 集群上的操作:添加和移除节点。
- 在不需要时终止集群。
对于分析即服务的工作流程包括以下选项:
- 选择一个预定义版本
- 配置作业:
- 选择作业的类型:pig、hive、jar-file等等
- 提供作业脚本源或者是jar路径
- 选择输入和输出数据路径(最初只支持Swift)
- 为日志选择路径
- 设置集群大小限制
- 执行作业:
- 所有集群配置和作业执行都会清楚的呈现给用户
- 作业结束后会自动移除集群
- 取回计算结果(比如从Swift)
用户方面
在使用Savanna配置集群时,用户在两种类型实体上进行操作:Node Template和Cluster。
Node Template用于描述集群中的节点,包含了几个参数。节点类型就属于Node Template的属性之一,这将决定Hadoop将在节点上运行什么样的处理,确定节点在集群中的扮演的角色,它可以是Job Tracker、NameNode、TaskTracker、DataNode或者这些节点的逻辑组合。Node Template同样还保存了硬件参数,这些参数用于节点虚拟机以及Hadoop在节点上的工作内容。
Cluster实体用于描述Hadoop Cluster,描述了预装Hadoop虚拟机特征,用于集群的部署和集群拓扑。拓扑是节点模板和每个模板该部署节点数量的列表。关于拓扑,Savanna会验证集群中的NameNode和JobTracker是否唯一。
每个节点模板和集群都归属于用户给其分配的tenant,用户只能访问已接入tenant里面的对象。用户只能编辑或删除他们建立的对象,当然管理员用户可以访问所有的对象,Savanna需要遵守同样的OpenStack访问策略。
Savanna提供了多种Hadoop集群拓扑,Job Tracker和NameNode进程可以选择在一或两个独立的虚拟机上运行。同样集群可以包含多种类型的工作节点,工作节点可以同时充当TaskTracker和DataNode,同样也可以扮演一个角色。Savanna允许用户任意选项的组合去建立集群。
与Swift整合
在OpenStack中,Swift作为标准对象存储,类似Amazon S3。通常部署在实体主机上,Swift被作为“OpenStack上的HDFS”,具备很多使用的增强功能。
首先为Swift实现的文件系统: HADOOP-8545,这样的话Hadoop作业就可以运行在Swift上。在Swift方面,我们必须将请求更改为 Change I6b1ba25b。它将端点映射为Object、Account或者是Container列表,这样就可以将Swift与依赖数据位置信息的软件整合,从而达到避免网络开销。
可插拔部署和监控
监视功能来自供应商定制的Hadoop管理工具,Savanna整合了类似Nagios及Zabbix可插拔外部监视系统。
部署和监控工具都将被安装在独立的虚拟机上,从而允许单一的实例同时管理或监控不同的集群。
原文链接: Savanna (编译/仲浩 审校/王旭东)
“ 第五届中国云计算大会 ”将于2013年6月5-7日在北京国家会议中心隆重举行。猛击报名!
相关活动已经火热启动:
2013中国云计算大调查,每周大奖等你拿! “
Innovation Cloud 2013云创新产品与应用项目征集,欢迎研发者、团队和创业企业参加!