Apple新发布的APFS文件系统对用户意味着什么
2016年WWDC大会上,Apple除了公布watchOS、tvOS、macOS以及iOS等一系列系统和软件更新外,还公布了一个名为APFS(Apple File System)的文件系统。
这一全新文件系统专门针对闪存/SSD进行优化(但依然可用于传统机械硬盘),提供了更强大的加密、写入时复制元数据、空间分享、文件和目录克隆、快照、目录大小快速调整、原子级安全存储基元,以及改进的文件系统底层技术,将全面应用于该公司旗下所有设备中。
为什么不继续使用HFS+?
HFS诞生于1985年,随后在1998年发布的4GB硬盘版本G3 PowerMac中引入了改进的HFS+文件系统。从1998年4GB容量的传统HDD机械硬盘,到现在TB规模的SSD固态硬盘,HFS+已经招架不住存储领域的大量改变和创新。
经过长期发展,HFS+针对不同类型的设备衍生出不同功能的多种分支,但它毕竟太老、太混乱了。更重要的是,该文件系统不具备当今大多数企业所需要的一些基本功能,例如纳秒级时间戳、校验、快照、稀疏文件等。Apple生态圈急需一种能够取代HFS+的全新文件系统。
APFS应运而生!在解决HFS面临的各种遗留问题同时,还对HFS的所有变体进行了统一,这是Apple从底层代码开始从零打造的全新文件系统。
APFS概述
全新开发的APFS除了支持HFS+的全部功能外,还在以下方面有了突出的改进:
- 与使用32位文件ID的HFS+不同,APFS可支持64位索引节点(Inode)编号,借此一个卷最多可存储超过900亿亿个文件。
- HFS+只能同时对整个存储设备的文件系统进行初始化,APFS提供了一种可扩展存储块分配程序(Extensible block allocator),可对数据结构进行延迟初始化(Lazy initialization),进而大幅改善大容量卷的性能。
- APFS支持三种模式的加密:不加密;适用于元数据和用户数据的单密钥加密;以及适用于元数据、文件,甚至文件中特定部分的多密钥加密。
此外APFS还包含其他改善和新功能,例如稀疏文件、改进的TRIM操作,内建对扩展属性的支持等。
脱胎换骨的APFS已经具备与BSD HAMMER、Linux btrfs,或OpenZFS等现代化文件系统不相上下的功能和特性。
数据加密
安全与隐私是APFS的设计基础。Apple的很多设备和操作系统早已具备加密功能,OS X 10.7 Lion开始提供全磁盘加密功能;iOS 4开始可通过专用数据保护技术将每个文件使用一个专用密钥进行加密。APFS对这两种功能进行整合,为文件系统元数据提供了一种统一的加密模式。
加密是APFS原生支持的特性,用户可以针对每个卷选择下列任何一种加密方法:不加密,统一用一个密钥加密,或多密钥加密(针对每个文件使用专用密钥加密,同时针对敏感的元数据使用一个单独的密钥)。多密钥加密可确保哪怕设备物理安全受到威胁,依然可以保障用户数据的完整性。取决于具体硬件,APFS加密可使用AES-XTS或AES-CBC算法。
这种加密机制还实现了一个额外的功能:更为快速的数据擦除。通常情况下当用户从设备中删除文件后,可以通过市面上提供的很多(免费或收费的)反删除软件找回删掉的内容。为避免这种情况,以往如果需要删除包含机密信息的文件,或需要将存储过私密数据的设备退役给他人使用,必须首先使用抹掉功能擦除存储设备,并可能要将这一过程执行多遍。取决于存储设备容量,整个过程将耗费极多时间。
对于使用APFS文件系统的存储设备,在启用加密功能后,安全擦除的过程将变得大为简便和快捷,不再需要耗费大量时间多次给存储设备填充随机数据,只需要删除加密所用的密钥即可。
