Linux spi死锁问题
平台环境:
CPU0: P1020, Version: 1.1, (0x80e40011)
Core: E500, Version: 5.1, (0x80212051)
Clock Configuration:
CPU0:800 MHz, CPU1:800 MHz,
CCB:400 MHz,
DDR:400 MHz (800 MT/s data rate) (Asynchronous), LBC:50 MHz
L1: D-cache 32 kB enabled
I-cache 32 kB enabled
DRAM: 512 MiB (DDR3, 32-bit, CL=6, ECC off)
L2: 256 KB enabled
NAND: 1024 MiB
内核打印如下:
[root@Huahuan:/home]#INFO: task ffe07000.spi:1013 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
ffe07000.spi D 00000000 0 1013 2 0x00000000
Call Trace:
[deed1d30] [0000005a] 0x5a (unreliable)
[deed1df0] [c0007f80] __switch_to+0xa0/0xe0
[deed1e00] [c0468150] schedule+0x1e0/0x4d8
[deed1e60] [c0468824] schedule_timeout+0x1cc/0x260
[deed1ea0] [c0467e1c] wait_for_common+0xb4/0x168
[deed1ee0] [c0301428] fsl_espi_bufs+0xb8/0xdc
[deed1f00] [c0300840] bitbang_work+0x138/0x394
[deed1f50] [c005eb10] worker_thread+0x12c/0x1d0
[deed1fb0] [c0062b84] kthread+0x78/0x7c
[deed1ff0] [c0010480] kernel_thread+0x4c/0x68
INFO: task test_task:1191 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
test_task D 00000000 0 1191 2 0x00000000
Call Trace:
[dbcd5d10] [c0010d68] ret_from_except+0x0/0x18 (unreliable)
--- Exception: dbcd5de0 at __switch_to+0xa0/0xe0
LR = 0xc0a7f568
[dbcd5dd0] [c0007f80] __switch_to+0xa0/0xe0 (unreliable)
[dbcd5de0] [c0468150] schedule+0x1e0/0x4d8
[dbcd5e40] [c0468824] schedule_timeout+0x1cc/0x260
[dbcd5e80] [c0467e1c] wait_for_common+0xb4/0x168
[dbcd5ec0] [c02ff690] spi_sync+0x54/0x70
[dbcd5ef0] [c03017e0] mix_spi_write+0x10c/0x1c4
[dbcd5f70] [c0301db4] fpga_spi_write+0xa0/0xc4
[dbcd5f90] [e14620ac] fpga_thread+0xac/0xc4 [spitest]
[dbcd5fb0] [c0062b84] kthread+0x78/0x7c
[dbcd5ff0] [c0010480] kernel_thread+0x4c/0x68
INFO: task test1_task:1192 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
test1_task D 00000000 0 1192 2 0x00000000
Call Trace:
[dbcd7e00] [1ffd9d04] 0x1ffd9d04 (unreliable)
[dbcd7ec0] [c0007f80] __switch_to+0xa0/0xe0
[dbcd7ed0] [c0468150] schedule+0x1e0/0x4d8
[dbcd7f30] [c04690a4] __mutex_lock_slowpath+0x128/0x1c8
[dbcd7f60] [c0468c7c] mutex_lock+0x50/0x54
[dbcd7f70] [c0301d88] fpga_spi_write+0x74/0xc4
[dbcd7f90] [e14620ac] fpga_thread+0xac/0xc4 [spitest]
[dbcd7fb0] [c0062b84] kthread+0x78/0x7c
[dbcd7ff0] [c0010480] kernel_thread+0x4c/0x68
INFO: task spitest-fpga-wr:1194 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
spitest-fpga- D 0ff38b10 0 1194 1181 0x00000000
Call Trace:
[df5c3b70] [00000001] 0x1 (unreliable)
[df5c3c30] [c0007f80] __switch_to+0xa0/0xe0
[df5c3c40] [c0468150] schedule+0x1e0/0x4d8
[df5c3ca0] [c04690a4] __mutex_lock_slowpath+0x128/0x1c8
[df5c3cd0] [c0468c7c] mutex_lock+0x50/0x54
[df5c3ce0] [c0302ad0] spidev_ioctl+0x560/0xa7c
[df5c3e80] [c00d04c0] vfs_ioctl+0x3c/0xe4
