Tex中的正则表达式替换
本人在用Tex写论文时,碰到要将\textbf{NumEQ},\textbf{NumBC},\textbf{Err[k]}这样的字符串全部相应地转换成\verb|NumEQ|, \verb|NumBC|, \verb|Err[k]|。因为文章中有大量地方需要修改,手动修改机耗时又可能漏掉,最终采用正则表达式替换修改。
对被替换的字符换描述为:
\\textbf\{\(*\)\}
转化后的字符串描述为:
\\verb\|\0\|
说明:
1. \是转义字符,将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。
2. *匹配任意字符串(包括空串)。
3. \(*\)\ 将这些匹配成功的字符串标记为\0,这样可以在之后的替换模式表达式中引用它。
4. \0 表示对前面匹配的引用。
在WinEdt中的样图如下:
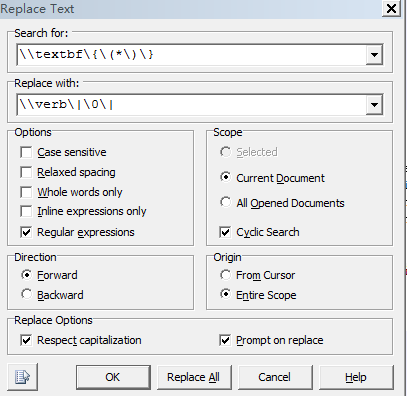
注意:WinEdt中的正则表达式和GUN上的有区别,用时需要注意。
GNU vs. WinEdt
WinEdt regular expressions for GNU regular expressions users
by Denis Stancer
Philosophy
GNU regular expressions have mainly the following form:
<qualifier><quantifier>
where qualifier means WHAT and quantifier means HOW MANY. GNU has only one quantifier:
{m,n} = minimally m times and maximally n times
There are several quantifier synonyms:
* = {0,} + = {1,} ? = {0,1}
If a quantifier is left out it means {1,1}, i.e {1}.
WinEdt has the reverse philosophy. Its regular expressions are mainly:
<quantifier><qualifier>
WinEdt has two quantifiers:
+ = 1 or more times @ = 0 or more times
Comparison
NSM - No Special Meaning - any non-special expression
Exp GNU meaning WinEdt meaning
. Matches any single character Matches any single character (possibly none)
* Prev.exp. must occur 0 or more times Matches any string (including empty)
+ Prev.exp. must occur 1 or more times Matches any (non-zero) number of next exp.
? Prev.exp. must occur 0 or 1 time Matches any (non-zero) single character
$ Matches end of a line (In pair) Alternative Set Definition
^ Matches the start of a line not + Skip Next Pattern
> NSM Matches the end of a line
< NSM Matches the start of a line
[ ] Set Set
[-] Range Range
\(\) NSM - Matches () Tagged Expression
(x in the range 0..9; 0 is a default)
() Tagged Expression and group NSM - Matches )
\x Tag backreference (0..9) Tag backreference (0..9)
$x Tag (x in the range 0..9) NSM - In fact error
{n,m} universal quantifier: {n,m} prev. exp Group
must occur min. n and max. m times
\y Matches character y itself (exl. 1-9) Matches character y itself (exl. 0-9)
| Alternation (or) Alternation (or)
@ NSM (matches @) Matches any number of occurrences of
the next expression
\I NSM (matches I) initial case in backreference \I1
\T NSM (matches T) toggle case in backreference \T1
\t tab NSM (matches t)
\n newline NSM (matches n)
\r return NSM (matches r)
\f form feed NSM (matches a)
\a alarm (bell) NSM (matches e)
\e escape NSM (matches r)
\ octal char NSM (interpreted as \0})
\ hex char NSM (matches )
\ control char NSM (matches )
\l lowercase next char NSM (matches l)
\u uppercase next char NSM (matches u)
\L lowercase till \E lowercase backreference
\L1
\U uppercase till \E uppercase backreference
\U1
\E end case modification NSM (matches E)
\Q disable pattern metacharacters NSM (matches Q)
till \E
\w Match a word (alphanumeric plus "_") NSM (matches w)
\W Match a non-word character NSM (matches W)
\s Match a whitespace character NSM (matches s)
\S Match a non-whitespace character NSM (matches S)
\d Match a digit character NSM (matches d)
\D Match a non-digit character NSM (matches D)
Translation
GNU quantifier WinEdt quantifier
{m,n} N/A
* @
+ +
? N/A (use @)
GNU qualifier WinEdt qualifier
| |
. . or ?
