hadoop
1:Hadoop 版本: CDH3U5
| 本框内容为转载 系统 从CDH3b3开始不支持hadoop.job.ugi参数,请使用UserGroupInformation.doAs()方法代替。详细见我博客:http://heipark.iteye.com/blog/1178810 其它见:https://ccp.cloudera.com/display/CDHDOC/Incompatible+Changes
安装
· cloudera CDH3基于hadoop稳定版0.20.2,并集成很多补丁(patch) · CDH提供rpm包和tar两种方式(cloudera更推荐使用rpm方式,下文所述CDH默认为rpm安装方式),hadoop0.20.2只提供了tar包安装方式, · cloudera CDH3 自动设置JAVA_HOME环境变量,apache hadoop需要手工配置 · apache hadoop使用start/stop-dfs.sh start/stop-all.sh脚本维护集群,CDH通过root身份运行/etc/init.d/hadoop-0.20-* 脚本启动、关闭服务,这种方式只可以管理当前服务器,如果希望实现类似start/stop-all.sh需要自己写脚本(详细见我博客:http://heipark.iteye.com/blog/1182223) · CDH3安装成功后会添加两个用户:hdfs(hdfs文件系统相关), mapred(mapreduce相关),而apache hadoop大家通常的做法是添加一个hadoop用户来做所有的事情。 · CDH通过alternatives切换多个配置文件,而apache hadoop配置文件只保存在$HADOOP_HOME/conf下面
eclipse插件 cloudera CDH默认没有提供eclipse插件,需要自己编译,而且它的插件和apache hadoop插件不兼容
安全 CDH3支持Kerberos安全认证,apache hadoop则使用简陋的用户名匹配认证
|
2:Java: jdk-6u43-linux-x64.bin
shell下 ./ jdk-6u43-linux-x64.bin安装java并设置JAVA_HOME PATH环境变量
3:ssh授信:
| root@hadoop-master:/hadoop# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 27:32:44:ea:34:74:b4:64:c2:2d:fb:d5:3f:e6:82:48 root@hadoop-master The key's randomart image is: +--[ RSA 2048]----+ | .oo* | | .oB.. | | +oo . | | o.o . . | | ..o.S .. | | Eo o + | | . . . o . | | . . . . | | . | +-----------------+ root@hadoop-master:/hadoop# cp /root/.ssh/id_rsa id_rsa id_rsa.pub root@hadoop-master:/hadoop# cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys 然后将id_rsa.pub内容添加到slave机器的/root/.ssh/authorized_keys最后即可 |
hadoop
| 参照 https://ccp.cloudera.com/display/CDHDOC/CDH3+Installation#CDH3Installation-DebianPackage
root@hadoop-slave:/hadoop# apt-cache search hadoop ubuntu-orchestra-modules-hadoop - Modules mainly used by orchestra-management-server flume - reliable, scalable, and manageable distributed data collection application flume-ng - reliable, scalable, and manageable distributed data collection application hadoop-0.20 - A software platform for processing vast amounts of data hadoop-0.20-conf-pseudo - Pseudo-distributed Hadoop configuration hadoop-0.20-datanode - Data Node for Hadoop hadoop-0.20-doc - Documentation for Hadoop hadoop-0.20-fuse - HDFS exposed over a Filesystem in Userspace hadoop-0.20-jobtracker - Job Tracker for Hadoop hadoop-0.20-namenode - Name Node for Hadoop hadoop-0.20-native - Native libraries for Hadoop (e.g., compression) hadoop-0.20-pipes - Interface to author Hadoop MapReduce jobs in C++ hadoop-0.20-sbin - Server-side binaries necessary for secured Hadoop clusters hadoop-0.20-secondarynamenode - Secondary Name Node for Hadoop hadoop-0.20-source - Source code for Hadoop hadoop-0.20-tasktracker - Task Tracker for Hadoop hadoop-hbase - HBase is the Hadoop database hadoop-hbase-doc - Documentation for HBase hadoop-hbase-master - HMaster is the "master server" for a HBase hadoop-hbase-regionserver - HRegionServer makes a set of HRegions available to clients hadoop-hbase-rest - The Apache HBase REST gateway hadoop-hbase-thrift - Provides an HBase Thrift service hadoop-hive - A data warehouse infrastructure built on top of Hadoop hadoop-hive-hbase - Provides integration between Apache HBase and Apache Hive hadoop-hive-metastore - Shared metadata repository for Hive hadoop-hive-server - Provides a Hive Thrift service hadoop-pig - A platform for analyzing large data sets using Hadoop hadoop-zookeeper - A high-performance coordination service for distributed applications. hadoop-zookeeper-server - This runs the zookeeper server on startup. hue-common - A browser-based desktop interface for Hadoop hue-filebrowser - A UI for the Hadoop Distributed File System (HDFS) hue-jobbrowser - A UI for viewing Hadoop map-reduce jobs hue-jobsub - A UI for designing and submitting map-reduce jobs to Hadoop hue-plugins - Plug-ins for Hadoop to enable integration with Hue hue-shell - A shell for console based Hadoop applications libhdfs0 - JNI Bindings to access Hadoop HDFS from C libhdfs0-dev - Development support for libhdfs0 mahout - A set of Java libraries for scalable machine learning. oozie - A workflow and coordinator sytem for Hadoop jobs. sqoop - Tool for easy imports and exports of data sets between databases and HDFS cdh3-repository - Cloudera's Distribution including Apache Hadoop |