[df5c3ea0] [c00d0738] do_vfs_ioctl+0x88/0x744
[df5c3f10] [c00d0e34] sys_ioctl+0x40/0x74
[df5c3f40] [c0010710] ret_from_syscall+0x0/0x3c
--- Exception: c01 at 0xff38b10
LR = 0xffec8a8
首先说明一下,这个问题并不是必现的,通过用户空间和内核空间长时间读写spi,几十万次甚至上千万次才可能出现
而且在spi读写处添加1ms延时就不会出现这个问题。
能看出是卡在完成量上
[dbcd5dd0] [c0007f80] __switch_to+0xa0/0xe0 (unreliable)
[dbcd5de0] [c0468150] schedule+0x1e0/0x4d8
[dbcd5e40] [c0468824] schedule_timeout+0x1cc/0x260
[dbcd5e80] [c0467e1c] wait_for_common+0xb4/0x168
[dbcd5ec0] [c02ff690] spi_sync+0x54/0x70
等待超过2分钟,内核出现的异常
根据打印的栈的函数,可以看出程序就出在spi最终的收发上,参考下文
http://blog.csdn.net/davion_zhang/article/details/50056785
那么我们就分析一下这个完成量在等待的任务为什么没有完成。还是参考下图
以bitbang_work()分开为上半段和下半段
整个spi收发阶段共有两个完成量
1.一个是在上半段spidev_sync,这是spi read write的必经之路
int spi_sync(struct spi_device *spi, struct spi_message *message)
{
DECLARE_COMPLETION_ONSTACK(done);
int status;
message->complete = spi_complete;
message->context = &done;
status = spi_async(spi, message);
if (status == 0) {
wait_for_completion(&done);
status = message->status;
}
message->context = NULL;
return status;
}其中通过
DECLARE_COMPLETION_ONSTACK(done);定义了一个存放在栈区的完成量done,将message发送到消息队列后,在
wait_for_completion(&done);等待这个消息处理完毕这个消息的完成是在下半段bitbang_work中发送完数据后关闭完成量的
m->status = status; m->complete(m->context);
2.另一个完成量是在消息发送实例中
fsl_espi_bufs
INIT_COMPLETION(fsl_espi->done); /* enable rx ints */ out_be32(&fsl_espi->regs->mask, SPIM_NE); /* transmit word */ word = fsl_espi->get_tx(fsl_espi); out_be32(&fsl_espi->regs->transmit, word); wait_for_completion(&fsl_espi->done);fsl_espi_irq
} else {
fsl_espi->count = 0;
/* disable rx ints */
out_be32(&fsl_espi->regs->mask, 0);
complete(&fsl_espi->done);
}
概图如下:
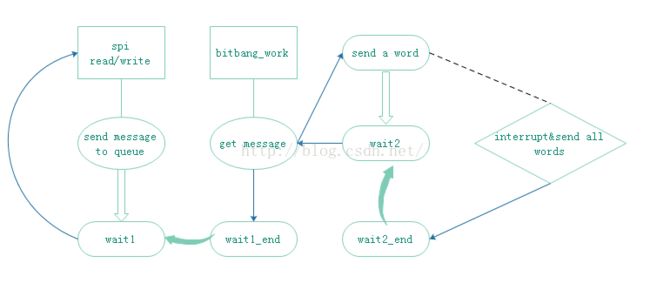
最先打印的问题是在wait2的地方,所以判断wait2_end没有执行
也就是中断这块出了问题
通过调试中断处理部分,发现中断处理并没有问题,只是单纯的没有中断进来
解决:
后来通过打印异常时spi各寄存器的状态发现 spi mode寄存器的en为0,说明spi已经disable了
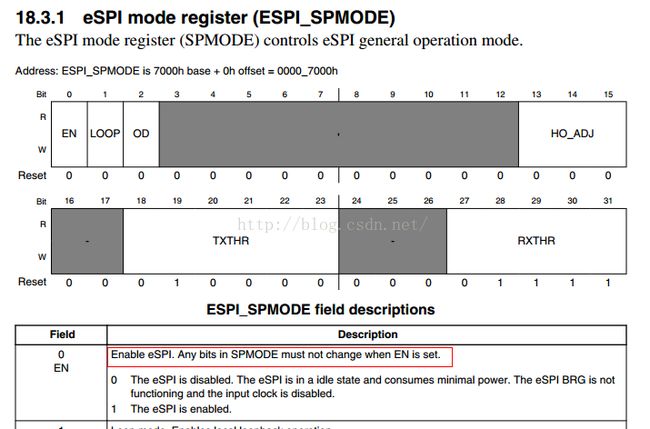
具体定位到代码,函数fsl_espi_setup_transfer,每一次spi作为master向slave发送数据时,都要配置spi的csmode,csmode类似mode的扩展寄存器,用以配置每个cs片选时master的配置要求,如slave要求的时钟频率,时钟相位等,通过SPCOM寄存器的cs来选择具体的csmode。有的spi模块只有一个mode寄存器,没有csmode。

具体看一下spi的开关部分
cs->hw_mode |= CSMODE_PM(pm); /* Reset the hw mode */ regval = in_be32(&fsl_espi->regs->mode); local_irq_save(flags); /* Turn off SPI unit prior changing mode */ <strong>out_be32(&fsl_espi->regs->mode, regval & ~SPMODE_ENABLE);</strong> out_be32(&fsl_espi->regs->csmode[cs_sel], cs->hw_mode); <strong>out_be32(&fsl_espi->regs->mode, regval);</strong> local_irq_restore(flags);
其实从SPMODE的EN中的说明来看,每次配置csmode没有必要开关EN,只有SPMODE修改时才需要
从代码角度上看没有问题,但长时间高频率的修改SPMODE导致某一次
out_be32(&fsl_espi->regs->mode, regval);
失效,EN变为0后没有改回1导致spi关闭(P1020的问题)
而实际上目前我们的slave的cs要求都一样,没必要每次都要改动,所以将这个配置放在spi初始化阶段后,问题得以解决。