$ >
^ <
] ]
] ]
[] ~]
) \(\) (x in range 0..9)
\x or $x \x (x in range 1..9 for GNU and 0..9 for WinEdt)
(excluding 1..9 for GNU and 0..9 for WinEdt)
\w $Alpha+Numeric+["_"]$
\W $~(Alpha+Numeric+["_"])$
\s $[" "]+[#9]+[#13]+[#10]$
\S $~([" "]+[#9]+[#13]+[#10])$
\d $Numeric$ or [0-9]
\D $~Numeric$ or ~[0-9]
\t $[#89]$
\n $[#13]$ or >
\r $[#13]$
\f $[#10]$
\a $[#]$
\e $[#]$
GNU modifier WinEdt modifier
\ ???
\ ???
\cX $[#x]$ (X is a letter and x is a number)
\l N/A (use \Lx x in range 0..9)
\u N/A (use \Ux x in range 0..9)
\L N/A (use \Lx x in range 0..9)
\U N/A (use \Ux x in range 0..9)
\E N/A
\Q N/A
Examples:
1. Replace any 3 letter word that has "at" at the end with fat:
GNU WinEdt Search for: ".at" Search for: ".at" Replace with: "fat" Replace with: "fat"
2. Replace all 3.14 with Pi:
GNU WinEdt Search for: "3\.14" Search for: "3\.14" Replace with: "Pi" Replace with: "Pi"
Note: "3.14" would do the same thing but it would also replace numbers like 3214 or 351432.
3. Replace all numeric Pi regardless of how many decimals it has:
GNU WinEdt Search for: "3\.[0-9]+" or "3\.\d+" Search for: "3\.+[0-9]" Replace with: "Pi" Replace with: "Pi"
4. Replace all methane and ethane with alcane:
GNU WinEdt
Search for: "m?etahne" Search for: "@{m}ethane"
Replace with: "alcane" Replace with: "alcane"
5. Replace cyclopentane, isopentane, hexapentane with pentane but not n-pentane or dodecapentane:
GNU WinEdt
Search for: ".{3,5}pentane" Search for: "[cih]??{{..pentane}|{.pentane}|{pentane}}"
Replace with: "pentane" Replace with: "pentane"
6. Replace tan, man, can with try but not ban, fan or pan:
GNU WinEdt
Search for: "\b[cmt]an\b" Search for: "{<|}[cmt]an{>| }"
Replace with: "try" Replace with: "try"
7. Replace any of possible variations of Christianssen surname (Kristianssen, Kristiansson, Christiansen, Kristenssen, ...) with Xson:
GNU WinEdt
Search for: "(Ch|K)rist(ia|e)ns{1,2}[eo]n" Search for: "{Ch|K}rist{ia|e}ns@{s}[eo]n"
Replace with: "Xson" Replace with: "Xson"
8. Replace 2 or more empty lines with one:
GNU WinEdt Search for: "\n\n+" Search for: "<>+>" Replace with: "\n\n" Replace with: ">"
9. Insert ; at the end of a non-empty line:
GNU WinEdt Search for: "(\w)$" Search for: "\(^<\)>" Replace with: "\1;" Replace with: "\0;>"
10. Quote every non-empty line:
GNU WinEdt Search for: "^([^\n]+)$" Search for: "<\(+^>\)>" Replace with: ""\1"" Replace with: ""\0">"
11. Switch every two words:
GNU WinEdt Search for: "(\w+) (\w+)" Search for: "\(1+$Alpha$\) \(2+$Alpha$\)" Replace with: "$2 $1" Replace with: "\2 \1"
12. Replaces all twice repeated instances of words (a-z) separated by an arbitrary number of spaces (even across line boundaries) and replaces them with a single word.
GNU WinEdt Search for: "\b(\w+)\s+\1\b" Search for: "\(+[a-z]\)@ @>@ \0" Replace with: "\1" Replace with: "\0"
13. Replaces all repeated instances of words (a-z) separated by an arbitrary number of spaces (even across line boundaries) and replaces them with a single word.
GNU WinEdt
Search for: "\b(\w+)(\s+\1)+\b" Search for: "\(+[a-z]\)@ @>@ \0@{@ @>@ \0}"
Replace with: "\1" Replace with: "\0"
14. Escape all (La)TeX special characters:
GNU WinEdt
Search for: "(\\|\{|\}|\$|\&|\_|\^)" Search for: "\(\\|\{|\}|\$|\&|\_|\^\)"
Replace with: "\\\1" Replace with: "\\\0"
15. Capitalize all the words:
GNU WinEdt Search for: "(\w+)" Search for: "\(+$Alpha$\)" Replace with: "\u\L\1" Replace with: "\I0"
16. Replace {x \over y} with \frac{x}{y}:
GNU WinEdt
Search for: "\{(.*) \\over (.*)\}" Search for: "\{\(0*\)\\over \(1*\)\}"
Replace with: "\\frac\{\1\}\{\2\}" Replace with: "\\frac\{\0\}\{\1\}"
17. Find instances of word "label" without control prefix "\" and replace them with lbl:
GNU WinEdt
Search for: "(^|[^\\])label\b" Search for: "\(0{<|^[\\]}\)label~[a-z]"
Replace with: "\1lbl" Replace with: "\0lbl"
RegEx Examples
This section sets out some examples and includes a couple of answers to questions relating to regular expressions.
