我的solr学习笔记--solr admin 页面 检索调试
http://www.solr.cc/blog/?p=1678 solr中国
前言
Solr/Lucene是一个全文检索引擎,全文引擎和SQL引擎所不同的是强调部分相关度高的内容返回,而不是所有内容返回,
所以部分内容包含在索引库中却无法命中是正常现象。
多数情况下我们建议优化分词器或者引擎其它部分达到预期检索效果。
-
分词器调节
按照如下步骤进入分词器调试界面
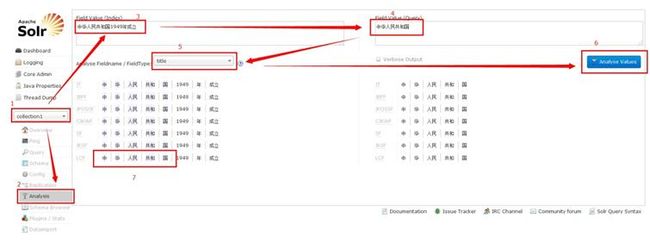
1、选择collection
2、选择analysis菜单
3、在索引框中输入要索引的文档
4、在检索框中输入要检索的词语
5、选择需要调试的字段,这里假设要将内容索引到title字段,并且在该字段上检索
6、点击分析按钮
7、在展示出来的原文分词结果(左侧)和关键词分词结果(右侧)中对比最下面一行,若右侧分词结果的所有词在左侧都能找到,那么在AND关系的检索时能够匹配;若部分能够找到,那么在OR关系的检索中能够匹配;若完全找不到,那么无法匹配。
-
检索调节
-
准备数据
-
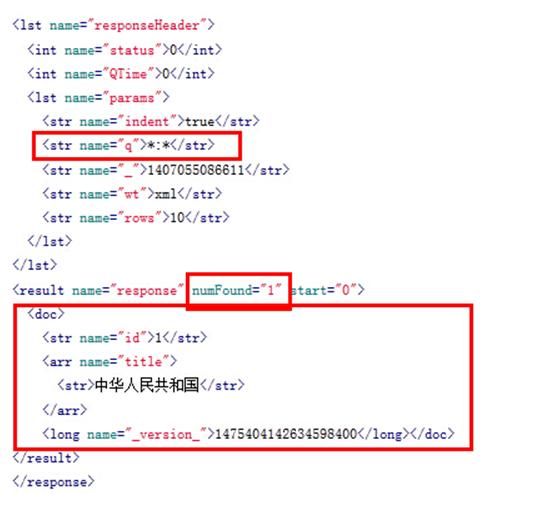
索引一条记录,id=1,title=中华人民共和国来做调试
-
直接检索无法出结果问题
直接检索中华人民共和国