快照和备份功能
快照功能可将文件系统的状态“固定”在创建快照的那一刻,并可在保留固定状态的同时继续访问和修改文件系统。这种技术可以只记录新增或改动的数据块,因此可以为文件系统创建多个快照,而无需担心会占用大量存储空间。备份工具(例如Time Machine)通常会使用该功能记录自从上次备份之后文件系统的改动情况,并可用于在不打断用户操作的前提下对数据进行更为高效的备份。

由于不支持目录硬链接,APFS暂不兼容Time Machine,希望以后APFS能够针对Time Machine提供更高效的序列化机制。本届WWDC上,APFS的开发经理Eric Tamura在演示APFS的快照功能时使用了一个尚未包含在Beta版macOS Sierra中的工具,同时根据Apple的介绍,目前尚未提供用于访问快照功能的API,期待在后续版本中这个技术能够尽快完善起来。
空间共享
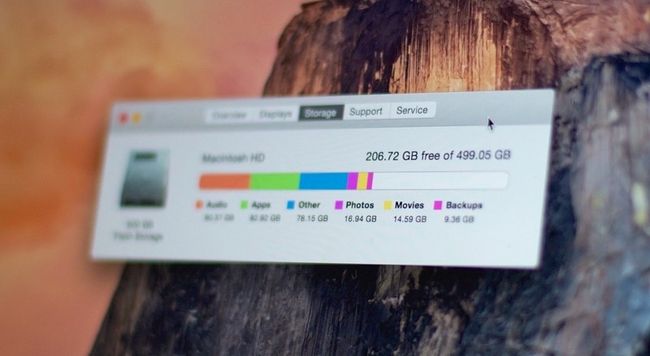
APFS包含一个名为“空间共享”的新功能,借助该功能,多个文件系统可以共享同一个物理卷上的同一块底层可用空间。也就是说,设备上的一个APFS“容器”内部可以包含多个“卷”(文件系统)。HFS+需要为每个文件系统预先分配固定大小的容量,这种做法较为“僵硬”,而APFS的空间共享功能可以让用户在无需重分区的情况下动态、灵活地扩大或缩小卷容量。
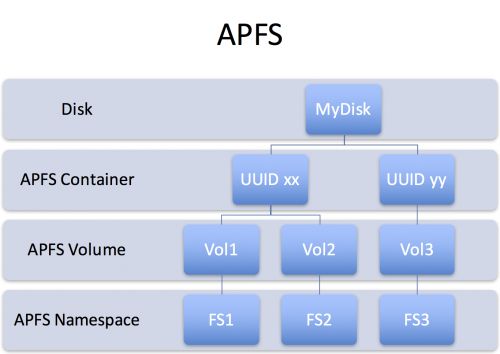
在这样的设计下,APFS容器内的每个卷都会显示同等的可用空间容量,而所显示容量会等同于该容器的可用存储空间总量。例如,假设有个容量100GB的APFS容器,其中包含已用10GB容量的卷A和已用20GB容量的卷B,卷A和卷B都会显示自己有70GB(100GB-10GB-20GB)的可用容量。
存储空间使用效率
现代化的文件系统往往会通过压缩和去重(Deduplication)等方式减小文件占用的空间量。压缩很好理解,去重是指找出大量文件中相同的数据块,并只将这样的块存储一次,在访问文件时,会根据实际情况动态“拼装”出最终的文件。这样的功能最适合保存大量用户文件或大量虚拟机映像的服务器环境。
APFS可以用恒定的速度对多个文件和目录创建副本。举例来说,如果要在同一个文件系统(或同一个容器)内部复制文件,实际上并不需要为数据创建副本,只需要对文件的元数据进行适当的更新就可以让磁盘上存储的数据实现“共享”,此时相同的文件“实际体积”不变,但产生了两个副本,对任何一个副本进行改动则需要为其分配新的存储空间(这种方式也叫做“写入时复制”)。
文件基本可以分为下列三种类别:
- 每次需要全面覆盖的文件,例如图片、Office 文档、视频等
- 可以“附加”新内容的文件,例如日志文件
- 使用基于记录结构的文件,例如数据库文件
对大部分普通用户来说,接触最多的可能就是第一种文件。在APFS的帮助下,可以将文档(例如体积为10MB)复制多次,并借助空间共享功能节约存储空间的用量,但只要改动过其中任何一个副本,就需要为这个副本分配10MB空间。
这样的“克隆”有可能给用户造成一定的困扰。既然复制的文件不占用空间,那删除这些文件也不会释放出空间。
另外还需要注意一点:在Finder内复制文件会产生这样可以节约空间的“克隆”,但命令行中的cp命令还会使用以往的方式为文件创建完整的副本。
性能