部署
| 10.0.0.123 hadoop-master 10.0.0.125 hadoop-slave
Master:
Slave: apt-get install hadoop-0.20-datanode apt-get install hadoop-0.20-tasktracker
|
| root@hadoop-slave:/hadoop# apt-get install hadoop-0.20 hadoop-0.20-native Reading package lists... Done Building dependency tree Reading state information... Done The following extra packages will be installed: liblzo2-2 libzip1 The following NEW packages will be installed: hadoop-0.20 hadoop-0.20-native liblzo2-2 libzip1 0 upgraded, 4 newly installed, 0 to remove and 90 not upgraded. Need to get 34.2 MB of archives. After this operation, 56.0 MB of additional disk space will be used. Do you want to continue [Y/n]? y Get:1 http://archive.cloudera.com/debian/ lucid-cdh3/contrib hadoop-0.20 all 0.20.2+923.421-1~lucid-cdh3 [33.8 MB] Get:2 http://us.archive.ubuntu.com/ubuntu/ oneiric/main liblzo2-2 amd64 2.05-1 [52.2 kB] Get:3 http://us.archive.ubuntu.com/ubuntu/ oneiric/main libzip1 amd64 0.9.3-1 [23.7 kB] Get:4 http://archive.cloudera.com/debian/ lucid-cdh3/contrib hadoop-0.20-native amd64 0.20.2+923.421-1~lucid-cdh3 [341 kB] Fetched 34.2 MB in 9min 15s (61.6 kB/s) Selecting previously deselected package liblzo2-2. (Reading database ... 185899 files and directories currently installed.) Unpacking liblzo2-2 (from .../liblzo2-2_2.05-1_amd64.deb) ... Selecting previously deselected package libzip1. Unpacking libzip1 (from .../libzip1_0.9.3-1_amd64.deb) ... Selecting previously deselected package hadoop-0.20. Unpacking hadoop-0.20 (from .../hadoop-0.20_0.20.2+923.421-1~lucid-cdh3_all.deb) ... Selecting previously deselected package hadoop-0.20-native. Unpacking hadoop-0.20-native (from .../hadoop-0.20-native_0.20.2+923.421-1~lucid-cdh3_amd64.deb) ... Processing triggers for man-db ... Setting up liblzo2-2 (2.05-1) ... Setting up libzip1 (0.9.3-1) ... Setting up hadoop-0.20 (0.20.2+923.421-1~lucid-cdh3) ... find: `/var/log/hadoop-0.20/userlogs': No such file or directory update-alternatives: using /etc/hadoop-0.20/conf.empty to provide /etc/hadoop-0.20/conf (hadoop-0.20-conf) in auto mode. update-alternatives: using /usr/bin/hadoop-0.20 to provide /usr/bin/hadoop (hadoop-default) in auto mode. Setting up hadoop-0.20-native (0.20.2+923.421-1~lucid-cdh3) ... Processing triggers for libc-bin ... ldconfig deferred processing now taking place root@hadoop-slave:/hadoop# apt-get install hadoop-0.20-datanode Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: hadoop-0.20-datanode 0 upgraded, 1 newly installed, 0 to remove and 90 not upgraded. Need to get 276 kB of archives. After this operation, 352 kB of additional disk space will be used. Get:1 http://archive.cloudera.com/debian/ lucid-cdh3/contrib hadoop-0.20-datanode all 0.20.2+923.421-1~lucid-cdh3 [276 kB] Fetched 276 kB in 3s (81.2 kB/s) Selecting previously deselected package hadoop-0.20-datanode. (Reading database ... 186341 files and directories currently installed.) Unpacking hadoop-0.20-datanode (from .../hadoop-0.20-datanode_0.20.2+923.421-1~lucid-cdh3_all.deb) ... Processing triggers for ureadahead ... ureadahead will be reprofiled on next reboot Setting up hadoop-0.20-datanode (0.20.2+923.421-1~lucid-cdh3) ... root@hadoop-slave:/hadoop# apt-get install hadoop-0.20-tasktracker Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: hadoop-0.20-tasktracker 0 upgraded, 1 newly installed, 0 to remove and 90 not upgraded. Need to get 276 kB of archives. After this operation, 352 kB of additional disk space will be used. Get:1 http://archive.cloudera.com/debian/ lucid-cdh3/contrib hadoop-0.20-tasktracker all 0.20.2+923.421-1~lucid-cdh3 [276 kB] Fetched 276 kB in 4s (66.4 kB/s) Selecting previously deselected package hadoop-0.20-tasktracker. (Reading database ... 186347 files and directories currently installed.) Unpacking hadoop-0.20-tasktracker (from .../hadoop-0.20-tasktracker_0.20.2+923.421-1~lucid-cdh3_all.deb) ... Processing triggers for ureadahead ... Setting up hadoop-0.20-tasktracker (0.20.2+923.421-1~lucid-cdh3) ... |