从上图看(图可放大),最终检索结果被解析成了”+text:中 +text:华 +text:人 +text:民 +text:共 +text:和 +text:国”,因为我们在q的输入框中没有输入检索字段,所以solr会检索默认字段”text”,而该字段不包含我们需要的信息,所以检索无结果。
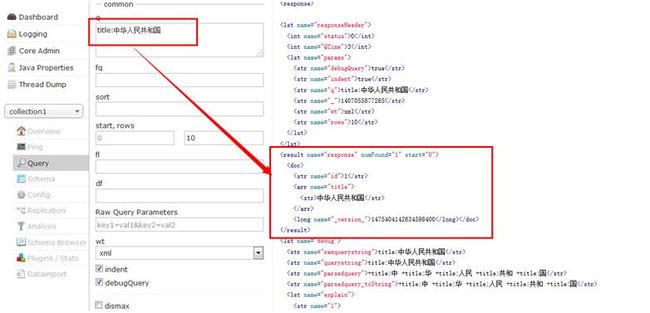
输入正确的字段title后,可以成功检索出来
-
部分匹配无法出结果问题
原文中华人民共和国分词后:中华、人民、共和国
搜索词中华解放军分词后:中华、解放军
部分匹配,我们也希望检索出来
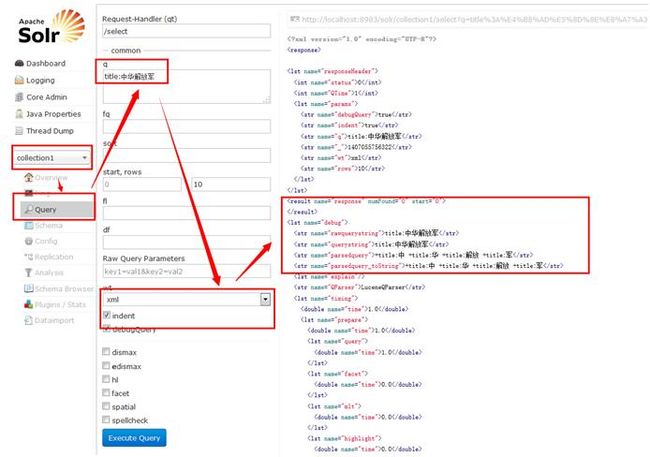
从上图看(图可放大),最终检索结果被解析成了"+title:中 +title:华 +title:解放 +title:军",加号(+)标识逻辑与关系,相当于检索"title:中 AND title:华 AND title:解放 AND title:军",因此无法检索出来
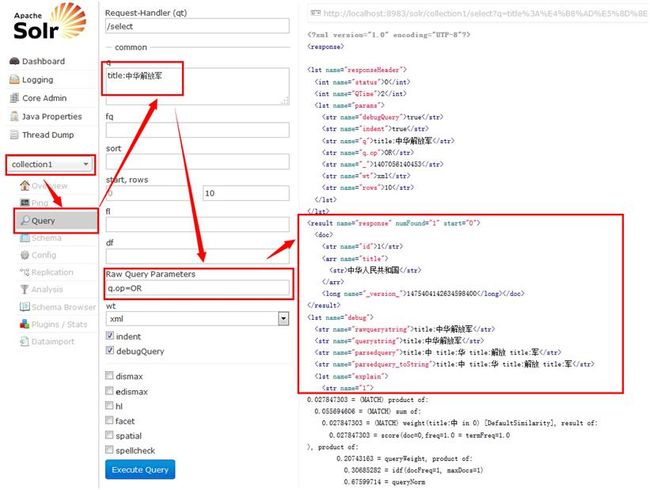
修改默认逻辑关系(q.op=OR)为OR后,分此后的检索式加号没了,是逻辑或关系,因此能够成功检索出来。这里OR一定要大写。
这个默认检索关系可以通过修改schema.xml的defaultOperator进行配置
<solrQueryParser defaultOperator=”OR”/>
-
多关键字检索无法出结果问题
有时候用户会用空格输入多个关键字进行检索,如title:中华 人民 共和国
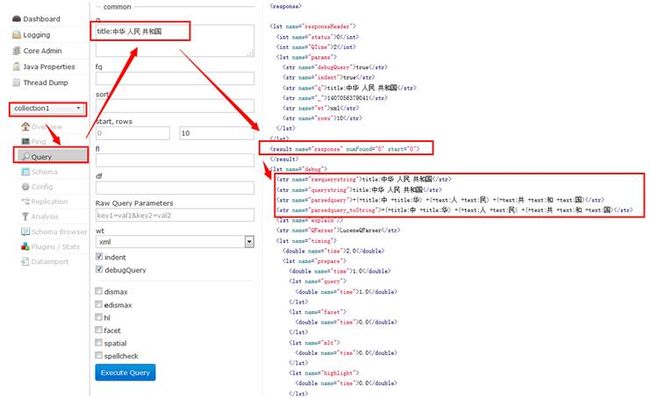
通过开启debugQuery参数,我们看到,最终检索结果被解析成了
+(+title:中 +title:华) +(+text:人 +text:民) +(+text:共 +text:和 +text:国)
中华是在title上检索的,后面的词都到text字段检索了