In the examples below, double quotes around the search or replacement string are not a part of the actual RegEx.
1. Find control characters in a document:
Search for: "$[#0..#31]$"
2. Find instances of the word "label" without the control prefix "\":
Search for: "#~{\\}label"
3. Find instances of "\begin", but not "\begin{figure}":
Search for: "\\begin{~\{figure\}}"
4. Match nested brackets "(...(...)...)" (up to level 6):
Search for:
"(@{>|{(@{>|{(@{>|{(@{>|{(@{>|{(*)}|^{)}}*)}|^{)}}*)}|^{)}}*)}|^{)}}*)}|^{)}}*)"
Hint: ^{expression} matches everything except "expression".This one is rather tricky...
5. RegEx Replace:
"<>>" --> ">"
replaces all double empty lines with single ones. Note, however, that such an algorithm is quadratic in nature and will not perform very well on large files. Splitting the file into smaller segments might improve it. In order to avoid the quadratic factor, the proper solution would be to search for "<>>" and rebuild the single spaced output from scratch... However, the example will work fine on reasonably small files.
6. A RegEx Replace:
"<??\>" --> "0??\>"
replaces a string "13>" positioned at the beginning of line with "013>", while the string "99>"; is replaced by "099>";. Tags should be used to perform more sophisticated replacements of this nature...
When replacing text using regular expressions, it is very useful to have a so-called "tagged expression"; i.e., that part of the "find" RegEx that can be referred to in the "replace" RegEx.
"\(x<Expression>\)" brackets a tagged expression to use in replacement expressions. One RegEx can have up to ten tagged expressions. The corresponding replacement expression is\x, for x in the range 0-9. Tagged expressions cannot be nested. If you skip a tag index after"\(" 0 is assumed.
7. A RegEx Replace:
"\(+[a-z]\) \(1+[a-z]\)" -> "\1 \0"
matches "way wrong", and replaces it with "wrong way".
8. A RegEx replace:
"\(+[a-z]\)+ \0" -> "\0"
seeks all repeated instances of words (a-z) separated by an arbitrary number of spaces, and replaces them with a single word. If you want to detect words even if they are located in two lines, you can change the search string to:
"\(+[a-z]\){{> }|{+ }|{+ >}|{>+ }|{+ >+ }}\0"
or
"\(+[a-z]\)@ @> @ \0"
Note the use of "+" (repeat) and "|" (or).
9. Replace "{x \over y}" with "\frac{x}{y}":
Search for: "\{\(0*\) \\over \(1*\)\}"
Replace with: "\\frac\{\0\}\{\1\}"
10. Suppose you want to put the escape character "\" in front "\{}" inside \begin..\end environments. This RegEx replace:
Search for: "{\(0\\begin\)\(1\{*\)\}}|{\(0\\end\)\(1\{*\)\}}"
Replace with: "\\\0\\\1\\\}"
will do this:
\begin{equation} \\begin\{equation\}
\begin{array}[ccc] \\begin\{array\}[ccc]
--->
\end{array} \\end\{array\}
\end{equation} \\end\{equation\}
11. Replace initially capitalized words with lowercase ones:
Search for: "\#~{$Alpha$}\($Upper$+$Lower$\)~{$Alpha$}"
Replace with: "\L0"
IMPORTANT: This replacement must be performed with Case sensitive option enabled in order to distinguish between lower and uppercase characters.
12. Select a LaTeX \begin{*}..\end{*} environment:
Search for: "\\begin\{*\}@{~{{@ }\\end\{*\}}{*}>}{*\\end\{*\}}"
However, this search will not yield the required results with nested environments. By using tagged expressions this problem can be addressed as well:
"\\begin{\(\{*\}\)}@{~{*\\end\0}{*}>}{*\\end\0}"
^^ tag ^^ ^label ^label
The wildcard "*" is limited to the text within one line. The above RegEx indicates how to use"@{~expression}expression" to overcome this limitation. However, using"**" significantly simplifies the above example:
Search for: "\\begin{\(\{*\}\)}**\\end\0}"
will do just fine.
The options Relaxed spacing and Inline expressions only are ignored with regular expressions, as you have different means to specify such preferences.
For example, RegEx "John{@ @>@ }Smith" matches all three instances of the string:
1. JohnSmith
2. John Smith
3. John
Smith