APFS专门针对闪存进行了优化。SSD虽然可以模拟传统机械硬盘的“块”,但底层技术与机械硬盘截然不同。SSD底层的管理工作是由一种名为闪存转换层(FTL,Flash Translation Layer)的软件负责处理的。FTL与文件系统极为类似,可以在块地址和介质内部的位置之间创建虚拟映射(转换)。整个堆栈,包括SSD、FTL,以及文件系统都由Apple控制,可以更有针对性地对不同组件进行优化。
此外APFS还提供了对TRIM的支持。TRIM是ATA协议中的一个命令,可以让文件系统告诉SSD(其实是指示SSD中的FTL)某些空间是空闲的。可用空间越多,SSD的性能表现会越好,甚至大部分SSD所拥有的存储容量会超过标称值。
举例来说,假设有一个1TB容量的SSD,显示的可用空间总量为931GB。在有更多可用空间的情况下,FTL可以牺牲空间利用率换回更高性能和更长寿命。但TRIM的问题在于,只有在存在可用空间的情况下这个功能才会有用,如果磁盘即将装满,TRIM不会为你带来任何效果。
性能方面,APFS的延迟也有了大幅改善。APFS可以通过I/O QoS(服务质量)对不同的访问请求划分优先级,将用户可以立刻察觉的操作和后台活动区分对待。
数据完整性
确保数据完整性,可以说这是任何文件系统的首要目标。我把数据交给你,你别弄丢了,也别随意修改。但如果这一切真的能实现,我们又为什么要“备份”呢?为确保数据安全,文件系统通常会采取一系列机制。
冗余
大部分Apple设备只有一个存储设备(即一个逻辑SSD),因此RAID之类的做法毫无意义。此时冗余是通过更底层的组件实现的,例如Apple RAID、硬件RAID控制器、SAN,甚至“单一”存储设备本身。
但是也要注意,大部分可支持APFS的Apple设备中的SSD实际上是由多个或多或少相互独立的NAND芯片组成的。一些高端SSD会在内部实施一定的数据冗余,但需要付出容量和性能双双降低的代价。
此外APFS使得“复制文件”这一用户最常用的实现本地数据冗余的方法也失去了作用。APFS中复制的文件实际上只是对文件创建了轻量级克隆,实际数据并没有重复保存,底层设备的故障会导致所有“副本”受损。
绝对一致性
计算机系统在任何时候都可能出故障:崩溃、Bug、断电等…… 文件系统必须能够预见到这种情况并从故障中顺利恢复。遇到这种情况,以前可能需要尝试着用专门的工具在系统启动前检查并修复文件系统(例如使用fsck)。较为现代化的系统会使用某些“始终一致”的格式,或将不一致的可能尽量降低,以避免耗费大量时间执行完整的fsck检查。例如ZFS就可以在磁盘上构建一个新状态,然后通过一次原子操作从之前的状态以原子级方式过度到新状态。
覆盖写入数据是最容易造成不一致的操作。如果文件系统需要覆写文件的多个区块,有一定可能遇到一些区块已经代表新状态,但一些区块依然代表旧的状态。为避免这种问题,可以使用上文提到的写入时复制这一方式,首先分配新区块,随后释放旧区块使其可被再次使用,而不需要就地修改数据。APFS实施了一种“全新的写入时复制元数据体系”,这种方式的新颖之处在于,APFS并未使用ZFS机制复制已更改用户数据的所有元数据,只需要对文件系统结构进行一次原子更新即可实现。
校验
校验是一种针对数据进行的摘要会汇总,可用于检测(和纠正)数据错误。APFS会对自己的元数据,而非用户数据进行校验。这种对元数据进行校验的做法理由非常充分:大部分元数据都与用户数据无关(因此校验不会耗费太多存储空间),而丢失元数据会有极大可能造成用户数据的丢失。距离来说,假设某个顶层目录的元数据出错,那么磁盘上的所有数据都有可能无法访问。也正是因此,ZFS会对元数据创建副本(甚至对顶层元数据创建三重副本)。
