Hibernate框架详解(二)POJO对象的操作
POJO对象其实就是我们的实体,这篇博客总结一下框架对POJO对象对应数据库主键的生成策略,和一些对POJO对象的简单增删改查的操作。
一,Hibernate框架中主键的生成策略有三种方式:
1,数据库负责生成主键(代理主键)
a,native:表示由设置的方言决定采用什么数据库生成主键方式,例如:在MySQL中会采用自增长的方式,主键字段必须都是整形类型;在Oracle数据库中,会采用序列的增长方式。
b,sequence:表示采用数据库的序列生成主键,适用于Oracle,DB2数据库中。
c,identity:表示采用自增长的主键生成方式,适用于MySQL,SQL Server中。
2,Hibernate框架负责生成主键值(代理主键):
a,increment:表示由框架本身提供计数器,累加数据,获取主键。
b,uuid:由框架根据参数(IP地址,JVM虚拟机启动时间,系统时间,计数器等)生成32位16进制的数字字符串。
3,用户提供主键值(自然主键):
Assigned:业务(自己)提供主键。
当然这里常用的是native,uuid和Assigned三值。在设置POJO类与表映射时,进行主键设置,标签为<id>,在其中的<generator>标签中进行设置,例如:
- <!--
- id标签用来映射主键字段
- name属性表示类的属性
- column属性表示表的字段
- -->
- <id name="usercode" column="usercode" length="32" type="java.lang.String">
- <!-- 主键生成策略 -->
- <generator class="assigned"/>
- </id>
二,Hibernate框架下的POJO对象的三种状态:
1,瞬时状态(临时状态):Transient Object
对象和数据库的数据没有关联,并且没有和框架关联在一起。例如,我们刚刚 new User();
2,持久化状态:Persistent Object
对象和数据库的数据存在关联,并且和框架关联在一起。例如我们刚刚进行保存的session.sava(user);
3,游离状态(离线状态,托管状态)Detached Object
对象和数据库的数据存在关联,但是和框架没有关联。例如保存后session关闭的user。
看一下三种状态POJO对象的转换吧:
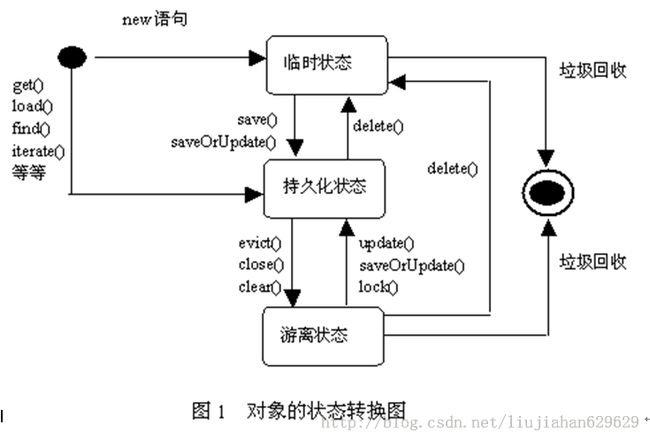
三,Hibernate,对三种状态下的POJO的增删改查操作:
|
|
瞬时状态 |
持久化状态 |
游离状态 |
| 增(Save) |
可以 |
不可以(没必要) |
不可以(没必要) |
| 改(Update) |
不可以 |
修改后会自动更新,不需手动 |
可以 |
| 删(delete) |
不可以 |
可以 |
可以 |
| 查 |
不可以 |
可以 |
可以 |
1,保存(Save):
通过session.save(user);就可以保存数据了,但是这里想提一下,主键的生成策略不同,框架发送sql语句的时间是不同的:
a,native:在调用save方法时发送insert语句。
b,uuid主键生成策略和assigned主键生成策略:在提交事务时发送insert语句。
这是因为主键的生成时机不同,由于native是在数据库中生成的,所以发送的比较早。
2,更新(Update):
这里想说一下对游离对象的更新:
|
|
uuid |
assigned |
native |
| 存在记录 |
发送upate语句 |
会查询判断,再更新 |
发送update语句 |
| 记录不存在 |
发送语句,剖异常 |
会查询判断,进行插入操作 |
发送语句,剖异常 |
3,删除(delete):
这里只要提供主键,可以根据主键id删除,只要id存在即可。
4,查询:
a,主键查询:
get:返回结果可能是:持久化对象或null,所以需要对结果进行非空判断。它利用了缓存,是立即查询。
//get方法查询如果成功,那么返回的对象状态是持久化状态
Objectobj = session.get(User.class, "admin");
load:返回结果可能是:持久化对象或cglib代理对象或异常,利用缓存,默认为延迟加载。
//load方法第一查询结果存放到缓存中,支持延迟加载,效率更高,但是主要
Objectobj = session.load(User.class, "admin");
b,普通查询(面向对象查询):后边会介绍
1,Query:HQL (HibernateQuery Language),HQL语言是对SQL语言的封装,是面向对象的查询语言。例如:SQL : select * from t_user(表名) whereusername(字段)="tom"
HQL : from User(类名) where username(属性)="tom"
- //分页查询
- String hql = "from User u "; //面向对象查询 HQL!!!!!
- Query query = session.createQuery(hql);
- int pageno = 3 ;
- int pagesize = 2 ;
- int index = (pageno - 1) * pagesize ;
- query.setFirstResult(index);//某页的第一个下标
- query.setMaxResults(pagesize); //页数的大小
- //条件查询
- String hql = "from User u where u.usercode=? and u.userpswd=?"; //面向对象查询 HQL!!!!!
- Query query = session.createQuery(hql);
- query.setString(0, "admin"); //索引从0开始
- query.setString(1, "admin");
2, Criteria:将所有的操作都以面向对象的方式进行完成。
- //分页查询
- Criteria cra = session.createCriteria(User.class);
- cra.setFirstResult(0); //开始索引
- cra.setMaxResults(2); //每页数量
- //排序
- Criteria cra = session.createCriteria(User.class);
- cra.addOrder(Order.desc("username"));
- //条件查询
- Criteria cra = session.createCriteria(User.class);
- cra.add(Restrictions.eq("username", "aaa"));
- cra.add(Restrictions.eq("usercode", "aaa"));
综上为Hibernate对POJO对象的简单操作,主要是做好映射,简单的配置,然后利用Hibernate里边的方法进行配置。这里这是举了几个简单的例子涉及的知识较少,我们可以查看Hibernate的帮助文档中进行查看参考,会帮助我们很多的