修改配置文件
略,参照http://heylinux.com/archives/2002.html
格式化HDFS分布式文件系统
| root@hadoop-master:/hadoop# sudo -u hdfs hadoop namenode -format 13/03/05 07:17:46 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-master/10.0.0.123 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2-cdh3u5 STARTUP_MSG: build = file:///data/1/tmp/nightly_2012-10-05_17-10-50_3/hadoop-0.20-0.20.2+923.421-1~lucid -r 30233064aaf5f2492bc687d61d72956876102109; compiled by 'root' on Fri Oct 5 18:46:24 PDT 2012 ************************************************************/ 13/03/05 07:17:46 INFO util.GSet: VM type = 64-bit 13/03/05 07:17:46 INFO util.GSet: 2% max memory = 19.33375 MB 13/03/05 07:17:46 INFO util.GSet: capacity = 2^21 = 2097152 entries 13/03/05 07:17:46 INFO util.GSet: recommended=2097152, actual=2097152 13/03/05 07:17:46 INFO namenode.FSNamesystem: fsOwner=hdfs (auth:SIMPLE) 13/03/05 07:17:46 INFO namenode.FSNamesystem: supergroup=supergroup 13/03/05 07:17:46 INFO namenode.FSNamesystem: isPermissionEnabled=true 13/03/05 07:17:46 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=1000 13/03/05 07:17:46 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 13/03/05 07:17:47 INFO common.Storage: Image file of size 110 saved in 0 seconds. 13/03/05 07:17:47 INFO common.Storage: Storage directory /hadoop/data/storage/dfs/name has been successfully formatted. 13/03/05 07:17:47 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/10.0.0.123 ************************************************************/ |
启动master的hadoop
| sudo /etc/init.d/hadoop-0.20-datanode start sudo /etc/init.d/hadoop-0.20-namenode start sudo /etc/init.d/hadoop-0.20-jobtracker start sudo /etc/init.d/hadoop-0.20-secondarynamenode start |
| root@hadoop-master:/hadoop# sudo /etc/init.d/hadoop-0.20-datanode start Starting Hadoop datanode daemon: starting datanode, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-datanode-hadoop-master.out hadoop-0.20-datanode. root@hadoop-master:/hadoop# sudo /etc/init.d/hadoop-0.20-namenode start Starting Hadoop namenode daemon: starting namenode, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-namenode-hadoop-master.out hadoop-0.20-namenode. root@hadoop-master:/hadoop# sudo /etc/init.d/hadoop-0.20-jobtracker start Starting Hadoop jobtracker daemon: starting jobtracker, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-jobtracker-hadoop-master.out ERROR. Could not start Hadoop jobtracker daemon root@hadoop-master:/hadoop# sudo /etc/init.d/hadoop-0.20-secondarynamenode start Starting Hadoop secondarynamenode daemon: starting secondarynamenode, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-secondarynamenode-hadoop-master.out hadoop-0.20-secondarynamenode. root@hadoop-master:/hadoop# |
|
|
|
|
启动slave的hadoop
|
|
| root@hadoop-slave:/hadoop# sudo /etc/init.d/hadoop-0.20-datanode start Starting Hadoop datanode daemon: starting datanode, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-datanode-hadoop-slave.out hadoop-0.20-datanode. root@hadoop-slave:/hadoop# sudo /etc/init.d/hadoop-0.20-tasktracker start Starting Hadoop tasktracker daemon: starting tasktracker, logging to /usr/lib/hadoop-0.20/logs/hadoop-hadoop-tasktracker-hadoop-slave.out hadoop-0.20-tasktracker. root@hadoop-slave:/hadoop# |
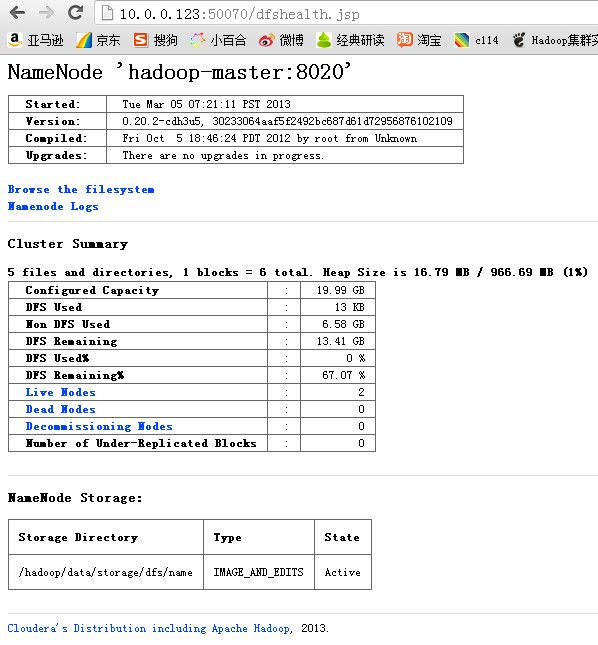

后续hbase