但是完全不对用户数据进行校验,这种做法似乎更有趣。WWDC上的APFS工程师称,Apple设备的存储具备强大的ECC纠错保护。NAND闪存SSD和磁介质机械硬盘都可以使用冗余数据检测和纠正错误。Apple工程师认为,Apple设备通常不会遇到数据错误。NAND会使用额外的数据,例如每4KB页使用额外的128字节数据,借此检测和纠正数据错误。设备本身的误码率已经足够低,可以认为设备整个生命周期内都不会出现错误。还有一些设备错误可以通过文件系统的冗余机制避免。SSD中包含大量组件,而大部分消费类产品中的SSD很少包含端到端的ECC保护,因此可能导致数据传输过程中出现错误。SSD固件中也可能包含导致数据丢失的Bug。
Apple对于供应商的设备质量测试可能是最严格的,用户可以相信Apple产品使用了最高质量的组件。Apple工程师认为,此类设备的用户无需担心比特衰减(Bit Rot,逐渐老化的数据会慢慢丧失完整性)的问题,但如果软件本身无法检测错误,用户当然不知道设备的具体情况如何。价值数百万美元的存储阵列所用的ZFS也可能出现数据错误,那么Apple设备中所用的TLC NAND芯片(最便宜的NAND芯片类型)凭什么就不会出错?别忘了就在不久前某些大容量iPhone 6才刚刚因为存储问题而召回。
总结
Apple是否能完全用APFS取代HFS+,这一点还不确定,不过他们很可能已经到了这样一个转折点:继续维护并改进过了“而立之年”的软件,这样的做法可能比全新开发一套新的软件成本更高。APFS就是这样一种权衡之后的产物。
根据Apple在WWDC上的介绍,APFS的核心设计目标可能是这样的:
- 让所有消费者(笔记本、手机、手表等)满意
- 将数据加密作为头等要务
- 为现代化备份方式提供快照功能
这些目标可以让所有Apple用户获益,从WWDC上的演示可知,APFS似乎已经开始逐渐走上正轨(尽管测试版的macOS Sierra似乎还有一段路要走)。
APFS开发文档中针对“开源”有一个小注解:“开源的实现目前尚不可用”。其实很多人并不指望APFS能够开源。但如果APFS能够成为世界领先的文件系统,用户肯定还是希望在Linux和FreeBSD中也能使用,也许到时候Microsoft也能停止在ReFS方面的研发。APFS不针对用户数据进行校验,没有提供数据冗余机制,这些确实让人感觉遗憾,毕竟数据完整性应该是任何文件系统的头等要务,而无论这样的文件系统将用于手表或手机,或者服务器,文件完整性问题都应该重视起来。
目前APFS已经以开发者预览版的方式通过OS X 10.12(macOS Sierra)提供给用户,预计将在2017年正式发布。
若要尝试该功能,可在升级至macOS 10.12后通过新增的hdiutil命令行工具创建APFS卷:
$ hdiutil create -fs APFS -size 1GB foo.sparseimage
目前的测试版APFS有一些局限:
- 无法用于启动磁盘。
- 文件和目录名称大小写敏感。
- 无法用于Time Machine、FileVault或Fusion驱动器。
- 现有第三方工具需要更新才能支持APFS。
- APFS文件系统的卷无法被OS X 10.11 Yosemite以及更早的版本识别。
- APFS卷可以通过SMB网络文件共享协议共享,AFP协议已弃用,无法用于共享APFS卷。
感谢魏星对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至[email protected]。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。