通过指定默认字段df为title,可以修正最终检索式,从上图看,修正后结果可以正常检索返回。
其它
以上是一些常见数据召回问题。
检索调优是搜索引擎使用中最复杂的过程,需要在长期实践中积累经验,同时需要了解数据情况,业务特点等多方面根据情况进行调整。
Solr web服务器管理界面用法
http://www.devnote.cn/article/38.html
这里列举一些常用的比较重要的内容。
Dashboard(仪表盘)
访问主页,http://你的域名或ip/solr/,默认显示此页内容,包含solr版本,包含系统内存和jvm内存的使用情况,jvm参数等

Logging(日志)
可以用来查看solr运行是否有警告或者异常,以便及时处理
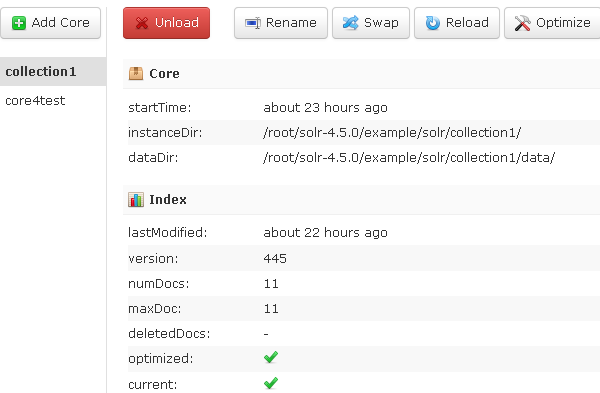
Core Admin(索引库管理)
这个界面很重要,这使多核的配置,索引库的优化等,变得非常简单;
主要功能包括:Add Core(添加核心,即索引库),Unload(卸载核心),Rename(重命名核心),Optimize(优化索引库)。如我这里是两个核心。
Java Properties(java属性)
java及tomcat的一些属性
Core Selector(核心选择器,这里以collection1为例)

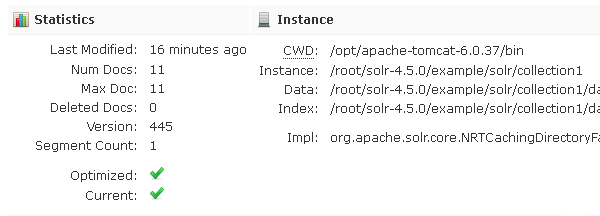
- Overview(概览):包含基本统计如当前文档数;和实例信息如当前核心的配置目录;
- Analysis(分析):检验分词效果,如图,分词后“开发”将被高亮(注意FieldType需要选定为与被分析内容类型一致,如这里的title配置了中文分词)

- Config(配置):当前核心的配置,即solrconfig.xml的内容
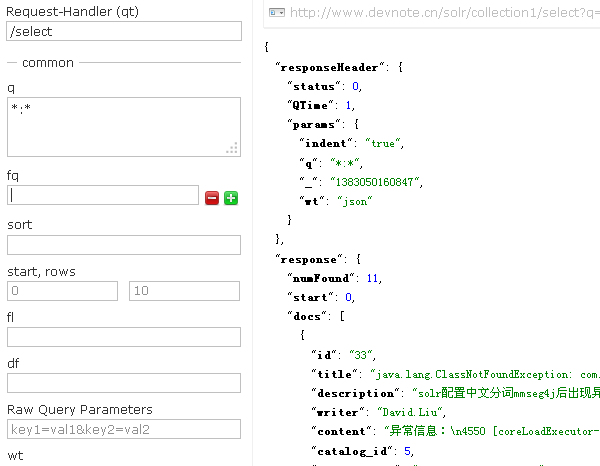
- Query(查询):这是一个查询界面,用的比较多,用来查询索引的文档,包含是否存在,排序是否正确等。
- Schema(当前索引库定义),即即schema.xml的内容
安全:因为此界面涉及到位solr增减核心等管理操作,在实际产品上运行时,尽量设置禁用在公网上(通过ip或者域名)的访问,需要使用时再临时打开。